
New approach for better AI analysis of medical images presented at MICCAI
Wednesday, September 24, 2025
In addition to conducting exams, ordering lab tests, and reviewing medical histories, physicians often look at medical imaging, such as X-rays, to help them diagnose patients. Vision-language models are increasingly being built to assist with this process, yet today’s systems aren’t always accurate. When prompted to analyze medical imaging, even the best models hallucinate sometimes, giving confident but incorrect answers. In other cases, they simply misinterpret images.
One technique that can be used to improve model performance is known as retrieval-augmented generation, or RAG. RAG allows a model to pull in relevant information from a database and use it to complement its analysis, instead of simply relying on the insights it developed through training. While the idea behind RAG is simple enough, it’s not easy in practice because it’s often difficult to determine what information is relevant and what isn’t.
Researchers at MBZUAI and other institutions have developed a new approach that has the potential to improve the accuracy of vision-language models designed for medical image analysis. Their method, multimodal optimal transport via grounded retrieval (MOTOR), combines RAG with an algorithm called optimal transport. It retrieves and ranks image and textual data that are applicable to the image being analyzed and feeds it to a vision-language model.
The researchers tested vision-language models with and without MOTOR on two medical datasets and found that MOTOR improved average performance by 6.45%. The team is presenting their findings at the 28th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) in Daejeon, South Korea.
The authors of the study are Mai A. Shaaban, Tausifa Jan Saleem, Vijay Ram Papineni, and Mohammad Yaqub.
Challenges in medical image analysis
General-purpose vision-language models are trained on large, non-specialized datasets that often have been scraped from the internet. These huge sets of data are what give these systems their impressive abilities to interpret all kinds of images. But general-purpose models don’t work well in the clinic where interpretation requires specialization and nuance.
One way to make models better is by training or fine-tuning them on specialized datasets. But these are hard to come by in medicine. Patient privacy guidelines often prohibit the use of medical images for training AI systems and hospitals are reluctant to pool information into large datasets. Training and fine-tuning are also expensive in terms of computational costs.
RAG can address these challenges. “With RAG you don’t need as large of a dataset as you would for pretraining,” explains Shaaban, a PhD student in Machine Learning at MBZUAI and lead of the study presented at MICCAI. “But the data needs to be relevant.”
How MOTOR works
When a user prompts a vision-language model with MOTOR, the system retrieves similar images and their corresponding medical data. The clinical relevance of this retrieved data is enhanced through the application of what are known as grounded captions. These are text descriptions that describe specific areas in the image. For example, in an X-ray of a patient with pneumonia, a bounding box is applied to the area of the lung with the disease along with a corresponding text caption. MOTOR also uses optimal transport to rank the retrieved data, which improves the reasoning capabilities of the vision-language model.
For the external database, the researchers used MIMIC-CXR-JPG, which contains chest X-ray images paired with detailed reports from radiologists.
Shaaban’s first attempt to build MOTOR used a vision-language model to generate ungrounded captions for the medical images. But the captions weren’t as detailed as they needed to be. Grounded captions are more specific, helping the model focus on the most relevant regions of the image.
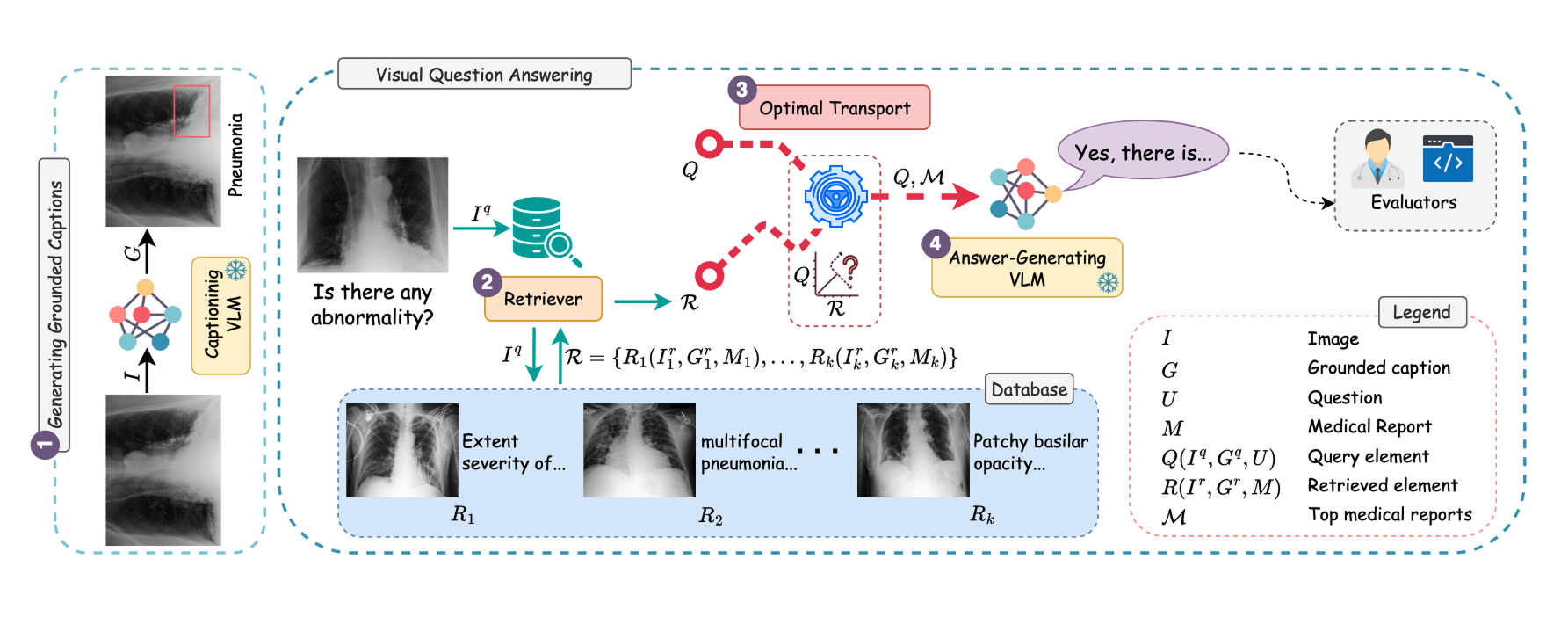 MOTOR, developed by researchers at MBZUAI and other institutions, combines retrieval-augmented generation and an algorithm called optimal transport to improve the performance of vision-language models on medical image analysis.
MOTOR, developed by researchers at MBZUAI and other institutions, combines retrieval-augmented generation and an algorithm called optimal transport to improve the performance of vision-language models on medical image analysis.
This is the first time that a RAG framework has been used together with multimodal reranking to provide additional text and visual context to a vision-language model in the medical field.
Previous research used other methods, such as cosine similarity, a standard algorithm, to retrieve related context for models. But Shaaban explains that in this case she and her colleagues needed an approach that was “deeper” than traditional algorithms to make sure that the information they retrieved was appropriate.
The researchers focused on X-rays because they had access to a dataset that had both X-rays and corresponding medical labels. But MOTOR could be tailored to work on any medical dataset that includes images and textual labels.
Results and next steps
The researchers tested MOTOR on two medical datasets and found that it outperformed other standard and RAG methods. It improved performance on the MIMIC-CXR-VQA test dataset by 3.77% and on the Medical-Diff-VQA dataset by 9.12%.
They also showed the grounded captions that were produced by MOTOR to a radiologist and found that 74% of the captions were accurate. And through manual analysis of a subset of samples they found that their system made accurate predictions more than 98% of the time.
For Shaaban and her team, using AI in healthcare isn’t just about developing an innovative algorithm. “It’s about how we deploy a system in a clinical setting that can benefit all of society,” she says. To do this successfully requires thoughtful consideration of the contexts in which systems will be used, who will use them, and the resource constraints that are found in clinical environments.
“I’m interested in using practical techniques so that models can be deployed without huge computational resources and large-scale datasets,” she says. “In underdeveloped regions where data is scarce, we are going to need to use techniques like RAG.”
- conference ,
- MICCAI ,
- vision-language models ,
- imaging ,
- medical images ,
- RAG ,
Related

AI researchers in Abu Dhabi are rewriting the rules of medicine across every stage of life
On World Health Day, MBZUAI showcases how artificial intelligence is transforming healthcare, from predicting Alzheimer’s years in.....
- World Health Day ,
- health ,
- AI ,
- healthcare ,

How reinforcement learning can help medical AI systems reason like a doctor
MBZUAI researchers received an NVIDIA Academic Grant for MediX-R1 – a framework that fine-tunes multimodal language models.....
- reinforcement learning ,
- grant ,
- reasoning ,
- medical ,
- healthcare ,

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More