
Identifying bias in generative music models: A new study presented at NAACL
Monday, April 28, 2025

Generative music-language models hold the potential to help musicians and composers reduce production costs and speed up composition. The current performance of these systems, however, varies widely across styles, explains Atharva Mehta, a research associate at MBZUAI.
Very little of the music that has been used to train generative music systems comes from genres from outside the Western world. Indeed, in a recent study, Mehta and other researchers from MBZUAI found that only 5.7% of music in existing datasets comes from non-Western genres, limiting their performance in these styles. The researchers also tested whether a technique called parameter-efficient fine-tuning with adapters could improve generative music systems on underrepresented styles.
Mehta and his colleagues are presenting their findings at the upcoming Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), which will be held in Albuquerque, New Mexico at the end of April.
Shivam Chauhan, Amirbek Djanibekov, Atharva Kulkarni, Gus Xia, and Monojit Choudhury of MBZUAI contributed to the study.
Exploring dataset bias
Mehta has long held an interest in music and has been exploring the relationship between culture and AI music generation systems while at MBZUAI. “There is a clear demarcation in the music generation landscape, with the Global North very well represented, and the Global South poorly represented,” he says.
His goal is to develop ways to make generative music systems more inclusive of a wide diversity of genres, as there are millions of listeners of non-Western styles who may benefit from generative music applications.
Mehta and his colleagues conducted a survey of current datasets that have been used to train generative music systems and focused on a collection of datasets that together include more than 1 million hours of music. They found that nearly 94% of the music in these datasets represented music from the Western world, with only 0.3% coming from Africa, 0.4% from the Middle East, and 0.9% from South Asia.
The researchers explain that due to this imbalance, generative music systems rely on conventions of Western music, like tonality and rhythmic structures, even when they are prompted to generate Indian or Middle Eastern music.
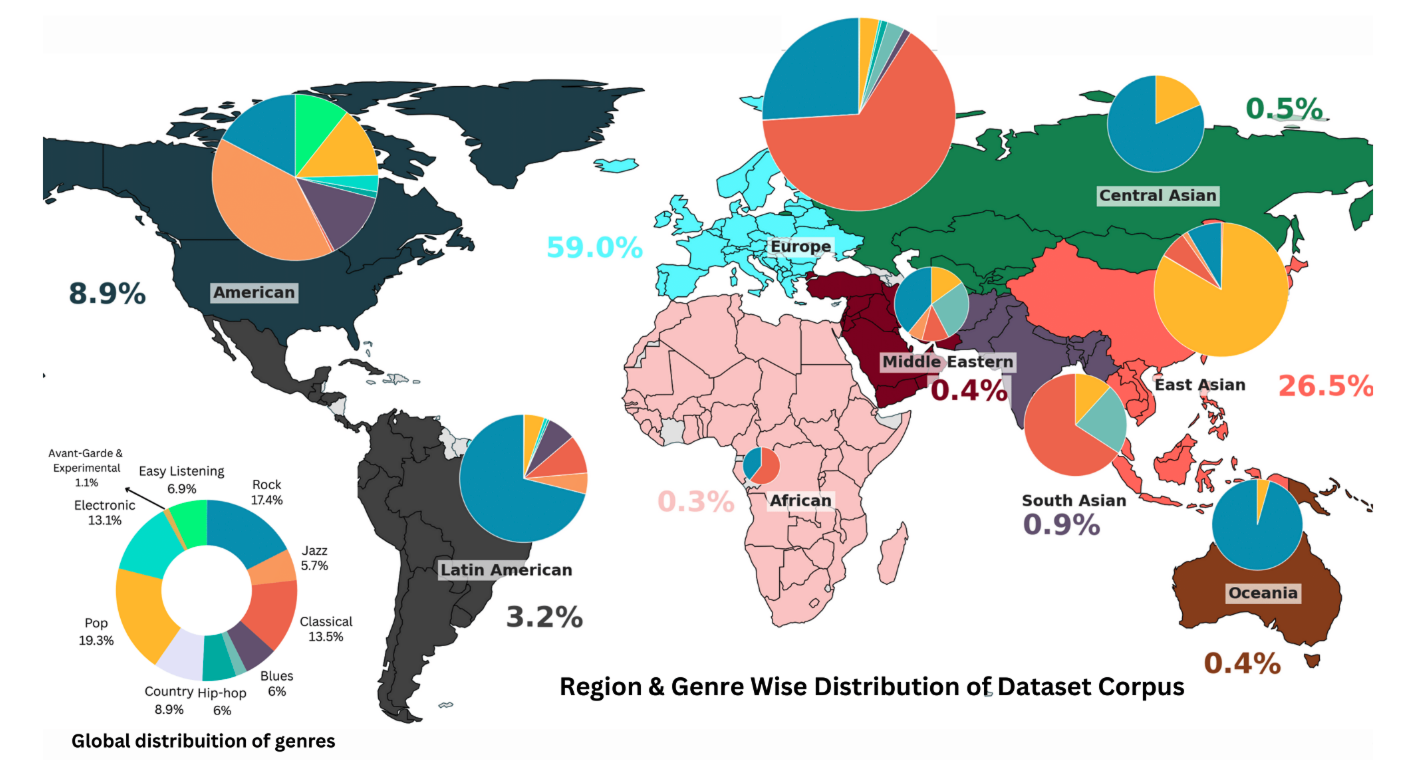
A survey of current music datasets found that styles from much of the world are underrepresented, with 94% of training data coming from Western genres.
Improving performance with fine-tuning
In addition to identifying this significant gap in representation, Mehta and his colleagues explored if they could improve the performance of generative music systems on non-Western genres using a technique called parameter-efficient fine-tuning with adapters.
Adapters are a common technique in natural language processing to improve the capability of systems on specific languages or tasks, but this was the first time the technique had been applied to generative music applications. Adapters are essentially smaller models that are fine-tuned on specific kinds of data and appended to larger models. The approach takes advantage of the general capabilities of the larger model while benefiting from the specialization added by the adapter.
The team focused on two musical styles: Hindustani classical and Turkish Makam. They chose them because they follow specific melodic and rhythmic structures that clearly distinguish them from Western styles like rock and pop.
They also studied two generative music systems: MusicGen and Mustango. They developed adapters that could be added to these systems and fine-tuned the adapters on a Hindustani classical dataset called MTG Saraga and Turkish Makam dataset called Dunya.
They divided the datasets into groups for training and validation, resulting in nearly 18 hours of training data for Hindustani classical and over 97 hours for Turkish Makam. The adapters were small in relation to the MusicGen and Mustango base models, representing just 0.1% of the total model parameters.
What the experiments revealed
The researchers evaluated the baseline and fine-tuned MusicGen and Mustango models on both genres. They used a system that measured what are known as “objective metrics” by comparing generated music to the validation set and found that the fine-tuned Mustango system performed best on seven of eight metrics.
They also had people who were familiar with the two styles of music evaluate the systems’ outputs according to a framework adapted from Bloom’s Taxonomy, which evaluates recall, analysis, and creativity in musical output.
They found that the Mustango fine-tuned model improved by 8% on Hindustani classical and the MusicGen fine-tuned model improved by 4% on Turkish Makam. Fine-tuning helped Mustango on Hindustani Classical, notably improving melody capture, but hurt its performance on Turkish Makam, reducing creativity. MusicGen, in contrast, saw only minor gains and inconsistent results after fine-tuning.
And while parameter-efficient fine-tuning made the systems better at Hindustani classical and Turkish Makam, Mehta says that the models’ ability in Western genres began to get worse. “We found that the models would start to forget what they had learned previously,” Mehta says.
Overall, the adapters led to moderate improvements in some cases but also revealed limitations in modifying models that are primarily trained on Western music to non-Western styles. “This process of improving these systems in non-Western styles isn’t as trivial as simply adding an adapter,” Mehta says.
The team’s findings suggest that fixing the imbalance in training data, not just modifying them through fine-tuning, will be essential to making generative music tools more accessible and inclusive.
Mehta says that, in the future, he and his colleagues will continue to advance inclusivity in AI-generated music by addressing gaps in music generation datasets, enhancing model adaptability to diverse musical styles, and developing evaluation methods that are both genre-inclusive and sensitive to core musical attributes.
- generative AI ,
- NAACL ,
- culture ,
- music ,
Related

Foundational research in the age of AI
The inaugural Dean of MBZUAI's Computing and Mathematical Science Division, Éric Moulines, explains why fundamental research remains.....
- computing ,
- research ,
- mathematics ,
- education ,
- Dean ,

The watermark that wasn't there
A new technique from MBZUAI researchers removes AI image watermarks in seconds – exposing potential weaknesses in.....
- watermark ,
- watermarking ,
- CVPR ,
- computer vision ,

Commencement 2026: Opening the black box of AI
As AI systems grow more human-like, their internal logic remains largely hidden. MBZUAI graduate Chenxi Wang is.....
Read More