
نموذجان أفضل من واحد لفهم الفيديوهات
الخميس، 04 يونيو 2026

راقب شخصاً يحاول تذكّر المكان الذي ترك فيه مفاتيحه، وسترى عملية البحث وهي تجري أمامك، حيث تتحرك عيناه في أرجاء المطبخ، ثم تعودان إلى الطاولة، ثم تنتقلان نحو علاقة المعاطف. فالتذكّر ليس عملية إدراك واحدة، بل حلقة متكررة تتولى فيها آلية سريعة مهمة البحث، بينما يتولى نظام أبطأ خلف العينين تحديد المكان الذي ينبغي البحث فيه في المرحلة التالية.
تقدم دراسة بحثية جديدة عرضها باحثون من جامعة محمد بن زايد للذكاء الاصطناعي خلال مؤتمر الرؤية الحاسوبية والتعرف على الأنماط لعام 2026 نظاماً اسمه “SpecTemp” قد يشكل نموذجاً مناسباً لفهم الفيديو من خلال اتباع أسلوب مشابه لطريقة البحث عند الإنسان.
تتلخص طريقة عمل الجيل الحالي من النماذج الكبيرة متعددة الوسائط القادرة على مشاهدة مقطع فيديو والإجابة عن أسئلة تتعلق به في تقسيم الفيديو إلى عدد كبير من الإطارات التي يجري تمريرها عبر محوّل كبير واحد يتولى مهمتي الرؤية والتفكير معاً. وتحقق هذه الطريقة نتائج مثيرة للإعجاب، لكنها مكلفة أيضاً. ويرى مؤلفو الدراسة حول نظام “SpecTemp” أن جزءاً كبيراً من هذه التكلفة يُهدر دون فائدة حقيقية.
لإثبات ذلك، حلل الباحثون أحد النماذج الشائعة لفهم الفيديو، ودرسوا كيفية تفاعل عناصره اللغوية (المسؤولة عن الاستدلال الفعلي) مع عناصره البصرية (التي تمثل ما شاهده النموذج). وأظهرت النتائج توزيعاً غير متوازن إلى حد كبير، حيث يحصل نحو 90% من العناصر البصرية على درجات انتباه تقل عن واحد بالألف، ما يعني أن النموذج يركز اهتمامه الحقيقي على جزء صغير فقط مما يعالجه، بينما تمثل بقية العناصر عبئاً حسابياً يستهلك الموارد من دون مساهمة تذكر في النتيجة النهائية.
وقد أدرك الباحثون العاملون في مجال النماذج اللغوية الكبيرة منذ بعض الوقت أن العناصر اللغوية لا تسهم جميعها بالقدر نفسه في عملية المعالجة. ومن هذه الفكرة نشأ مجال بحثي كامل يُعرف باسم “فك الترميز التكهني”. تقوم الفكرة على استخدام نموذج صغير وسريع للتنبؤ بعدة عناصر لغوية تالية، ثم الاستعانة بنموذج أكبر وأبطأ للتحقق من صحة هذه التنبؤات فقط. في معظم الحالات تكون توقعات النموذج الصغير صحيحة، فيتم التحقق منها بسرعة، ولا يضطر النموذج الكبير إلى تنفيذ عملية التوليد البطيئة وفق أسلوب عمله المعتاد. أما إذا أخطأ النموذج الصغير، فيتدخل النموذج الكبير لتصحيح المسار. وبذلك لا تُستدعى القدرات الحسابية المكلفة إلا عند الحاجة إليها.
ينقل نظام “SpecTemp” هذا المبدأ من مجال توليد الكلمات إلى مجال إدراك محتوى الفيديو. ففي البنية التي يقترحها الباحثون، يتولى نموذج كبير يضم سبعة مليارات معامل مهمة الاستدلال. ويبدأ هذا النموذج بالنظر إلى مجموعة صغيرة من الإطارات المختارة من الفيديو على فترات منتظمة، ثم يدرس السؤال المطروح ويقرر ما إذا كانت لديه أدلة بصرية كافية للإجابة عنه. وإذا لم تكن الأدلة كافية، فإنه يحدد مقطعاً زمنياً من الفيديو يبدو جديراً بمزيد من الفحص، ثم يحيله إلى نموذج أصغر يضم ثلاثة مليارات معامل. ويتولى هذا النموذج الأصغر تحليل ذلك المقطع من خلال أخذ إطار واحد في الثانية، ثم اختيار إطارين أو ثلاثة يراها الأكثر أهمية من حيث المعلومات التي تحتويها. وبعد ذلك تُعاد هذه الإطارات إلى النموذج الكبير، الذي إما أن يعطي الإجابة أو يطلب جولة إضافية من البحث. ويمكن أن تتكرر هذه الحلقة حتى ثلاث مرات.
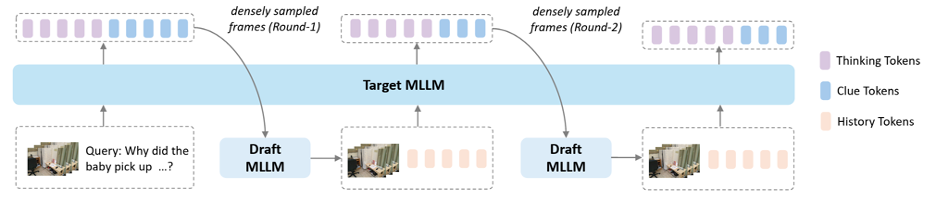
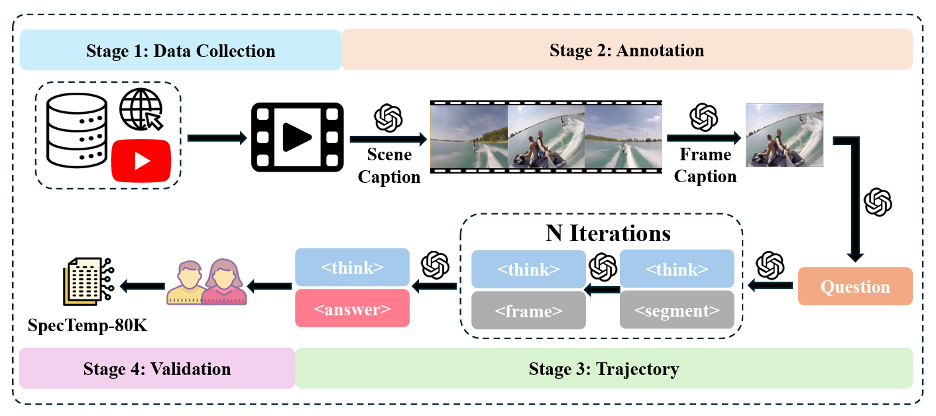
جرى اختبار هذا النظام على ثماني مجموعات بيانات معيارية تضم مقاطع فيديو قصيرة وأخرى تمتد إلى نحو ساعة كاملة. وأظهرت النتائج انخفاضاً في زمن الاستدلال بنسبة تقارب 20% من دون أي تراجع في الدقة، بل مع تحقيق تحسين محدود في عدد من المهام المرتبطة بمقاطع الفيديو الطويلة. كما أثبت النظام قدرته على منافسة نماذج أساسية أكبر بكثير تعالج 64 إطاراً دفعة واحدة، رغم أنه يعتمد على عدد أقل من الإطارات ويصل إلى الإجابة عبر آلية عمل أكثر انتقائية. ويعكس مسار التدريب هذا التعقيد، حيث اعتمد الباحثون على مجموعة بيانات مخصصة تضم 80 ألف مقطع فيديو مع شروح بمستويين مختلفين من التفاصيل، إلى جانب الضبط الدقيق الخاضع للإشراف لكلا النموذجين، ثم مرحلة من التعلّم التعزيزي تهدف إلى تعليمهما كيفية التعاون فيما بينهما.
في السنوات الأخيرة، اتجهت الطريقة السائدة في مجال فهم الفيديو إلى توسيع نافذة السياق، وتمرير عدد أكبر من الإطارات عبر النموذج نفسه، والاعتماد على زيادة الحجم لحل المشكلات المتبقية. أما الباحثون الذين اقترحوا النظام “SpecTemp” فيسيرون في الاتجاه المعاكس. فهم ينطلقون من أن الإدراك والاستدلال مهمتان مختلفتان لكل منهما متطلبات حسابية مختلفة، وأن أفضل طريقة لتحقيق الأداء المطلوب في كليهما هي إسناد مهمة المسح السريع إلى نموذج صغير متخصص، بينما يتولى نموذج أكبر وأقل تخصصاً تفسير ما تكشفه عملية المسح.
يستند الباحثون في هذا الطرح إلى نتائج حديثة في علم الأعصاب تشير إلى أن المعالجة الحسية لدى الإنسان تتم عبر مسارين متوازيين: مسار سريع لاستكشاف المشهد بصورة أولية، ومسار أبطأ يتولى الدمج والتحليل وإصدار الأحكام. وإذا كانت غالبية العناصر البصرية في مهمة استدلال حول محتوى مقطع الفيديو لا تسهم إلا بدرجة ضئيلة جداً في الوصول إلى الإجابة، فمن المنطقي التوقف عن تمريرها كلها عبر النموذج الأعلى تكلفة من الناحية الحسابية.
يتطلب تدريب هذا النظام استخدام نموذجين بدلاً من نموذج واحد. كما تُعتبر مرحلة التعلّم التعزيزي كثيفة الاستهلاك للموارد. وقد جرى اختبار النظام على مقاطع فيديو تصل مدتها إلى نحو ساعة واحدة. أما أداؤه على محتوى يمتد لساعات طويلة، حيث يتضاعف عدد المقاطع الزمنية المحتملة بصورة كبيرة، فما يزال سؤالاً مفتوحاً يحتاج إلى مزيد من الدراسة.
هل يمكن تعميم هذه الطريقة القائمة على نموذجين؟ لقد أصبح فك الترميز التكهني في عالم النماذج اللغوية أشبه ببنية أساسية معتمدة على نطاق واسع. وإذا ثبت أن الفكرة نفسها قابلة للتطبيق في مجال الإدراك أيضاً، فقد لا يكون مستقبل الأنظمة الكبيرة متعددة الوسائط قائماً على نموذج واحد ضخم يتولى كل شيء، بل على فريق صغير من النماذج المتعاونة التي تؤدي أدواراً مختلفة: نموذج يتولى الاستكشاف وآخر يضع الاستراتيجية، أو نموذج يعمل كمساعد بحثي وآخر كمحقق، أو حتى مساران متوازيان يؤدي كل منهما وظيفة مختلفة.
ترسم الدراسة البحثية صورة لنموذج لفهم الفيديو تعلم أخيراً كيف ينظر بالطريقة التي ينظر بها الإنسان. فهو يبدأ باستكشاف المشهد بسرعة لتكوين صورة أولية، ثم يعود إليه بنظرة فاحصة تركز على المواضع التي قد توجد فيها الإجابة. هذا لا يعني بالضرورة أن النموذج أصبح أكثر ذكاءً، بل يبين أنه صار أكثر كفاءة في توجيه انتباهه إلى ما يستحق المعالجة فعلاً. وفي مجال يُعد فيه الانتباه عنق الزجاجة الحقيقي، تكتسب الكفاءة أهمية أكبر.
أخبار ذات صلة

تطوير ذكاء اصطناعي يفهم التحديات المناخية في الخليج
طور فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي إطاراً جديداً يحمل اسم "المساعد الذكي للمناخ.....
- ACL ,
- conference ,
- climate change ,
- computer vision ,
- research ,

باحثون في جامعة محمد بن زايد للذكاء الاصطناعي يطورون إطاراً جديداً يعزز موثوقية النماذج متعددة الوسائط
باحثون من جامعة محمد بن زايد للذكاء الاصطناعي يكشفون عن إطار عمل جديد سيمكن النماذج متعددة الوسائط.....
- المؤتمرات ,
- النماذج متعددة الوسائط ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

من "الوسم الثابت" إلى "التشفير المتغير": مقاربة جديدة لتوثيق الفيديوهات المولَّدة آلياً
فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي ينجح في تطوير نظام لتوليد العلامات المائية، قد.....
- العلامة المائية ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- البحوث ,
- الأمن ,
- الرؤية الحاسوبية ,
- المؤتمرات ,