
Making computer vision more efficient with state-space models
Wednesday, June 11, 2025

For over a decade, two deep-learning-based approaches have dominated the field of computer vision. In 2012, researchers at the University of Toronto developed a convolutional neural network (CNN) called AlexNet that dramatically outperformed other systems at the popular image classification competition known as ImageNet. Years later, researchers at Google introduced the vision transformer (ViT), an architecture that has been incorporated into many computer vision systems.
CNNs excel at identifying local features in images such as edges and textures of objects. ViTs divide images into patches and use a method called self-attention to compute the relationships between patches, allowing the model to identify what are known as long-range dependencies in images. This ability, however, comes with the cost of quadratic complexity, making ViTs computationally expensive.
Recently, researchers have developed a new class of systems known as state-space models (SSMs) that have the potential to improve on both approaches. Like ViTs, SSMs capture long-range dependencies, but they do so with linear scaling, which can lead to significant gains in efficiency.
One limitation of SSMs, however, is that the number of parameters of these systems is proportional to the number of input channels, explains Abdelrahman Mohamed Shaker, a recent Ph.D. graduate in computer vision from MBZUAI. And in some cases, scaling up SSMs to improve their performance on visual recognition tasks has instead resulted in decreased performance, as larger SSMs are difficult to optimize.
Shaker and colleagues from MBZUAI and other institutions recently developed a new set of SSMs that are designed to address these limitations. In tests on benchmark datasets, their systems, collectively called GroupMamba, performed as well as similar SSM systems but did so much more efficiently.
“By improving the performance of SSMs, we hope to combine the global modeling capabilities of vision transformers with the efficiency of CNNs,” Shaker says.
GroupMamba will be presented at the upcoming Computer Vision and Pattern Recognition Conference (CVPR) held in Nashville, Tennessee. Syed Talal Wasim, Salman Khan, Juergen Gall, and Fahad Shahbaz Khan are co-authors of the study.
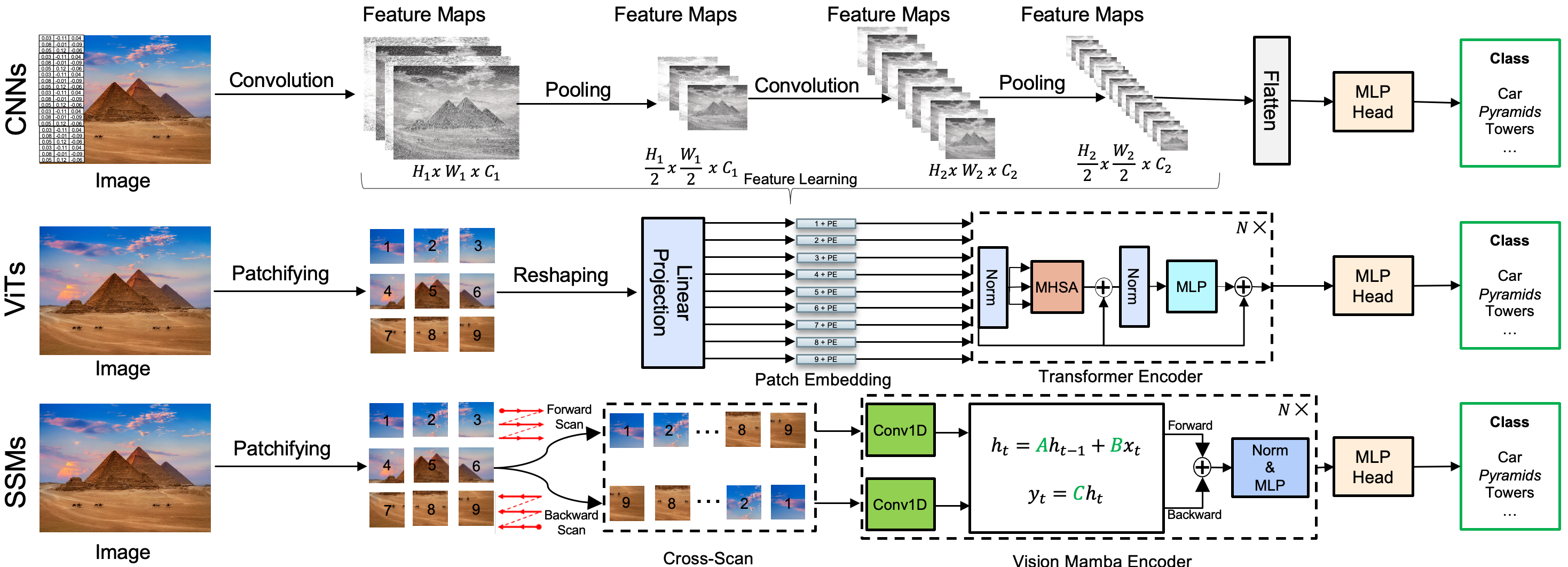
Figure shows the evolution of deep-learning-based visual recognition models from convolutional neural networks (CNNs) to vision transformers (ViTs) to state-space models (SSMs).
Making SSMs more stable
Overall, Shaker describes GroupMamba as “a backbone that can be used for different computer vision tasks, including image classification, object detection, and semantic and instance segmentation.”
He and his coauthors expanded on another SSM called Mamba, developed by researchers at Carnegie Mellon University and Princeton University. Shaker’s team built a new layer called modulated group mamba that addresses the computational inefficiencies and stability challenges that have been associated with other SSMs.
GroupMamba divides the input feature maps into four groups and scans them in four spatial directions, which helps the system model both local and global features efficiently. Each of these four scans are passed to visual single selective scanning (VSSS) modules that analyze the image from the four different directions — left to right, right to left, top to bottom, and bottom to top.
“The main idea of dividing the feature maps into four groups and scanning the image in different directions and combining them is to encode a global representation in an efficient way,” Shaker says. “This reduces the computational complexity, particularly the number of parameters, compared to a standard vision Mamba layer.”
The researchers then add a what they call a channel modulation operator, which helps the system coordinate and exchange information across the four VSSS modules after the individual scans are done to enhance the interaction of the feature maps.
The researchers also introduced a distillation-based training method that is designed to stabilize training of large models. With this approach, they use an established system, called a teacher model, to guide the training of their own. This helped to prevent the performance of their own model from degrading as it became larger.
Comparing GroupMamba to other systems
Shaker and his colleagues tested their GroupMamba systems on benchmark datasets and compared their performance others. Overall, they found that their models “demonstrate better trade-off between accuracy and parameters” when compared to the others, which included CNN-, ViT-, and SSM-based systems.
One of their smallest models, GroupMamba-T (1D scanning), performed similarly to another SSM model of the same size (Vmamba-T V2) on the ImageNet-1k dataset, but processed images nearly twice as fast. It also beat similarly sized CNN- and ViT-based models in terms of accuracy.
Another version, GroupMamba-S, achieved an accuracy of 83.9% on the dataset and was slightly better than another system, LocalVMamba-S, but had 34% fewer parameters.
Additionally, GroupMamba-B achieved an accuracy of 84.5% with 57 million parameters, outperforming another model, VMamba-B, by 0.6% while using 36% fewer parameters.
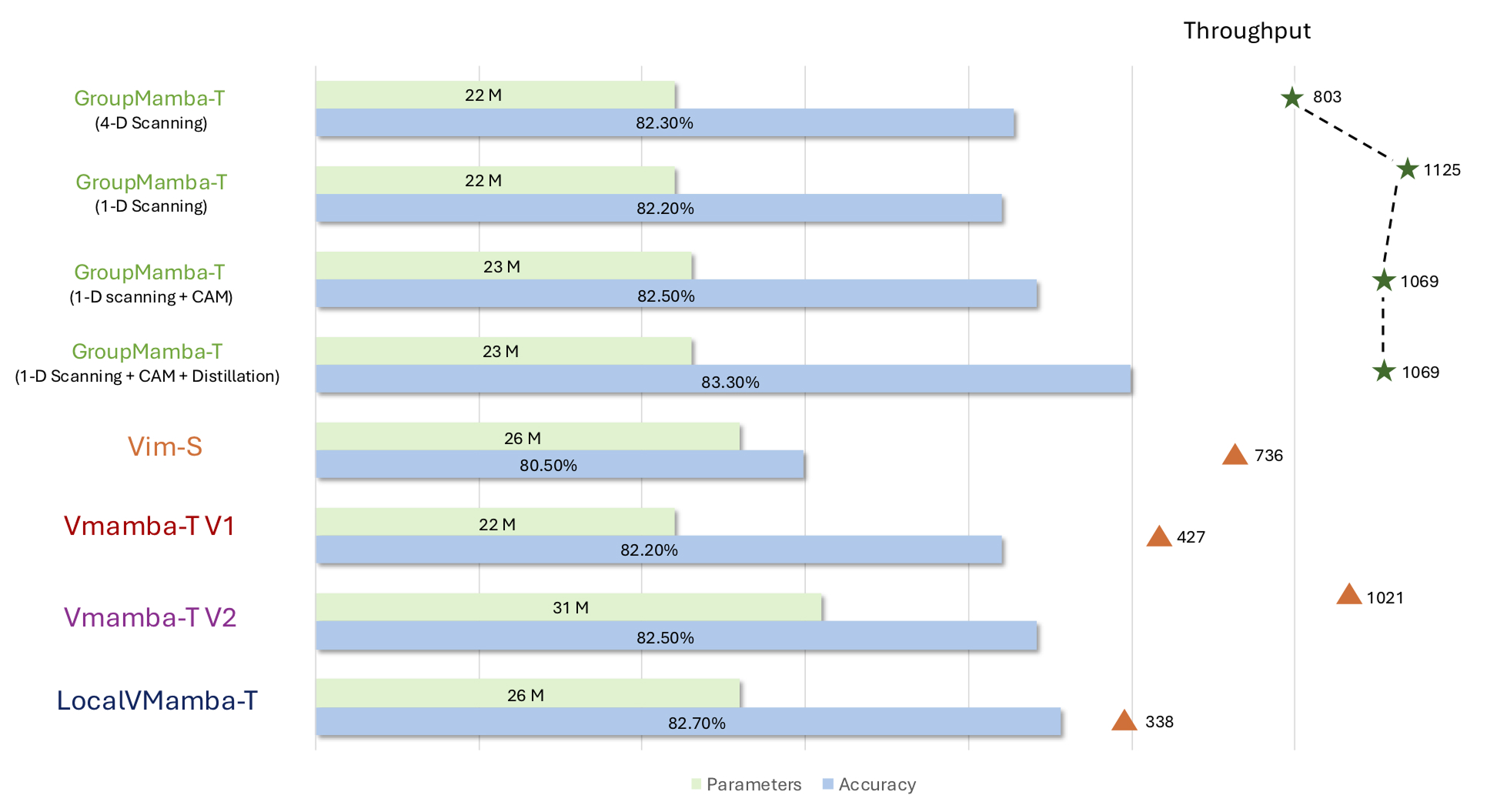
Versions of GroupMamba compared to other SSMs in top1 accuracy (blue) on the ImageNet-1k dataset along with size of the models in terms of parameters (green). Throughput is the number of images the models process per second using a single Nvidia A100 GPU with a batch size of 128 for all methods.
The future of SSMs
Due to their capability to model long-range dependencies efficiently, Shaker says that there is significant potential for SSMs in domains such as medical imaging and satellite imagery, where ultra-high-resolution data (such as 4K and 8K images) are common. “These images often exceed the processing capabilities of traditional vision transformers, whose self-attention mechanism scales quadratically with input size,” he explains. “In contrast, SSMs offer linear-time complexity and better memory efficiency, making them well-suited for analyzing large-scale spatial data without compromising resolution or context.”
What’s more, in the same way that transformers have been used to power both computer vision systems and large language models, SSMs could be employed for natural language processing tasks that require analysis of huge portions of text. “If you want to process a book and not just a document and you need a longer context window, SSMs could be a solution because they have the potential to process very long pieces of text efficiently,” he says.
Shaker plans to continue to develop new approaches to for efficient computer vision systems in the coming academic year as a postdoctoral associate at MBZUAI.
- computer vision ,
- deep learning ,
- dataset ,
- Ph.D. ,
- CVPR ,
- optimization ,
- benchmark ,
- SSMs ,
Related

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More
MBZUAI and Minerva Humanoids announce strategic research partnership to advance humanoid robotics for applications in the energy sector
The partnership will facilitate the development of next-generation humanoid robotics tailored for safety-critical industrial operations.
Read More
AI and the silver screen: how cinema has imagined intelligent machines
Movies have given audiences countless visions of how artificial intelligence might affect our lives. Here are some.....
- cinema ,
- art ,
- science fiction ,
- fiction ,
- AI ,
- artificial intelligence ,