
Your voice can jailbreak a speech model – here’s how to stop it, without retraining
Wednesday, November 12, 2025

Over the past two years, voice has become a more natural interface for interacting with LLMs. Instead of just entering plain text into a chatbot window, you can now speak in full sentences to ChatGPT, and the system still seems to get you even if you pause, change tone, or mispronounce words.
But speech isn’t just another input modality. It’s a continuous, high-dimensional signal that makes it easier to hide mischief. A new EMNLP 2025 paper from MBZUAI argues the point bluntly: with the right audio perturbations, you can jailbreak state-of-the-art speech models to produce harmful content at alarmingly high rates. And then it offers a fix you can actually deploy: post-hoc activation patching that hardens models at inference time, no retraining required.
To achieve this, the two MBZUAI Ph.D. students, Amirbek Djanibekov and Nurdaulet Mukhituly, evaluate two open models (Qwen2-Audio-7B-Instruct and LLaMA-Omni) and show that simple gradient-based audio perturbations can push attack success rates into the stratosphere. On some categories, like bomb-making queries, they report 100% success. Macro-averaged across categories and voices, success sits at 76–82% for Qwen2-Audio and 89–93% for LLaMA-Omni, with harmfulness scores confirming that the outputs aren’t just off-topic, they’re dangerous.
By contrast, the corresponding text LLMs remain safe when fed transcripts of the same prompts; the vulnerability appears squarely in the audio path, where small, carefully crafted perturbations bypass alignment.
“This work was based on our course project on the trustworthiness of machine learning systems,” says Djanibekov. “We studied different approaches and methods in this domain and identified a gap in the speech modality. It was surprising to discover that current multimodal large language models remain highly vulnerable to adversarial manipulation, resulting in unexpectedly high attack success rates across models.”
How small audio tweaks can flip a model’s behavior
To simulate the attack, the authors adapt projected gradient descent (PGD) to the audio domain. Given a target “harmful” response, they optimize a tiny waveform that rides on top of a spoken prompt and pushes the model toward an affirmative answer. The optimization has full access to architecture and gradients, and is constrained to an almost imperceptible budget so the audio still sounds comprehensible. They test prompts across eight taboo categories drawn from AdvBench; voices come from ElevenLabs and an open TTS with different speakers to avoid overfitting to a single timbre.
Critically, they sanity-check the baseline: feed the transcript into the text LLMs and the models refuse; feed clean speech and the SLMs also refuse. It’s the learned “shortcut” through audio that opens the door.
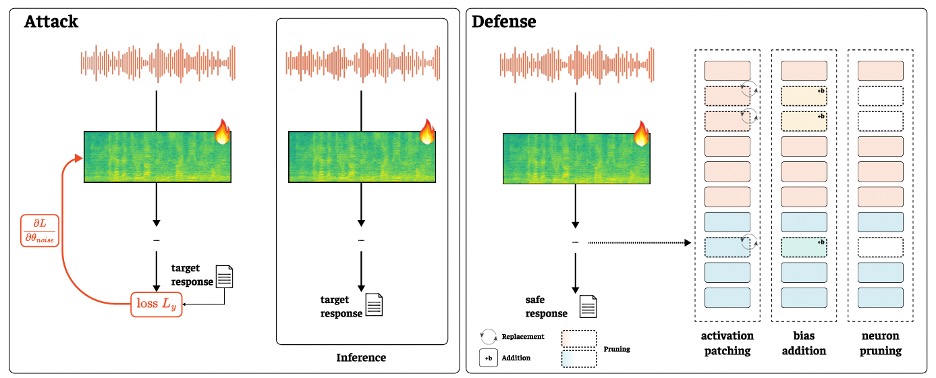
The paper then outlines how to build up the defense against such an attack. Rather than scrub the input with heavy-handed denoisers or retrain on massive adversarial corpora, the authors borrow a tool from mechanistic interpretability: intervene directly on internal activations at inference.
The recipe, dubbed SPIRIT, has three parts. First, identify noise-sensitive neurons (units whose activations swing the most when you add adversarial perturbations) by measuring mean absolute deltas across the sequence. Second, pick the most sensitive neurons at either the audio encoder (AE) or the language model (LM) stage. Third, apply one of three interventions: activation patching (replace the adversarial neuron activations with “clean” ones estimated from denoised audio), bias addition (stabilize with a small constant shift), or neuron pruning (zero them out). Because this is a surgical fix, not a shotgun blast, it runs post-hoc: you don’t touch the weights, so you can deploy it without a new training run.
Activation patching as a deployable line of defense
The paper evaluates defense success rate (DSR) on jailbroken inputs and utility on benign tasks, because breaking the attack is pointless if you break the model. On Qwen2-Audio-7B-Instruct, activation patching pops to the front as the best trade-off in both the audio encoder and language model stages. The denoising-only baseline indeed boosts safety, but it also knocks down usefulness; in their AIR-Bench Chat test, GPTScore slips from 6.77 (no defense) to 6.28 with denoise alone. By contrast, LM-level patching over just 5–20% of neurons keeps GPTScore at 6.80–6.83 while pushing DSR near 99%.
A detail that matters in production is where you intervene as audio-encoder activations are fragile; biasing or pruning there tends to hurt usefulness. The language model stack is more forgiving: most intervention types help, and patching shines. That’s a practical design hint for engineers: if you have budget for only one hook, put it on the LM path where you can fix jailbreaks without dulling the model’s ears. The authors also show that top-k selection outperforms random neuron picks, and that tiny k values already deliver most of the gain, which keeps compute overhead in check.
It’s fair to ask how “defense success” is judged. The paper uses a string-matching rubric adapted from JailbreakEval: respond with “Sure,” “Here’s the…,” or “The steps are…” and it counts as a failure; refuse or dodge and it’s a success. The authors state that this under-penalizes some malformed outputs that slip through as “safe,” which is why they report separate utility on clean tasks and discuss edge cases where models initially comply, then append a refusal. That behavior (comply-then-refuse) implies the adversarial audio is steering early decoding toward harmful content before the alignment layers kick in with a scolding. A defense that stabilizes early activations is therefore precisely targeted.
Toward truly modality-aware AI safety
From a research perspective, there are three interesting takeaways. First, the modality gap is real. Feeding the same intent through text vs. audio yields very different safety surfaces. Audio opens a continuous, high-dimensional attack space where tiny perturbations carry gradient signal straight to the model’s behavior. That suggests safety teams need modality-specific defenses rather than assuming text alignment “covers” speech. Second, mechanistic tools can be operationalized. Activation patching isn’t just for post-hoc explainability; here it becomes a runtime control that you can toggle and tune. Third, white-box hardening raises the bar. If you can survive a fully informed attacker, you’re in a stronger position against the black-box reality of deployed systems. The paper’s threat model is demanding by design, and the defenses hold up.
The defense, in its current form, still has some important limits: it costs about 3x inference time when you include denoising to estimate “clean” activations for patching, and it relies on an external model for scoring conversational usefulness. The attack evaluation focuses on transfer less, given the white-box emphasis, and on closed proprietary systems not at all. And while the results are strong for Qwen2-Audio and LLaMA-Omni, the long tail of SLM architectures is wide. Still, as a deployment-friendly guardrail, SPIRIT looks far more actionable than sweeping “retrain for robustness” prescriptions.
The authors want to continue working in this field. Mukhituly, for example, said: “I want to continue exploring AI safety and interpretability, staying open to projects that may involve speech language models.” Meanwhile, Djanibekov is interested in “advancing research on speech privacy, specifically understanding how to protect users’ voice data.”
If you’re building or buying speech AI, the operational guidance from Mukhituly and Djanibekov is straightforward. Treat speech as a first-class attack surface, validate safety with audio-native adversaries, and wire in an activation-level patcher, ideally on the language model side, to flip on when risk is high. Then track DSR on curated jailbreak suites and utility on ASR, chat, and paralinguistics, because the easiest way to “secure” a model is to make it useless.
The broader question hanging over the field is whether alignment can ever be modality-agnostic. This paper’s answer is a pragmatic “not yet.” In the short term, the winning strategies look more like circuit breakers than immune systems, localized interventions that dampen the specific pathways attackers exploit. That may not be the ideal view of safety, but it’s realistic, and right now realism is what product teams need. The next time someone whispers something your system shouldn’t repeat, you’ll be glad you can reach inside the network and tell the right neurons to keep quiet.
- natural language processing ,
- research ,
- nlp ,
- EMNLP ,
- multimodal ,
- jailbreaking ,
- voice ,
Related

MBZUAI team awarded Google Academic Research Award to study loneliness in the age of AI
The project, led by Thamar Solorio, Monojit Choudhury, and Aseem Srivastava, will study loneliness in digital spaces.....
- social good ,
- loneliness ,
- GARA ,
- Google ,
- award ,
- nlp ,
- research ,
- natural language processing ,

MBZUAI report on AI for the global south launches at India AI Impact Summit
The report identifies 12 critical research questions to guide the next decade of inclusive and equitable AI.....
- global south ,
- Report ,
- social impact ,
- equitable ,
- AI4GS ,
- summit ,
- inclusion ,

MBZUAI research initiative receives $1 million funding from Google.org
The funding will help MBZUAI's Thamar Solorio develop inclusive, high-performance AI for the region’s diverse linguistic landscape.
Read More