
Video search gets closer to how humans look for clips
Sunday, November 09, 2025

Most of today’s video searches can still feel clumsy and underwhelming: you either type a few keywords and hope for the best, or you hunt through thumbnails one by one. But what you often want is to point to a clip and say, “find me more like this but at dusk, and with one cyclist instead of three.”
That deceptively simple task is the core of a fast-growing research area called composed video retrieval, or CoVR. Instead of treating text and video as separate worlds, CoVR lets you start from an example clip and then describe the change you want in natural language.
A new paper at ICCV 2025 pushes that idea decisively forward with denser language, a stronger fusion model, and a lot more care in how the task is evaluated. One of the paper’s authors, MBZUAI Ph.D. student Dmitry Demidov, walked us through why this seemingly niche problem maps onto real creative and analytic workflows, from finding the right B-roll to pulling comparable plays in sports footage.
The paper’s authors argue that prior CoVR datasets described edits in short, vague phrases (e.g. “as a child,” “get rid of the jar”) that don’t force a model to align language with the actual visual changes across time. Their answer is Dense-WebVid-CoVR, a 1.6-million-sample benchmark with long, context-rich descriptions (about 81 words on average) and modification texts that average 31 words, roughly seven times longer than the previous standard. Those edits aren’t free-floating summaries of the target; they’re written to depend on the query clip, which blocks the easy cheat of text-only retrieval.
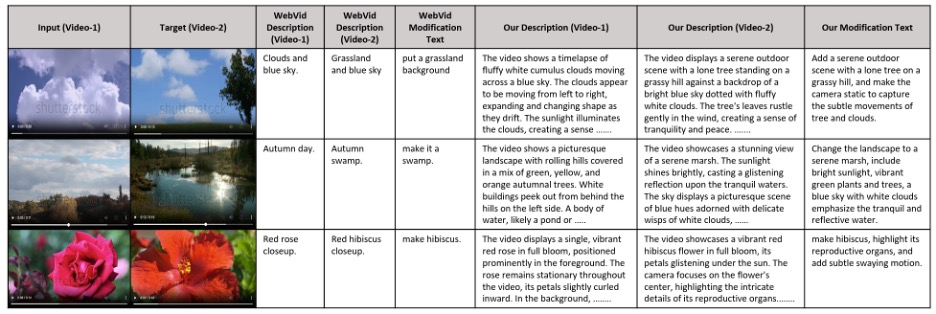
To build it, the team first generated video descriptions with Google’s Gemini Pro, then produced modification texts with GPT-4o, and finally ran a manual verification pass that corrected redundancy, counts, and temporal cues so the edit truly demanded multimodal reasoning. The test set is fully human-checked. It’s a lot of plumbing, but it matters: the new benchmark makes models prove they can handle subtle object changes, counts, camera motion, and timing.
A smarter CoVR pipeline
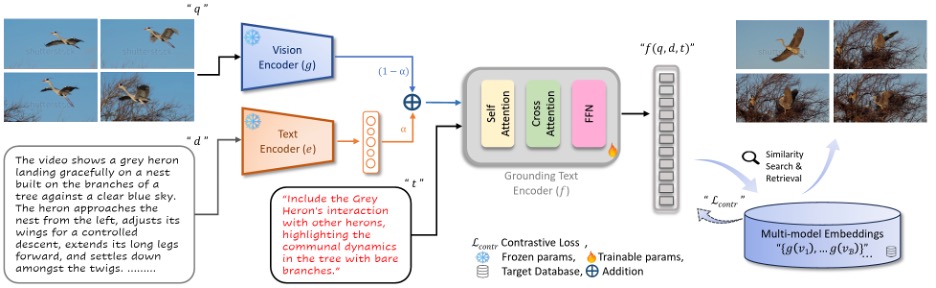
Earlier systems often stitched together pairwise fusions (e.g. video with text, description with text, video with description) and then tried to reconcile the results. The new approach adopts a unified fusion: it embeds the query video and its dense description, mixes them with a learned weight, and feeds that into a grounding text encoder that performs cross-attention with the dense modification text. The vision side uses a ViT-L backbone; the text components come from a BLIP-2 stack; and the training objective is a contrastive loss that pulls the fused query-plus-edit embedding toward the correct target clip in a large database.
The difference may sound fussy, but it shows up in the numbers and the behavior: joint reasoning across all three inputs reduces the tendency to miss fine-grained edit details that pairwise schemes drop on the floor. In validation analyses, the unified embedding sits measurably closer to the right targets than pairwise fusions.
On the headline benchmark, the gains are concrete. With both video and text inputs and cross-attention fusion, the model hits Recall@1 ≈ 71.3% on Dense-WebVid-CoVR—about +3.4 points over the strongest prior method under the same backbone and modalities. In plain English, almost three out of four searches now return the correct clip as the very first result, which is exactly what a video editor experiences as “it just finds it.” The system is also about three times faster than the pairwise baseline because it avoids redundant passes through multiple fusion paths. And the richer language pays off twice: training on dense modifications and inferring with dense video descriptions each give independent bumps, with the best performance when both are used.
One fair question with longer text is whether CoVR devolves into text-to-video. The authors anticipated this and structured prompts to require reference to the query clip, with edits like “change the male adult to a young child practicing with an instructor nearby and a sheet of music on the stand” rather than “a young child practicing piano,” which could be matched without looking at the query. Demidov emphasized that the human verification targeted exactly these failure modes, reducing leakage where the edit text accidentally describes the target in isolation. In other words, dense language provides a stricter test.
When it comes to the architecture choices, the vision encoder is built for efficiency and often uses the middle frame to build the clip representation, mirroring prior work; the authors acknowledge that this can under-represent temporal transitions and propose lightweight temporal modules as a next step. That caveat becomes more obvious when the model is stress-tested out of domain. On Ego-CVR, a small egocentric benchmark where ~79% of queries hinge on temporal events, the unified fusion still transfers well and posts state-of-the-art zero-shot results which is solid evidence that dense edits and joint reasoning generalize. The authors note however that unusual points of view and rapid action changes push current temporal handling to its limits. Interestingly, the same recipe also works for composed image retrieval: on CIRR and FashionIQ, the approach sets new marks in both trained and zero-shot settings, suggesting the fusion scheme isn’t narrowly tailored to video.
From research to real world impact
Why does any of this matter outside a leaderboard? Because composed queries are how people actually think. In creative production, you rarely search for “a generic sunset.” You search for your shot, edited: same street, but at dusk; same kitchen, but plated rather than assembling; same rider, but on a green motorcycle seen from the rear. In the authors’ qualitative comparisons, the pairwise baseline tends to retrieve near misses while the unified model gets the details right: yellow tulips rather than yellow tulips with red flames on a white brick background; a close-up of a motorcycle rather than a wider shot of the mechanic working on the vehicle. Those are exactly the kinds of differences that cost editors time.

Demidov believes this could extend use cases to sports analytics (“same corner kick but headed finish”), education (variants of demonstrations with small setup changes), and personal libraries (“same birthday scene but with grandma cutting the cake”), while pointing to familiar guardrails around privacy and bias in surveillance-adjacent retrieval.
For researchers, several technical takeaways stand out. First, language density helps not just because it provides more tokens, but because it forces models to align phrases with visual evidence via cross-attention. Second, fusion strategy matters: unifying video, description, and edit inside a single grounding encoder preserves interactions that pairwise pipelines dilute. Third, evaluation hygiene is a first-class design choice: human-verified test prompts and query structures that forbid standalone target descriptions produce more trustworthy scores and fewer text-only shortcuts. And while the paper follows prior efficiency conventions, the authors’ ablations make a strong case that most of the gain comes from better supervision and better fusion, not just a bigger backbone or more GPU.
The limits are equally clear, and they double as a roadmap. Temporal understanding remains shallow when the representation leans on a single frame. Counting and role changes that unfold over a few seconds are still fragile. The authors suggest tool-augmented fusion (plugging in a temporal localizer that first marks where the change likely happens) so the grounding encoder isn’t guessing across an entire clip. Multilingual CoVR is another frontier: keeping edits dense while supporting low-resource languages will likely require a mix of native-written prompts, careful translation, and consistency training so the same edit across languages ranks the same target. And of course, scaling to very long videos means rethinking how descriptions, edits, and frames are chunked and attended to within a fixed compute budget.
Benchmarks, at their best, change how a field talks about progress. Dense-WebVid-CoVR sharpens the conversation by asking systems to act more like collaborators: “Here’s my clip; here’s how I’d change it; now find me the best match.” The model that accompanies it shows that a modestly different architecture, fed the right kind of language, can make a practical difference, lifting first-hit accuracy into a range that matters for editors, analysts, and anyone else who searches by example. There’s plenty left to do, especially around time, but as Demidov put it, once you make the edits explicit and ground them to the query, you’re much closer to the way people already think. That’s when search stops being a guessing game and starts feeling like a conversation.
- research ,
- computer vision ,
- conference ,
- ICCV ,
- video ,
- natural language ,
- paper ,
Related

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More
MBZUAI and Minerva Humanoids announce strategic research partnership to advance humanoid robotics for applications in the energy sector
The partnership will facilitate the development of next-generation humanoid robotics tailored for safety-critical industrial operations.
Read More
AI and the silver screen: how cinema has imagined intelligent machines
Movies have given audiences countless visions of how artificial intelligence might affect our lives. Here are some.....
- cinema ,
- art ,
- science fiction ,
- fiction ,
- AI ,
- artificial intelligence ,