
Web2Code: A new dataset to enhance multimodal LLM performance presented at NeurIPS
Monday, December 16, 2024

One interesting use of multimodal large language models (LLMs), which are designed to process both images and text, is their ability to interpret and produce code for web pages. While today’s multimodal LLMs have these capabilities at a basic level, these systems need to be improved if they are to provide significant productivity gains in tasks such as web design and development.
A team of researchers from the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) and other institutions recently developed datasets that can be used to measure and improve the performance of multimodal LLMs in analyzing web pages and generating HTML code. They call their project Web2Code and it consists of a new dataset for fine-tuning LLMs and two new benchmark datasets for measuring LLM performance.
In their study, the researchers used a technique called instruction tuning to improve the performance of multimodal LLMs to generate HTML code and answer questions about screenshots of web pages. They found that improving these specialized capabilities didn’t affect the models’ performance on more general tasks.
The team was motivated in their effort to develop Web2Code after testing open-source multimodal LLMs and observing that the models weren’t particularly effective in these tasks, explained Zhiqiang Shen, assistant professor of machine learning at MBZUAI and co-author of the study. Their findings were presented at the 38th Annual Conference on Neural Information Processing Systems (NeurIPS).
A new instruction tuning dataset
Multimodal LLMs are trained on huge, broad sets of data in different formats — such as images, video and text — and on a wide range of topics. Indeed, it’s said that the most popular and largest models, such as OpenAI’s GPT series and Meta’s LLaMA series, have been trained on the entirety of the publicly available internet. This approach provides models with general abilities in processing and generating images and text.
After training, open-source systems can be fine-tuned for specific tasks through an approach called instruction tuning, where the model is given a set of questions or instructions and corresponding responses. The model processes this information and makes associations between the questions and desired responses.
While training data is broad, the specific data selected for tuning are extremely important, Shen explains: “In the instruction tuning stage, the quality of the data needs to be higher than what was used in pre-training.”
Web2Code contains an instruction tuning dataset that is comprised of four components: two components related to HTML code generation and two related to web page understanding. These modules build on previous datasets and include new data created by Shen and his colleagues.
For the first component, called DWCG, the researchers used OpenAI’s GPT-3.5 to create 60 thousand HTML web pages and a tool called Selenium WebDriver to generate screenshots of the webpages. These pairs of HTML web pages and their respective screenshots were converted into a format that could be used for instruction tuning.
For the second component, called DWCGR, the researchers modified two existing web page generation datasets called WebSight and Pix2Code and transformed them into an instruction-tuning format.
The third component is called DWU, and it is a new question-answer pair dataset created by Shen and his colleagues that is made up of nearly 250 thousand data points designed to improve a model’s ability to interpret and answer questions about information presented on webpages.
To build the fourth component, called DWUR, the researchers used OpenAI’s GPT-4 to improve a web page understanding dataset called WebSRC, removing duplicates found in the original dataset and refining questions.
“In the existing datasets, we found that some of the text descriptions were low quality, so we refined them and also generated new data ourselves that we contributed to the dataset,” Shen says.
New benchmark datasets
Shen and his colleagues also developed two benchmark datasets, one for testing multimodal LLMs on web page understanding (WUB) and another for testing them on generating web page code (WCGB).
WUB is made up of nearly 6,000 question-answer pairs generated by GPT-4 Vision API’s analysis of web page screenshots. The screenshots were drawn from other benchmarks, including WebSight, while others were taken from the internet. They are organized in a “yes” or “no” format.

Examples of questions from the web page understanding benchmark (WUB) included in Web2Code.
The WCGB benchmark uses the same screenshots as WUB and is designed to measure models’ abilities to generate web page code from images. Using Selenium WebDriver, the researchers convert the code generated by a model into an image, allowing for a kind of apples-to-apples visual comparison between the predicted code and the ground truth images. The evaluation criteria for WCGB are based on four categories: visual structure and alignment, color and aesthetic design, textual and content consistency and user interface and interactivity.
Instruction tuning and evaluating performance
The researchers tuned four open-source multimodal LLMs with their instruction tuning dataset and evaluated the models — LLaMA 3, CrystalChat, CrystalCoder and Vicuna — on the two benchmark datasets.
During the fine-tuning process, they applied the four components of the instruction tuning dataset (DWCG, DWCGR, DWU, DWUR) in a stepwise fashion so that they could examine the impact of each component on performance.
For the most part, on both the web page code generation benchmark and the web page understanding benchmark, the models improved as more components of the instruction tuning dataset were applied. However, the base version of LLaMA 3 performed better on the web page understanding benchmark than did the version that received instruction tuning with DWCG. Of the four multimodal LLMs tested, LLaMA 3, developed by Meta, achieved the best performance on both benchmarks.
Shen and his co-authors also tested the instruction-tuned versions of the models on general datasets. To his surprise, Shen said that instruction tuning made the models better at the specific Web2Code tasks while not affecting the general performance of the LLMs. “Our model can still be used as a general LLMs. You can ask it any questions and it will still respond,” he says.
Implications of Web2Code
Shen noted that the project was an interesting collaboration of scientists from different backgrounds, as authors on the paper included researchers from the disciplines of natural language processing, computer vision and machine learning.
The researchers noted the practical benefits of improving multimodal LLMs’ ability to generate HTML code from images. They show how their instruction-tuned CrystalChat model was able to create a webpage from a simple line drawing. This could have implications for web designers and developers who are interested in quickly iterating on website designs, or to provide people who are not trained as developers the ability to build their own websites from scratch.
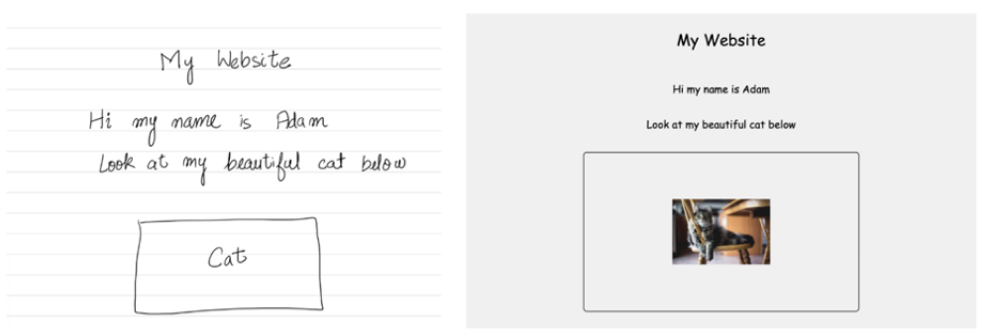
The researchers illustrate how the multimodal LLM CrystalChat was able to generate HTML code for a web page after being instruction tuned using their new suite of datasets called Web2Code.
There are other applications as well. “For people who can’t see or may have trouble reading a web page, our model could help read out the elements of the page and help the user understand page content,” Shen says.
The datasets are available at the website for the project.
- machine learning ,
- neurips ,
- dataset ,
- llms ,
- multimodal ,
- code ,
- instruction tuning ,
Related

The search for an antidote to Byzantine attacks
A new study from MBZUAI and other institutions tackles malicious and faulty updates in privacy-preserving machine learning.....
Read More
AI and the silver screen: how cinema has imagined intelligent machines
Movies have given audiences countless visions of how artificial intelligence might affect our lives. Here are some.....
- cinema ,
- art ,
- fiction ,
- science fiction ,
- AI ,
- artificial intelligence ,

Mind meld: agentic communication through thoughts instead of words
A NeurIPS 2025 study by MBZUAI shows that tapping into agents’ internal structures dramatically improves multi-agent decision-making.
- machine learning ,
- neurips ,
- agents ,