
إطار عملي جديد لحماية خصوصية المرضى في عصر النماذج التأسيسية
الثلاثاء، 30 سبتمبر 2025

في الماضي، عندما كان المريض يسحب موافقته على استخدام بياناته، كانت تلك البيانات تُمحى ببساطة عن طريق حذف صف من قاعدة البيانات في التطبيقات البرمجية. أما اليوم، ومع بدء استخدام نماذج الذكاء الاصطناعي على نطاق أوسع في التطبيقات الصحية، أصبحت إزالة بيانات شخص من مجموعة البيانات أكثر تعقيداً، لأن النموذج يكون قد تعلّم بالفعل من تلك البيانات. لحل هذه المشكلة، طوّرت داريا تاراتينوفا وشهد حردان، الباحثتان في جامعة محمد بن زايد للذكاء الاصطناعي، طريقة عملية تجعل أنظمة الذكاء الاصطناعي تنسى ما تعلمته من تلك البيانات دون الحاجة إلى إعادة بناء النموذج بالكامل.
تعمد المستشفيات بشكل متزايد إلى تدريب نماذج الذكاء الاصطناعي على سجلات مرضى تضم بيانات متعددة الوسائط، مثل صور الأشعة السينية المصحوبة بتقارير أطباء الأشعة، بهدف الكشف المبكر عن الأمراض وتخصيص الرعاية. لكن ماذا يحدث عندما يطلب أحد المرضى (أو حتى مؤسسة بكاملها) حذف بياناته بعد تدريب النموذج؟ أصبحت الإجابة على هذا السؤال مسألة ملحة نتيجة لتشريعات مثل اللائحة العامة لحماية البيانات التي تنص على حق الفرد في حذف بياناته من قواعد البيانات العامة، وكذلك سياسات الاحتفاظ بالبيانات المستندة إلى قانون قابلية نقل التأمين الصحي والمساءلة، خاصة وأن الحذف وحده لا يكفي في ضوء بقاء أثر تلك البيانات من خلال ما تعلمه النموذج منها. ويزداد الأمر تعقيداً في الأنظمة متعددة الوسائط، لأن النماذج تتعلم العلاقات بين الصورة والنص بقدر ما تتعلم من كل منهما على حدة.
في هذا السياق، أعدت حردان وتاراتينوفا دراسة بحثية تقترحان فيها طريقة جديدة اسمها “نسيان المعلومات متعددة الوسائط”، ويُشار إليها اختصاراً باسم “Forget-MI”. وسيتم عرض هذه الدراسة في المؤتمر الدولي لحوسبة الصور الطبية والتدخل المدعوم بالحاسوب 2025 المقرر عقده في كوريا الجنوبية.
توضح الباحثتان الفكرة الأساسية التي تقوم عليها طريقة “Forget-MI” بالقول: “إذا طلب أحد المرضى حذف بياناته، فيجب أن يحذف النموذج كل أثر لتلك البيانات مع استمرار أدائه بكفاءة بالنسبة لباقي المرضى”. فالطريقة تنطلق من نموذج متعدد الوسائط مُدرّب مسبقاً ليُنتج نسخة معدلة تخلو من أي أثر لبيانات المرضى المحددين، وذلك دون الحاجة إلى إعادة التدريب بشكل كامل.
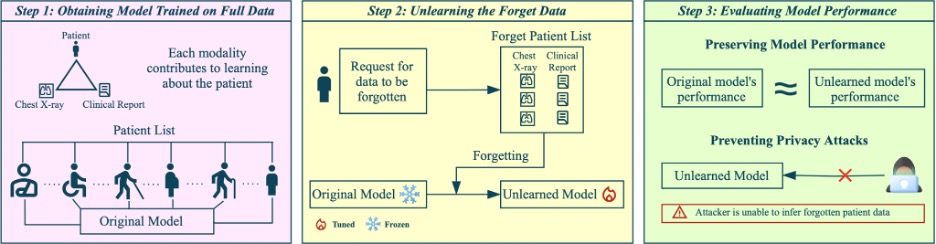
من حيث المبدأ، تعمل هذه الطريقة في اتجاهين في آن واحد، حيث تهدف إلى محو ما تعلمه النموذج من كل عنصر على حدة (الصورة والنص)، وكذلك الرابط بينهما، مع الحفاظ في الوقت نفسه على ما تعلمه من بيانات المرضى الآخرين بحيث تظل دقة النموذج الإجمالية مفيدة.
وللمهتمين بالجوانب الفنية، يعتمد الهيكل الأساسي للنموذج على مصنّف متعدد الوسائط قائم على الدمج المتأخر (حيث يُستخدم النموذج “ResNet” لمعالجة الصور، والنموذج “SciBERT” لمعالجة النصوص)، مع آلية تحكم في كيفية دمج الوسائط المتعددة لتكوين تمثيلات مشتركة.
ويكمن السر لتحقيق أداء جيد في ضبط أربع إعدادات مترابطة لحذف البيانات:
- محو ما تعلمه النموذج من البيانات الأحادية: إزالة تمثيلات الصور والنصوص الخاصة بالمرضى المطلوب حذف بياناتهم من المواضع التي وضعها فيها النموذج الأصلي.
- محو ما تعلمه النموذج من البيانات متعددة الوسائط: نسيان ما تعلّمه النموذج حول العلاقة بين صورة المريض وتقريره الطبي.
- إبقاء البيانات الأحادية: الحفاظ على بيانات بقية المرضى.
- إبقاء البيانات متعددة الوسائط: الحفاظ على الروابط بين الصورة والنص لبقية المرضى.
ولمنع بقاء أي أثر من بيانات المريض، تضيف طريقة “Forget-MI” قدراً ضئيلاً من التشويش (مثل تشويش جاوسي على الصور وتعديلات طفيفة على مستوى الحروف أو الكلمات في النصوص)، بحيث ينسى النموذج نطاقاً محيطاً بكل حالة، وليس مجرد تسلسل دقيق من البكسلات أو العبارات. وقد حرص الفريق على ضبط هذا التشويش بعناية، لأن الإفراط فيه يضر بقدرة النموذج على التعميم، وتقليله قد يؤدي لبقاء آثار من بيانات المريض.
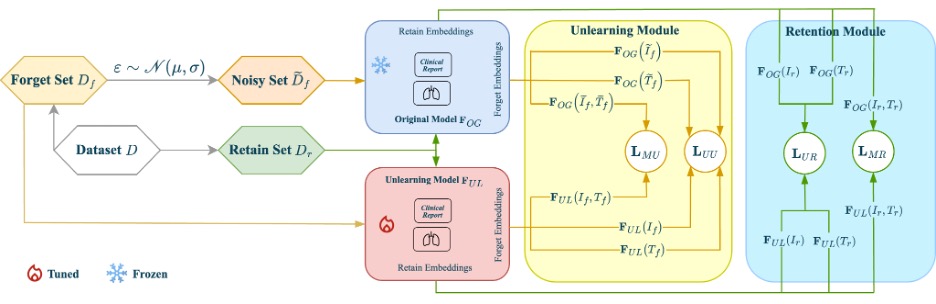
وهنا قد يسأل أحدهم: لماذا لا نكتفي بمحو الرابط بين الصورة والنص؟ تكمن الإجابة في تشابك التمثيلات التي تتعلمها النماذج متعددة الوسائط، حيث تؤثر الصورة في كيفية تمثيل النص، ويؤثر النص في كيفية تمثيل الصورة. لذلك تهدف طريقة “Forget-MI” إلى جعل النموذج ينسى ما تعلمه من كل عنصر على حدة وكذلك العلاقة بينهما.
كيف جرى اختبار الطريقة “Forget-MI” (ولماذا تُعد المقاييس مهمة)
استخدمت الباحثتان مجموعة فرعية منظمة من مجموعة البيانات “MIMIC-CXR” تضم 6,742 صورة أشعة سينية للصدر مع تقاريرها تعود إلى 1,663 مريضاً، وهي مصنّفة تبعاً لمراحل الوذمة الرئوية الأربعة (43% بدون وذمة، 25% مرحلة الاحتقان الوعائي، 22% المرحلة الخلالية، 10% المرحلة السنخية). كما أنشأتا مجموعات نسيان (مجموعات البيانات التي نريد محو ما تعلمه النموذج منها) تشمل جميع بيانات مرضى يمثلون نسب 3% و6% و10% من العينة بشكل يحاكي سيناريوهات واقعية في المستشفيات، بما في ذلك الحالات التي يكون فيها للمريض الواحد عدة صور وتقارير طبية.
تعتمد عملية التقييم على ثلاثة مقاييس رئيسية مترابطة:
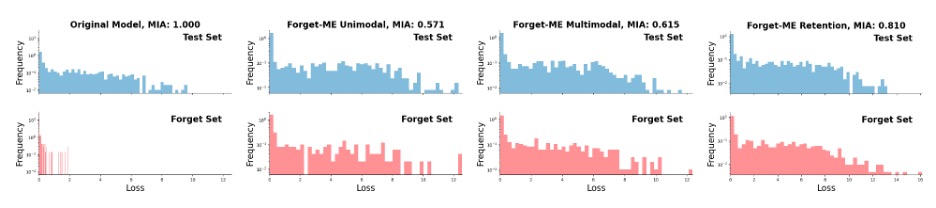
- هجوم استنتاج العضوية: هل يستطيع شخص خارجي معرفة ما إذا كانت بيانات مريض معيّن قد استُخدمت في تدريب النموذج؟ كلما انخفضت قيمة هذا المقياس كان ذلك أفضل، ويفضَّل ألا يمكن التمييز بين بيانات التدريب والبيانات الجديدة.
- الأداء على مجموعة النسيان: يجب أن تنخفض مقاييس مثل المساحة تحت المنحنى و”F1″ (وهو المتوسط التوافقي المرجّح بين الدقة والاسترجاع)، بحيث لا يبقى أداء النموذج جيداً على بيانات المرضى التي جرى حذفها.
- الأداء على مجموعة اختبار مستقلة: ينبغي أن يبقى الأداء قريباً من مستوى أداء النموذج الأصلي أو المعاد تدريبه، وإلا يكون الحل أسوأ من المشكلة نفسها.
أظهرت النتائج نجاح الطريقة “Forget-MI” في خفض مقياس هجوم استنتاج العضوية بنحو 0.20 في المتوسط، وخفّض مقياسي المساحة تحت المنحنى و”F1″ على مجموعة النسيان بنحو 0.22 و0.31 على التوالي، مع الحفاظ على أداء مماثل لأداء النموذج المعاد تدريبه على مجموعة الاختبار، وهو المعيار الذهبي في حال توفر الوقت والموارد الحاسوبية وإمكانية إعادة التدريب من الصفر.
عند المقارنة مع الطرق القياسية الشائعة، حققت الطريقة “Forget-MI” أدنى قيم على مقياس هجوم استنتاج العضوية (أي أنها حققت أعلى مستوى من الخصوصية)، مع بقاء الأداء على مجموعة الاختبار قريباً من مستوى أداء نموذج خضع لإعادة التدريب. في المقابل، فشلت الطرق التي لا تميز بين الوسائط المختلفة في تحقيق اختلاف كبير بين نتائج النموذج بعد محو ما تعلمه من البيانات ونتائج النموذج الأصلي، بينما حافظت الطرق التي تميز بين الوسائط المختلفة على الدقة بشكل أفضل لكن مستوى النسيان فيها كان أقل، ما يعكس المفاضلة بين الخصوصية والمنفعة التي ناقشتها الباحثتان بشكل صريح.
يظهر الشكل أدناه مقارنة بين توزع الخسارة في مجموعة النسيان وتوزع الخسارة في عينات من مجموعة الاختبار. ففي النموذج الأصلي، يمكن التمييز بين التوزيعين بوضوح. أما بعد محو ما تعلمه النموذج، فيصبح هناك تداخل بينهما، مما يعني أن النموذج لم يعد يتعرف على بيانات المرضى التي حُذفت بوصفها جزءاً من بيانات التدريب.
التكلفة والوتيرة: من حلول استثنائية إلى صيانة روتينية
استغرقت عملية إعادة التدريب بشكل كامل في هذا الإعداد نحو 14 ساعة، بينما استغرق تنفيذ الطريقة “Forget-MI” حوالي خمس ساعات، واستغرق تنفيذ الطرق الأخرى لمحو ما تعلمه النموذج نحو أربع ساعات. وهذا الفارق يكتسب أهمية تشغيلية، حيث يمكن للمستشفيات تجميع طلبات حذف البيانات وتنفيذها (بشكل شهري مثلاً) دون تعطيل أنظمة الذكاء الاصطناعي الطبي لعدة أيام.
إحدى النتائج غير المتوقعة التي توصلت إليها الدراسة هي أن الضبط الأمثل للإعدادات الأربعة يعتمد على حجم البيانات المطلوب حذفها. فعند حذف بيانات نسبة 3% من المرضى، كان التركيز على محو ما تعلمه النموذج من البيانات الأحادية هو الأكثر فعالية. وعندما ارتفعت النسبة إلى 6%، أصبح التركيز على محو ما تعلمه من البيانات متعددة الوسائط هو الأهم. وعندما وصلت النسبة إلى 10%، أصبح من الضروري التركيز بشكل أكبر على الحفاظ على بيانات بقية المرضى للمحافظة على مستوى الأداء العام. وهذا يشكل دليلاً عملياً يمكن للمستخدمين الاستفادة منه مستقبلاً.
لماذا تزداد صعوبة الحفاظ على الخصوصية في حالة البيانات المتعددة الوسائط (ولماذا تُعد الطريقة الجديدة تقدماً)
في حالة محو ما تعلمه النموذج من بيانات أحادية، يمكن تعديل مُشفّر واحد فقط. أما في التطبيقات السريرية الواقعية، فالنماذج تتعلم أن “هذا النمط من التعتيم” في صورة الأشعة، إلى جانب “هذه العبارة” في التقرير، يشيران معاً إلى وجود مرض. وغالباً ما تكمن أقوى أشكال التعلّم في هذا التمثيل المشترك. ولهذا تعمل طريقة “Forget-MI” على محو كلٍّ من التمثيلات الأحادية والمشتركة في مجموعة النسيان، مع الحفاظ على تمثيلات بقية المرضى.
وتعامل الفريق أيضاً مع حالة المرضى الذين لديهم عدة فحوص من خلال تعريف مجموعات النسيان على مستوى المريض بحيث لا يتمكن النموذج من التذكّر بشكل غير مباشر عبر بقية الفحوص.
وتشير الدراسة أيضاً إلى بعض القيود والملاحظات المهمة حول هذه الطريقة. أولاً، كلما زاد حجم مجموعات النسيان، تدنى مستوى الأداء. فعندما تكون نسبة هذه البيانات 10%، تزداد صعوبة الحفاظ على أداء النموذج في مجموعة الاختبار، وهو ما يشير إلى أن الطرق الحالية لمحو ما تعلمه النموذج ما زالت تواجه قيوداً عندما يكون حجم البيانات المطلوب حذفها كبيراً. ثانياً، ينبغي ضبط درجة التشويش بدقة متناهية، لأن عدم وجود تشويش يعني بقاء آثار من بيانات المرضى، بينما الإفراط فيه يضعف قدرة النموذج على التعميم. وأخيراً، يظهر اختلال في التوازن بين الفئات، فعندما تكون البيانات محدودة (في فئات الأقلية) يؤدي الحذف القوي للبيانات إلى تدهور المؤشر “F1″، أي تراجع الأداء، وهو جانب آخر من المفاضلة بين الخصوصية والمنفعة التي أشارت إليها الباحثتان.
ما الذي تعنيه طريقة “Forget-MI” بالنسبة للمستشفيات وللنماذج التأسيسية
توفر طريقة “Forget-MI” ميزة واضحة لمسؤولي الخصوصية الراغبين في الانتقال من الأفكار النظرية إلى التطبيق العملي. ويمكن تصور إجراء عملي واضح يتضمن تجميع طلبات الحذف بشكل دوري (شهرياً مثلاً)، ثم تنفيذ الطريقة “Forget-MI” لإنتاج نموذج خالٍ من آثار البيانات المطلوب حذفها وقابل للتدقيق، مع قياس الأداء من خلال مؤشرات هجوم استنتاج العضوية، والمساحة تحت المنحنى/”F1″ لمجموعة النسيان، والمساحة تحت المنحنى/”F1″ لمجموعة الاختبار. كما يمكن لموردي أنظمة إدارة السجلات الصحية الإلكترونية وأنظمة أرشفة الصور الطبية إتاحة واجهة برمجية في أنظمتهم تسمح بحذف بيانات مريض معين، مع إمكانية اختيار البيانات على مستوى المريض لضمان شمول الحالات التي تتضمن عدة فحوص لنفس المريض.
وفي المستقبل القريب، يمكن أن تسهم طريقة “Forget-MI” في معالجة تحدٍ معروف يتعلق بالنماذج التأسيسية ومحو ما تعلمته، حيث أن التدريب المسبق واسع النطاق لهذه النماذج يعني وجود عدد كبير من الحالات المتشابهة، مما يجعل من الصعب إثبات زوال آثار جميع البيانات المتعلقة بمريض معين. وهنا تشير تاراتينوفا إلى أن المجال سيحتاج إلى أساليب تقييم أكثر صرامة، وضبطاً أدق للمعاملات، وربما إلى مقاييس جديدة لتعزيز الثقة في النماذج التأسيسية. كما يمكن توسيع طريقة “Forget-MI” لتشمل البيانات بأي مزيج من الوسائط، مثل مقاطع الفيديو المصحوبة بنصوص أو تسجيلات صوتية.
فكيف يمكن التأكد من أن نموذجاً معيناً قد محا ما تعلمه؟ أفضل مقياس متاح حالياً لذلك هو تطابق أداء ذلك النموذج مع نموذج أُعيد تدريبه من الصفر دون استخدام البيانات المحذوفة، إلى جانب انخفاض مقياس هجوم استنتاج العضوية وضعف الأداء على مجموعة النسيان، مع الحفاظ على مستوى الأداء على بقية البيانات.
وهذا هو المعيار الذي تسعى طريقة “Forget-MI” إلى تحقيقه (وقد نجحت إلى حد كبير في ذلك على مجموعة البيانات “MIMIC-CXR”) مع توفير قدر كبير من الوقت والموارد الحاسوبية مقارنة بإعادة التدريب بشكل كامل. وقد نشرت الباحثتان التعليمات البرمجية لتمكين الآخرين من تدقيق الطريقة وتطويرها.
تقول حردان: “لن يثق الأطباء في فعالية عملية محو ما تعلمه النموذج من البيانات إلا عندما يتأكدون من أمرين: عدم تعرف النموذج على المرضى الذين تم حذف بياناتهم، واستمراره في العمل بكفاءة لبقية المرضى”.
ورغم أن طريقة “Forget-MI” لا تقدم حلولاً لجميع الحالات المعقدة المتعلقة بحذف البيانات، فإنها تحوّل مفهوم حماية الخصوصية من فكرة نظرية إلى عملية تشغيلية سريعة يمكن تنفيذها ضمن الإجراءات الروتينية في المستشفيات، وهو بحد ذاته تقدم مهم.
- المؤتمرات ,
- MICCAI ,
- الأبحاث ,
- مجموعات البيانات ,
- البيانات ,
- متعدد الوسائط ,
- التصوير الطبي ,
- الخصوصية ,
- المعلومات ,
- الباحثون ,
أخبار ذات صلة

تطوير ذكاء اصطناعي يفهم التحديات المناخية في الخليج
طور فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي إطاراً جديداً يحمل اسم "المساعد الذكي للمناخ.....
- ACL ,
- conference ,
- climate change ,
- computer vision ,
- research ,

باحثون في جامعة محمد بن زايد للذكاء الاصطناعي يطورون إطاراً جديداً يعزز موثوقية النماذج متعددة الوسائط
باحثون من جامعة محمد بن زايد للذكاء الاصطناعي يكشفون عن إطار عمل جديد سيمكن النماذج متعددة الوسائط.....
- المؤتمرات ,
- النماذج متعددة الوسائط ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

نموذجان أفضل من واحد لفهم الفيديوهات
نجح فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي في تطوير نهج مبتكر لفهم مقاطع الفيديو،.....
- الفيديو ,
- النماذج متعددة الوسائط الكبيرة ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- البحوث ,
- المؤتمرات ,