
Overcoming the ‘reversal curse’ in LLMs with ReCall
Monday, July 28, 2025

A few years ago, AI researchers discovered an interesting phenomenon: the order that information appears in a piece of text influences the ability of a large language model (LLM) to correctly answer questions about it.
For example, if you give an LLM a line from a song and ask it for the line that comes after it, the LLM will probably give you the right answer. But if you ask it for the line that comes before it, the answer will likely be wrong. The researchers called this the ‘reversal curse’ and it’s a quirk of the transformer – the technology that’s at the heart of today’s best LLMs.
Transformers are unidirectional in that they generate tokens — words or pieces of words — in one direction. Some languages are written left-to-right (English), others are written right-to-left (Arabic). Transformers can be designed to follow the directionality of any given language, but they always work in one direction, explains Munachiso Samuel Nwadike, a research associate at MBZUAI. “This means that when you train a model to read and produce text in a particular order, the performance isn’t as good when that order is changed.”
And yet, if this is a problem for transformers, how, for the most part, do language models remember information so well, no matter where information appears in a piece of text? That’s the question Nwadike and his co-authors from MBZUAI and other institutions examine in a new study that will be presented at the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) later this month in Vienna.
The researchers identify features in data used to train LLMs, which they call “self-referencing causal cycles,” that can be used to overcome the reversal curse. It’s an efficient solution that can improve the performance of language models.
Zangir Iklassov, Toluwani Aremu, Tatsuya Hiraoka, Benjamin Heinzerling, Velibor Bojkovic, Hilal Alqaubeh, Martin Takáč, and Kentaro Inui are co-authors of the study.
Challenges of sequentiality
An English-language LLM that uses the transformer architecture generates tokens from left-to-right in an autoregressive fashion, with new tokens based on previous ones. Responses to prompts work this way as well. When a user types something into an LLM, the model will respond, but it must do so based on what was in the prompt. “These systems don’t work like the human brain where we have concepts in our head that aren’t necessarily tied sequentially,” Nwadike explains. “They don’t get creative with information in the same way we do.”
While the reversal curse has been shown to be an issue with LLMs, he and his co-authors explain how it can also be an asset, due to the way information is structured in texts that have been used to train language models. Individual words and phrases typically don’t appear only once but are instead often repeated throughout a piece of text.
Again, a song is a good example. In a contemporary pop tune, the chorus may appear three or four times, perhaps with slight variations from one instance to the next. In this case, individual tokens, or series of tokens, are repeated. Nwadikeand his co-authors refer to these as “cycle tokens,” and they can be used as a kind of hyperlink to recover information that a model might struggle to find otherwise.
In practice this means that whenever there is information that appears several times, a model has multiple paths it can follow to get to information it needs to respond to a prompt. And cycle tokens don’t only appear in songs — they’re found in all kinds of texts.
The researchers call the repeated appearance of tokens or series of tokens “self-referencing causal cycles” (ReCall) and propose a two-step prompting strategy that uses them to improve language models’ abilities to retrieve information.
The approach forces a model to explore all the different locations of cycle token sequences in question, helping it find relevant information that it might not consider otherwise.
Total ReCall
In the study, the researchers liken cycle tokens to a reference system in a library. If prompting a language model is like asking a librarian to answer a specific question, using ReCall is like asking a librarian for all the books on a particular topic. “This wouldn’t work for a human because it would take a huge amount of time to go through all the books,”Nwadike explains. “But for an LLM it makes perfect sense because once it has all the relevant information it can accurately respond to the prompt.”
ReCall allows a model to “loop back” to access sections of text that appear earlier in a sequence, giving a traditionally unidirectional model the ability to analyze text in two directions. Aremu, a Ph.D. student in Machine Learning at MBZUAI and co-author of the study says that “we discovered that the solution to the reversal curse could basically be solved using cycle tokens.”
He also says that the approach can be used not only to solve for the reversal curse but also to improve the overall responses of models. It can be generalized to prevent hallucinations as well, he adds.
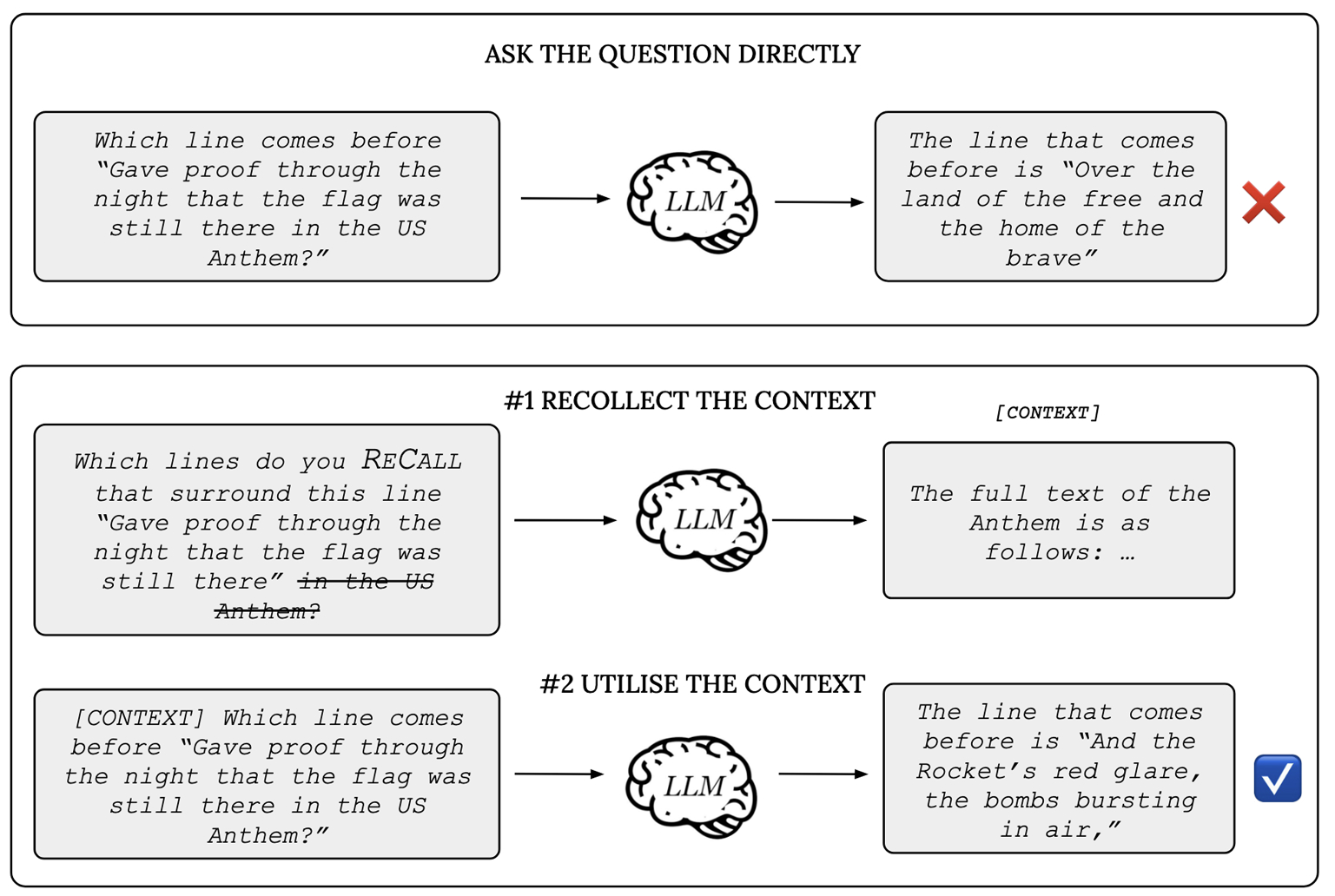
A two-step prompting strategy called ReCall, developed by researchers at MBZUAI and other institution, can be used to overcome a limitation of LLMs known as the “reversal curse” and improve the performance of autoregressive LLMs in recalling relevant information about texts.
The result of using ReCall as a prompting strategy is that models perform much better than they would otherwise. “Wherever there are cycle token sequences we can guarantee that we will get 100% recall with a model,” Nwadike says. “But it has to be a scenario where there are cycle token sequences and we have to prompt the model to recover this information.”
Other researchers have developed methods to address the reversal curse. These include data augmentation, token permutation, and token repetition techniques that are designed to “enhance causal links in training data,” the authors write. But these are manual processes that are resource intensive. ReCall is more efficient because it relies on patterns in data that are already there.
Iklassov, a Ph.D. student in Machine Learning at MBZUAI and co-author of the study, focused on prompt-engineering aspects of ReCall and says that “given that there is such a thing as the reversal curse, our approach can be used to solve it.”
Humans and machines
Nwadike explains that the central idea of the paper is to encourage the field to move toward a better understanding of model architectures and their limitations so that systems can be aligned with what people are trying to achieve when they use them. It’s about figuring out how the capabilities of machines and humans can complement one another and “meet in the middle.”
“As we work more with AI as a society, there will be an increasing number of opportunities to collaborate with the technology,” he says. “We’re fortunate to be working on this topic at a time when there is so much interest in it and research is advancing so quickly.”
- machine learning ,
- nlp ,
- large language models ,
- language models ,
- language ,
- ACL ,
- reversal curse ,
- performance ,
- transformer ,
Related
Building an AI model that actually speaks Hindi
MBZUAI’s Nanda models for Hindi and English show that effective multilingual AI depends on cultural and linguistic.....
- culture ,
- natural language processing ,
- nlp ,
- language ,
- IFM ,
- Institute of Foundation Models ,
- Nanda ,
- Hindi ,

AI models are becoming cultural archives
MBZUAI research shows how language models encode cultural knowledge — and how unevenly they express it across.....
- culture ,
- language ,
- EACL ,
- llms ,
- conference ,
- nlp ,
- research ,
- natural language processing ,

When disagreement becomes a signal for AI models
Research from MBZUAI and Melbourne offers new metrics and training approaches that aim to better align AI.....
- language ,
- labels ,
- human judgment ,
- Computational linguistics ,
- benchmark ,
- nlp ,
- research ,