
نهج جديد لتكييف نماذج الرؤية الحاسوبية مع الصور الطبية
الثلاثاء، 02 يونيو 2026
نادراً ما تكون أول صورة يراها فني التصوير بالموجات فوق الصوتية للأجنة على الشاشة مماثلة للرسم الواضح الذي يظهر في الكتب الدراسية. فعادة ما تكون مزيجاً من البقع الرمادية المشوشة تتخللها ظلال صوتية للجمجمة التي في طور النمو، مع ملامح جسم صغير تظهر جزئياً وسط التشويش، ووضعية تتغير كلما تحركت الأم.
تُعد قراءة هذه الصور بدقة مهارة تتطلب سنوات طويلة. أما بناء نموذج ذكاء اصطناعي قادر على قراءتها بكفاءة، من دون أن يفقد قدرته على “الرؤية” في أنواع الصور الأخرى، فهو تحدٍ يواجهه العاملون في مجال الرؤية الحاسوبية منذ ما يقرب من عقد من الزمن.
في هذا السياق، تطرح دراسة بحثية متميزة قدمها فريق من الباحثين في جامعة محمد بن زايد للذكاء الاصطناعي خلال مؤتمر الرؤية الحاسوبية والتعرف على الأنماط “CVPR 2026” بنية جديدة اسمها “DCRM-ViT”، وتقترح نهجاً لمعالجة بعض هذه الإشكالات. ويتناول البحث تحدياً معروفاً في هذا المجال: فعندما يُجرى الضبط الدقيق لنموذج قوي للرؤية الحاسوبية باستخدام الصور الطبية، فإنه يميل إلى فقدان جزء من قدرته على فهم صور أخرى، مثل صور الكلاب أو السيارات. وفي المقابل، عندما يُدرَّب النموذج على نطاق واسع ومتنوع، فإنه يواجه صعوبة في التعامل مع الصور الطبية الحقيقية. وقد أسهمت هذه المفاضلة في تشكيل مسار هذا المجال، وأدت إلى ظهور منظومتين متوازيتين من النماذج نادراً ما تجتمعان في تطبيق واحد.
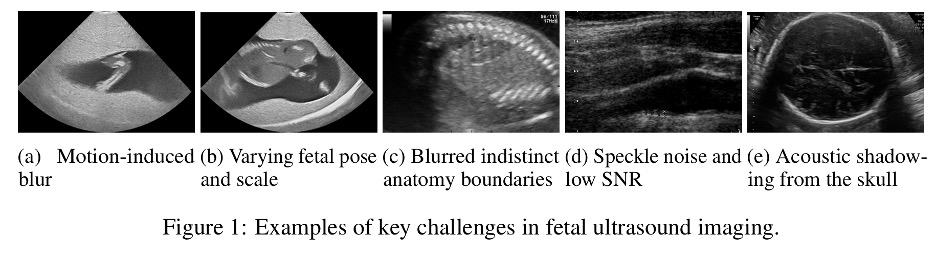
ترى الباحثة الرئيسة أفق خان، التي أعدّ هذه الدراسة تحت إشراف الدكتور محمد حارس خان، الأستاذ المساعد في قسم الرؤية الحاسوبية بجامعة محمد بن زايد للذكاء الاصطناعي، وبمشاركة طالب الدكتوراة عمير نواز، أن هناك طريقة لتجاوز هذا الخيار الثنائي. ويشير الباحثون إلى أن الاختلاف بين صورة دماغ ملتقطة بالرنين المغناطيسي، وصورة بالموجات فوق الصوتية لبطن جنين، وصورة لطبق طعام، هو تباين تدريجي على طيف متصل، وليس اختلافاً بين فئات منفصلة تماماً. وإذا كان الأمر كذلك، فإن الطريقة المثلى للتعامل مع هذه الاختلافات ينبغي أن تكون تدريجية أيضاً من خلال إجراء تعديلات صغيرة خاصة بكل صورة بدلاً من إعادة تدريب النموذج بالكامل.
لتحقيق ذلك، استخدم خان وفريقه نموذج محول رؤية مُدرَّباً مسبقاً وأبقوه دون تعديل. فالأوزان الأصلية للنموذج، التي اكتسب من خلالها قدراته البصرية العامة من ملايين الصور الطبيعية، لا يجري تحديثها مطلقاً. وبدلاً من ذلك، أضاف الباحثون طبقة خفيفة جديدة تنظر إلى كل صورة واردة وتحدد كيفية تعديل حسابات الشبكة بصورة طفيفة. وأطلقوا على هذه الطبقة اسم “موجّه المجالات”. وهي تضع احتمالات مرنة تحدد ما إذا كانت الصورة أقرب إلى الصور الطبية أم إلى الصور الطبيعية، ثم تمرر هذه الاحتمالات إلى شبكة توليد المعاملات، وهي شبكة صغيرة تُنشئ تعديلات طفيفة بصورة فورية. وتُدرج هذه التعديلات في نقاط محددة داخل كل كتلة من كتل المحوّل، بحيث تعدّل الطريقة التي يقيّم بها النموذج السمات المختلفة للصورة دون الحاجة إلى إعادة كتابة الأوزان الأساسية أو تعديلها.
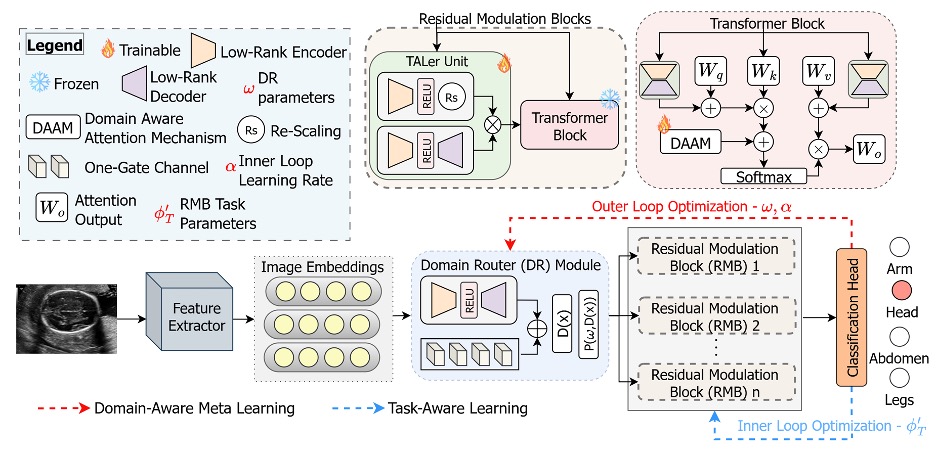
يشبه أثر هذه الطريقة تركيب مفتاح تحكم تدريجي في شدة الإضاءة مكان مفتاح التشغيل والإيقاف التقليدي. فالصورة التي تقع في منطقة وسطى بين صورة فوتوغرافية واضحة وصورة موجات فوق صوتية مليئة بالتشويش، مثل صورة الثدي الشعاعية التي خضعت لمعالجة مكثفة، يمكن أن تخضع لتعديل متوسط. ويطلق الباحثون على هذه التعديلات اسم “التعديل التصحيحي”، والوحدات التي تطبقها توجد داخل كل طبقة من طبقات المحوّل، وهي وحدات خفيفة بما يكفي للحفاظ على انخفاض تكلفة التدريب.
ولتدريب نظام التوجيه هذا، استعان الباحثون بطريقة تُعرف باسم التحسين ثنائي المستوى، وهي طريقة معروفة في أبحاث تعلّم عملية التعلم تعتمد على حلقتين متداخلتين تؤدي كل منهما وظيفة مختلفة. ففي الحلقة الداخلية، تُكيَّف وحدات التعديل التصحيحي بسرعة مع مهمة محددة، مثل التمييز بين صورة لرأس جنين وصورة لبطن جنين. أما الحلقة الخارجية، فتتولى تحديث موجّه المجالات نفسه، إلى جانب الحالة الابتدائية لوحدات التعديل التصحيحي، باستخدام أمثلة مختارة تساعد الشبكة على تعلّم الخصائص العامة لكل مجال. وكما يوضح الباحثون، فإن هذين الهدفين قد يتأثران سلباً إذا جرى تحسينهما معاً. فموجّه المجالات يحتاج إلى تعلّم طبيعة المجالات المختلفة، بينما تحتاج وحدات التعديل التصحيحي إلى تعلّم خصائص المهمة نفسها. وعندما يُدرَّبان معاً بالاعتماد على مشتقة واحدة، غالباً ما تكون النتيجة نموذجاً لا ينجح في أداء أي من المهمتين بالكفاءة المطلوبة.
أظهرت النتائج التي جرى الحصول عليها باستخدام مزيج من مجموعات الصور الطبية والطبيعية، أداءً مشجعاً. ففي تصنيف صور الموجات فوق الصوتية للأجنة، حقق النموذج “DCRM-ViT” دقة بلغت 63.4% على مجموعة البيانات “FPUS23”، و89.3% على مجموعة البيانات المعيارية “Fetal Planes”، متفوقاً على نماذج أساسية قوية مثل “CLIP” و “DINOv2” و “LoRA”. وفي مجموعات الصور الطبيعية مثل “Food101” و
“Stanford Cars”، حقق النموذج أداءً مماثلاً أو أفضل قليلاً من النماذج المتخصصة. أما في مهام تقسيم الصور، وهي من التطبيقات ذات الأهمية الطبية الكبيرة، فقد حقق تحسناً بنحو ثلاث نقاط في معامل دايس مقارنة بنموذج “SAMUS”، وهو نموذج حديث متخصص في صور الموجات فوق الصوتية، وذلك في مجموعات بيانات خاصة بالموجات فوق الصوتية للثدي. كما سجلت نتائجه في صور القلب الملتقطة بالتصوير المقطعي المحوسب والتصوير بالرنين المغناطيسي تفوقاً بفارق نقطتين تقريباً على أقوى النماذج المقارنة.
ومن اللافت أن الباحثين أفادوا بأن النموذج يتطلب 3.3 مليون معامل قابل للتدريب فقط فوق نموذج أساسي يضم نحو 87 مليون معامل، مع زمن تدريب يبلغ حوالي 0.3 دقيقة لكل دورة تدريب باستخدام وحدة معالجة رسوميات واحدة من نوع “A100”. ويُعد ذلك أقل بكثير من تكلفة الضبط الدقيق الكامل للنماذج التأسيسية، مما يعكس الإمكانات العملية الواسعة لهذا التصميم، حيث تستطيع المستشفيات والمختبرات التي لا تملك الموارد اللازمة للحفاظ على نماذج منفصلة لكل نوع من أنواع البيانات استخدام نموذج أساسي واحد ثابت، إلى جانب مجموعة صغيرة من معاملات التوجيه، مع إمكانية تعديل نظام التوجيه أو توسيعه دون التأثير في بقية مكونات النموذج.
ويقر الباحثون بأن موجّه المجالات في صورته الحالية يميز فقط بين المجالات العامة. فهو لا يفرق مثلاً بين صور القلب الملتقطة بالتصوير المقطعي المحوسب وصور البطن الملتقطة بالتقنية نفسها، رغم أن هذا التمييز قد يكون مهماً من الناحية السريرية. كما يشيرون إلى أن التقييم اقتصر على الصور الثنائية الأبعاد الثابتة. أما مقاطع الفيديو، حيث تصبح المحافظة على الاتساق الزمني مشكلة قائمة بحد ذاتها، فما تزال ضمن نطاق الأبحاث المستقبلية. كذلك، ورغم أن فكرة التعديل التصحيحي تبدو قابلة للتطبيق بصورة طبيعية على مهام التنبؤ الكثيف مثل اكتشاف المعالم، فإن هذا التوسع لم يخضع للاختبار بعد.
خلال السنوات الأربع الماضية، اتجهت أبحاث الرؤية الحاسوبية بصورة متزايدة نحو بناء نماذج أساسية أكبر حجماً وتدريبها على مجموعات بيانات أضخم، انطلاقاً من فرضية مفادها أن التوسع في الحجم وحده كفيل بتقليص الفوارق بين المجالات المختلفة. لكن نهج “DCRM-ViT” مغاير تماماً، فهو يفترض أن النموذج الأساسي يمتلك القدرات الكافية ولا يحتاج إلا توجيهاً ذكياً، أي إيجاد الحد الأدنى من التعديل اللازم لتحويل نموذج عام إلى نموذج متخصص خلال عملية استدلال واحدة فقط، ثم إعادته إلى حالته الأصلية بعد ذلك. وإذا أثبت هذا النهج فاعليته في الدراسات المستقبلية، فلن يلغي الحاجة إلى النماذج التأسيسية، لكنه قد يغيّر طريقة وصول هذه النماذج إلى المؤسسات الطبية.
ويثير البحث سؤالاً أعمق حول ما إذا كان الموجّه الذي يعتمد على التمييز بين الصور الطبيعية والصور الطبية فقط يمتلك مستوى الدقة الكافي ليكون مفيداً في البيئات الطبية على أرض الواقع. فصور الموجات فوق الصوتية الملتقطة بواسطة جهاز من شركة فيليبس في مستشفى بإسبانيا قد تختلف عن الصور الملتقطة بواسطة جهاز محمول في عيادة ريفية بطرق لا يمكن لتصنيف ثنائي بسيط أن يلتقطها. ومن المرجح أن تحتاج الإصدارات المستقبلية من هذا العمل إلى موجّه قادر على التفكير ضمن طيف متدرج من الاحتمالات بدلاً من الاكتفاء بفئتين متقابلتين. ومن المشجع أن البنية المقترحة تبدو مصممة لاستيعاب هذا التعقيد. فمفتاح التحكم التدريجي موجود بالفعل، وكل ما يحتاج إليه هو المزيد من مستويات الضبط.
أخبار ذات صلة

تطوير ذكاء اصطناعي يفهم التحديات المناخية في الخليج
طور فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي إطاراً جديداً يحمل اسم "المساعد الذكي للمناخ.....
- ACL ,
- conference ,
- climate change ,
- computer vision ,
- research ,

باحثون في جامعة محمد بن زايد للذكاء الاصطناعي يطورون إطاراً جديداً يعزز موثوقية النماذج متعددة الوسائط
باحثون من جامعة محمد بن زايد للذكاء الاصطناعي يكشفون عن إطار عمل جديد سيمكن النماذج متعددة الوسائط.....
- المؤتمرات ,
- النماذج متعددة الوسائط ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

نموذجان أفضل من واحد لفهم الفيديوهات
نجح فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي في تطوير نهج مبتكر لفهم مقاطع الفيديو،.....
- الفيديو ,
- النماذج متعددة الوسائط الكبيرة ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- البحوث ,
- المؤتمرات ,