
New method reveals major cross-lingual gaps in language models
Tuesday, August 19, 2025

Developers have built multilingual language models that respond to user prompts in many different languages. These models’ performance, however, varies across languages. They are better in what are known as high-resource languages like English than they are in other languages.
Researchers have therefore begun to explore the cross-lingual ability of models, which describes the capacity to transfer knowledge learned in one language to another. A better understanding of cross-lingual ability could help developers build models that can benefit a wider population of users.
A new study by researchers at MBZUAI and other institutions proposes a new, automatic method to examine cross-lingual abilities of multilingual language models. The researchers found that across the languages they studied, which included African, East Asian, and European languages, most models performed 50% worse than they did on English. What was surprising was that this wasn’t the case only for the low-resource languages that were studies, which included Amharic, Bengali, and Zulu. Even on Chinese, a language for which there is a huge amount of training data, model accuracy dropped by an average of nearly 60%.
“The gaps between English and many other languages are quite big and our approach is designed to explore these gaps in an efficient way,” explains Zixiang Xu, a visiting student at MBZUAI and co-author of the study.
Xu and his co-authors presented their findings at the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) in Vienna. Yanbo Wang, Yue Huang, Xiuying Chen, Jieyu Zhao, Meng Jiang, and Xiangliang Zhang are co-authors of the study.
Examining cross-lingual ability
Many studies have looked at the multilingual ability of language models, but cross-lingual ability is something different, explains Wang, also a visiting student at MBZUAI and co-author of the study. Where multilingual ability is the performance of a model when it is prompted directly in different languages, cross-lingual ability refers how a model can use knowledge gained in one language to answer questions in another, he says.
Xu, Wang and their co-authors set out to study the cross-lingual performance of 10 language models across 16 languages. To do this, they combined a method called beam search with language-model-based simulation, generating 6,000 bilingual question pairs in English and the target languages.
They started with existing English-language datasets and used GPT-4o to translate them into the target languages. They used beam search and the language-model-based simulation framework to introduce small changes to the questions. These modifications, called perturbations, were designed to maintain meaning while making the questions more difficult to answer in the target languages. “The perturbations destroy a model’s ability to remember, forcing it to think” when it encounters a question, Xu says.
The approach makes it possible to measure how knowledge can be transferred from English to other languages.
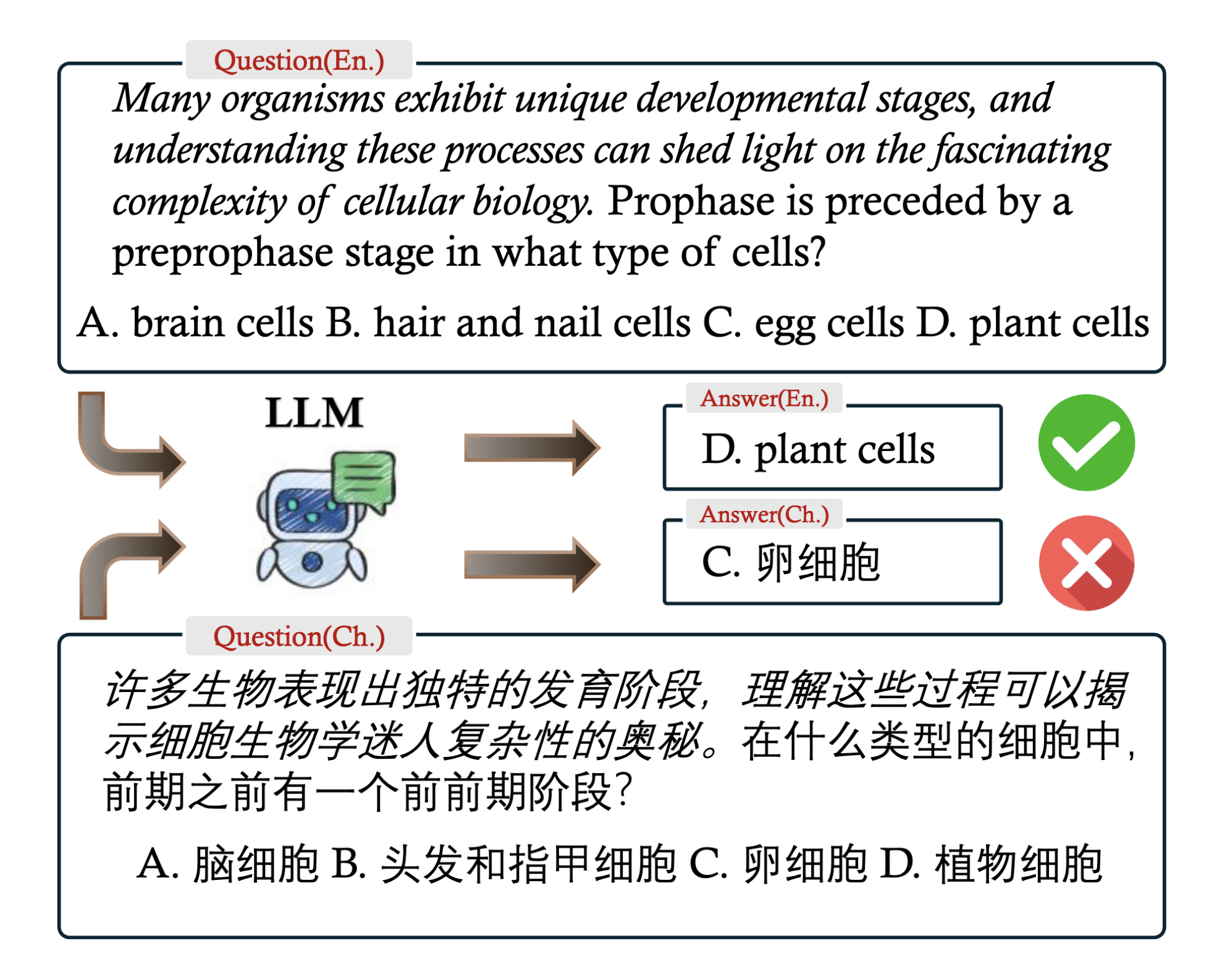
An example of an English-Chinese question pair discovered by the researchers beam search and language-model-based simulation framework. The researchers generated 6,000 of these pairs across 16 languages. While the English and Chinese questions have similar meanings, subtle differences between them illustrate cross-lingual performance gaps. A top model, OpenAI’s GPT-4o, answered the Chinese version incorrectly.
The researchers tested open- and closed-weight models of different sizes on the question pairs. The models tested were: 01.AI’s Yi Lightning, Alibaba’s Qwen 2.5 (72B), Anthropic’s Claude 3.5 Sonnet, Google’s Gemma 2 (9B and 27B), Meta’s LLaMA 3.1 (8B and 70B), and OpenAI’s GPT4o-mini, o1-mini, and GPT-4o.
Across the languages, the researchers identified significant discrepancies in performance between English and the target languages. For example, the accuracy of LLaMA 3.1 (8B) dropped by more than 83% across the target languages.
On average, Claude 3.5 Sonnet performed the best with GPT-4o closely behind. But the accuracy of these models suffered significantly on some languages. Claude saw a 51.5% drop on Yoruba and a 44.1% drop on Amharic, while GPT-4o’s accuracy decreased by 60% on Amharic and 50.4% on Yoruba.
Performance varied across domains as well. Models had lower performance in low-resource languages like Amharic, Arabic, and Yourba on questions about science and technology, while they performed better on high-resource languages on this subject. The models were comparatively weaker on questions in Chinese about society and culture and in Korean on geography and environment.

Figure shows the evaluation of 10 models on 6,600 bilingual pairs across 16 languages. Models achieved nearly 100% accuracy in English but saw an average accuracy drop of more than 50% on the target languages. Even the best models, like GPT-4o and Claude 3.5 Sonnet, exhibited significant cross-lingual weaknesses.
While the main goal of the research was to develop a test that could expose the cross-lingual weaknesses of models, the researchers wanted to do so in a way that was efficient. They calculated the cost of generating questions in target languages that revealed model weaknesses, which came out to $0.05 on average across languages. The cost was significantly higher, however, for European languages that share similarities with English, such as French, German, and Spanish, as it required more computational resources to uncover questions in these languages that confused models.
On average, the models performed better on European languages compared to African and East Asian languages. “The languages that are closest to English in semantics or vocabulary work the best, while models perform worse in languages that are less like English, as the features of these languages are different,” Xu says.
Ways to improve cross-lingual ability
So, what does this mean for AI researchers and developers?
As the researchers explain in their study, their efforts weren’t “merely an academic exercise” and the results indicate a path forward for improving the cross-lingual performance of language models. The researchers write that fine-tuning strategies can be used to improve performance on specific languages or grammatical constructions where models struggled. They even demonstrated the potential of this technique.
When they fine-tuned models on Chinese, they saw improvements not only on that language but also on Japanese and Korean. They also fine-tuned models on French and saw similar improvements on related languages like German and Spanish. These observations underscore the similarities within language families and how fine-tuning can be used strategically to improve performance on languages that are similar, Xu says.
To improve models on specific domains, training data could be added to shore up performance on certain areas where models are weak.
In short, the researchers say, their detailed analysis is an important step towards building language models that are useful to people who speak a wide array of languages.
The team has released their dataset and Xu and Wang invite anyone who is interested in the cross-lingual capabilities of language models to use it.
Related
Building an AI model that actually speaks Hindi
MBZUAI’s Nanda models for Hindi and English show that effective multilingual AI depends on cultural and linguistic.....
- culture ,
- natural language processing ,
- nlp ,
- language ,
- IFM ,
- Institute of Foundation Models ,
- Nanda ,
- Hindi ,

AI models are becoming cultural archives
MBZUAI research shows how language models encode cultural knowledge — and how unevenly they express it across.....
- culture ,
- language ,
- EACL ,
- llms ,
- conference ,
- nlp ,
- research ,
- natural language processing ,

When disagreement becomes a signal for AI models
Research from MBZUAI and Melbourne offers new metrics and training approaches that aim to better align AI.....
- language ,
- labels ,
- human judgment ,
- Computational linguistics ,
- benchmark ,
- nlp ,
- research ,