
Text-to-speech system brings real-time speech to LLMs
Monday, May 26, 2025

When working with today’s most popular large language models, such as OpenAI’s GPT series and Meta’s LLaMA, users typically interact with them through the written word. This has limited the ability of LLMs to function as true virtual assistants capable of natural, multimodal, human-like interactions, says Hisham Cholakkal, assistant professor of computer vision at MBZUAI.
Cholakkal, along with colleagues at the University, is co-author of a recent study that proposes a new method to equip any LLM with the ability to produce speech. Their system, called LLMVoX, can also be adapted to vision-language models and for different languages. The team demonstrated LLMVoX’s capabilities in both English and Arabic, marking the first time a system of its kind has been developed for Arabic.
The researchers have open-sourced the code, models, and training data. Their paper about LLMVoX has been accepted by Findings of the Association for Computational Linguistics 2025.
MBZUAI researchers Sambal Shikhar, Mohammed Irfan Kurpath, Sahal Shaji Mullappilly, Jean Lahoud, Fahad Khan, Rao Muhammad Anwer, and Salman Khan are coauthors of the study.
LLMVoX was developed as part of Cholakkal’s Project OMER, which was recently awarded Regional Research Grant from Meta. The objective of Project OMER is to improve the ability of LLMs to be used as multimodal (visual-speech) conversational assistants, especially in the Middle East.
Helping LLMs speak
While LLMs themselves typically aren’t built to produce speech, developers have employed different methods that give users the ability to interact with LLMs by talking to them.
One approach is called an ‘end-to-end’ system. In this case, an LLM is fine-tuned on speech data in addition to text. It has drawbacks, however. Cholakkal and his colleagues write that fine-tuning on speech often influences the “reasoning and expressive capabilities of the base LLM,” with models performing worse than they would otherwise. Additionally, because end-to-end systems aren’t modular, any effort to improve their capabilities requires retraining or additional fine-tuning.
Another approach is known as a ‘cascaded pipeline.’ In this setup, a user’s speech is converted into text using an automatic speech recognition system. This text is processed by the LLM. After the LLM generates an output, a text-to-speech system turns the LLM’s text output into audio.
A cascaded pipeline is good because developers can improve components of the system without having to modify other parts. That said, translation from one module to another causes latency, and the experience using a cascaded system doesn’t mimic the normal cadence one would expect in a conversation with a human.
The main cause of this latency is that LLMs and text-to-speech systems are somewhat incompatible as they generate outputs in different ways. LLMs are autoregressive, meaning they create pieces of text sequentially based on previous pieces. Text-to-speech systems, however, typically need a chunk of text to begin generating an output. That said, there are text-to-speech modules that are autoregressive, but they aren’t streaming systems — they don’t immediately share the speech they generate in real time. This also causes latency.
By combining both autoregressive and streaming capabilities, LLMVoX makes the experience of communicating with an LLM through speech more natural. It uses a lightweight transformer model — the same underlying architecture that powers LLMs — that runs in parallel with the LLM. This allows LLMVoX to start speaking as soon as the initial text is generated, keeping latency low without sacrificing accuracy or voice quality.
Shikhar, the first author of the LLMVoX research paper and a research associate at MBZUAI, explains that he and his coauthors “wanted to develop a text-to-speech model that worked in an autoregressive fashion, so that as soon as the LLM began generating text, we can start generating and streaming the speech.”
Even though LLMVoX is essentially a cascaded pipeline, the researchers found that it exhibited significantly less latency (300 milliseconds milliseconds) compared to another cascaded pipeline system (4,200 milliseconds).
How LLMVoX is different
LLMVoX is a light-weight text-to-speech model having only 30 million parameters. This means that it can be deployed on a variety of devices and in different settings.
The team has also developed a version of LLMVoX that users can run on a laptop, without the need for access to GPU servers. “It’s very light and even on a laptop you can get a response in less than one second,” Shikhar says.
While other systems are limited in the amount of speech they can generate at any one time, LLMVoX can produce speech of any length due to its design. To do this, it employs what the researchers call a “multi-queue streaming mechanism.”
The mechanism consists of two identical LLMVoX modules. The first module processes a selection of text, while the second module produces another selection. The system toggles between the two modules allowing it to generate longer sequences of speech than it could otherwise. Shikhar says that there is no limit on the context length.
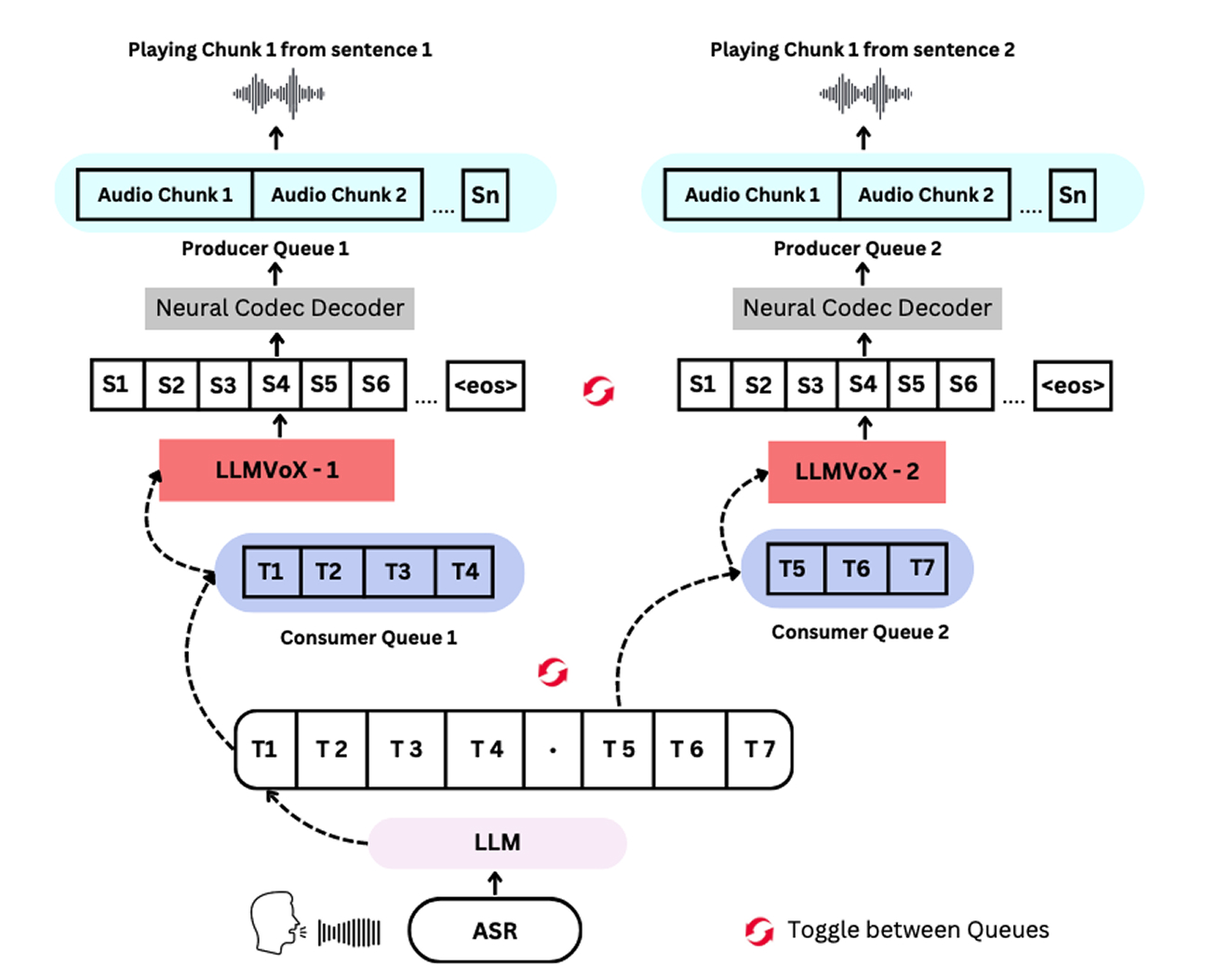
LLMVoX employs two identical text-to-speech modules to process text from an LLM in parallel, which gives the system the ability to turn text of any length into speech.
Text-to-speech for Arabic and other languages
The researchers developed a synthetic dataset of text and speech to train it in Arabic and connected it to different Arabic LLMs.
This is the first time scientists have built an autoregressive text-to-speech system for Arabic. But the researchers’ work doesn’t end there. “Our pipeline is designed for multiple languages, and we are scaling it up to other languages beyond English and Arabic,” Cholakkal says.
Comparing LLMVoX to other systems
The researchers used GPT-4o to evaluate the performance of LLMVoX on a question-answer dataset and compared it to the performance of other cascaded pipeline and end-to-end systems. (They used GPT-4o to evaluate transcriptions of the speech produced by the systems.) The researchers found that LLMVoX performed better than the others on general question-answer tasks and on overall knowledge.
The researchers also had people evaluate LLMVoX in comparison to another model called Freeze-Omni, a speech LLM model. The researchers selected 30 questions from different domains and gave five questions to each evaluator. Thirty people in total participated in the study. For this test, the researchers used a system called Whisper-Small for automatic speech recognition, LLaMA 3.1B for the LLM, and LLMVoX for the text-to-speech component.
Evaluators rated the best response produced by the two systems according to two metrics: answer relevance and speech quality. These answers were aggregated to evaluate the overall performance of the models. LLMVoX was better 62% of the time for speech clarity and 52% of the time for answer relevance. Freeze-Omni was better only 20% of the time on each metric, with the two systems tying the rest.
A future of talking LLMs
As LLMs become more prevalent in our world, users will expect to be able to interact with them through speech, instead of typing out every query or command on a keyboard. It’s also likely that we will see a proliferation of LLMs that are adept in different domains and tasks, Shikhar explains.
“You could have an LLM that is specialized on stocks and a speech model that is specifically trained for that sector,” he says. “With an approach like LLMVoX, a developer would train an LLM with specialized domain data for the text modality and plug it into our tool so that it can become speech enabled.”
Cholakkal says that “the plug-and-play nature of LLMVoX is what is most important and is the core proposition of this approach. It gives the ability to talk to any LLM.”
- computer vision ,
- llm ,
- llms ,
- Arabic language ,
- language ,
- multimodal ,
- visual language model ,
Related

When disagreement becomes a signal for AI models
Research from MBZUAI and Melbourne offers new metrics and training approaches that aim to better align AI.....
- labels ,
- human judgment ,
- Computational linguistics ,
- benchmark ,
- language ,
- nlp ,
- research ,

Why AI can describe an image but struggles to understand the culture inside it
A new MBZUAI paper, accepted at EACL 2026, introduces JEEM – a benchmark for evaluating how AI.....
- nlp ,
- image ,
- Arabic ,
- multimodal ,
- culture ,
- language ,
- EACL ,
- conference ,
- research ,
- natural language processing ,

MBZUAI team awarded Google Academic Research Award to study loneliness in the age of AI
The project, led by Thamar Solorio, Monojit Choudhury, and Aseem Srivastava, will study loneliness in digital spaces.....
- natural language processing ,
- research ,
- nlp ,
- social good ,
- loneliness ,
- GARA ,
- award ,
- Google ,