
Create and edit images like a smart artist
Monday, July 21, 2025

Ask Midjourney or DALL-E to add a crown on a text‑to‑image rendering of a dog and you’ll likely get an entirely new image: different poses, new background, maybe even another dog is generated
“We kept seeing that kind of drift,” say Shaoan Xie and Lingjing Kong, Ph.D. students at Carnegie Mellon University and Mohamed bin Zayed University of Artificial Intelligence. “One tiny word in the prompt can snowball into a completely different picture.”
That loss of control is more than an annoyance for digital artists. It limits AI’s usefulness in industries such as advertising or medicine, where small, targeted tweaks matter. Xie and Kong’s new research, which was presented at the International Conference on Machine Learning (ICML) last week, promises a fix. The paper lays out both a mathematical theory of ‘atomic concepts’ and a working prototype called ConceptAligner that together make it possible to create and edit an image precisely, without collateral damage.
Modern image generators translate a text prompt into a high‑dimensional ’embedding,’ then iteratively de-noise random pixels until a picture forms. The hitch: those embeddings are entangled: the vectors that encode ‘a dog wearing diamond crown’ and ‘a dog wearing floral crown’ can be very different and influence the output images in an unpredictable way.
Their solution is to decompose text embeddings into independent building blocks they call atomic concepts. Think of the two sentences: ‘a dog’ is shared across the two prompts and only the crown is changed. If we are able to disentangle such changes and represent the changes with a minimal number of tokens and connections between text and visual concepts, we are able to edit the crown without affecting the whole image. The heart of the paper is a set of two conditions that prove when such disentanglement is identifiable: math‑speak for ‘recoverable in principle, not just in practice.’
The first condition intuitively requires a certain degree of diversity in the data: the existence of a large collection of high-level concepts like ‘cats’ to ‘dogs’ could aid us in distinguishing the low-level, visual concepts ‘eyes’ and ‘noses’ which exhibit different patterns of changes.
The second condition adds a sparsity requirement: each text concept can influence only a limited subset of visual concepts. Without that sparsity, disentanglement collapses.
The payoff is component‑wise identifiability, meaning every latent factor – color, pose, material – maps to exactly one dial the user can turn. That’s a big leap from earlier work, which could identify only coarse bundles of features, not the individual atoms. With such atomic identifiability, user edit prompts (like ‘add a diamond crown ‘) can be translated into accurate concept-level modifications, enabling precise and controllable generation.
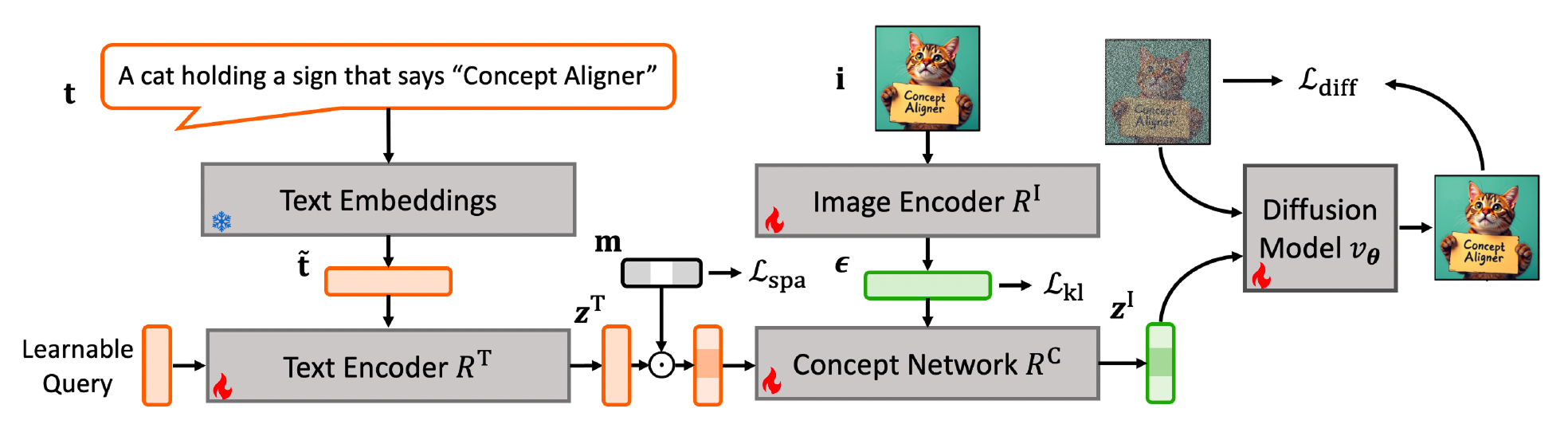
Building ConceptAligner
Theory in hand, the team engineered a four‑part system:
- Text Network is a Perceiver‑resampler module that converts the raw text embeddings into 64 atomic text concepts.
- Image Encoder recovers a noise variable that captures everything text can’t explain.
- Concept Network learns sparse links between words and pixels; a mask enforces the graph required by the theory.
- Diffusion Transformer is a LoRA‑tuned generator that treats the disentangled visual concepts as its conditioning vector, not the messy original prompt.
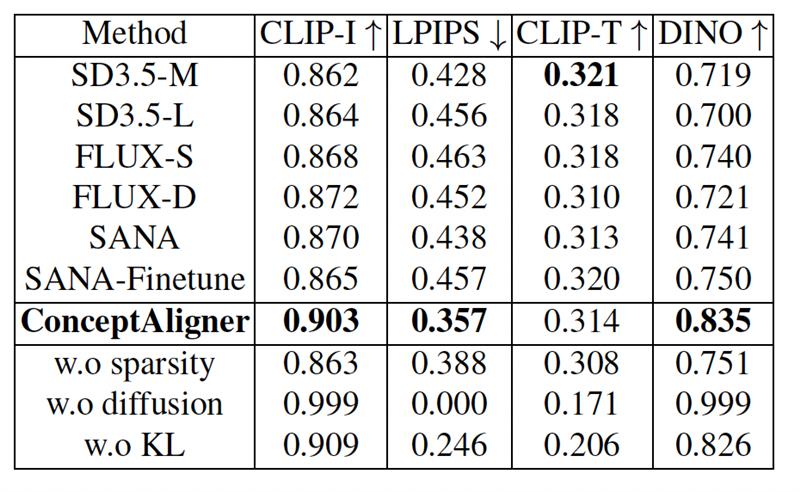
On the Emu‑Edit benchmark (a collection of 3,589 prompt pairs such as ‘a smiling dog’ → ‘a surprised dog’) ConceptAligner beat Stable Diffusion 3.5 and six other state‑of‑the‑art image generation systems on every controllability metric:
Visual tests tell the story. Swap “diamond crown” for “flower crown” on a Labrador, and rival models repaint the shop sign behind the dog. ConceptAligner changes only the headgear.

Thanks to the identifiability of the atomic concepts, we are able to use a compact representation for the user prompts instead of a long entangled pre-trained text embedding. Consequently, ConceptAligner renders edits in seconds. “That near‑real‑time feedback completely changes the creative loop,” Xie and Kong say. Imagine a comic artist nudging a character’s eyebrow, or a fashion designer iterating on fabric patterns, all without the roulette wheel of unintended changes.
ConceptAligner also has applications beyond pretty pictures.
- Medical imaging: Converting CT scans to PET without warping anatomy could aid diagnosis. One concept dial changes modality; the rest stay frozen.
- Robotics: “Grasp the red handle, not the blue panel” becomes a solvable vision task when color and shape are disentangled.
- Accessibility: Tools that raise text contrast or highlight edges can do so selectively, improving readability without destroying context.
The model still stumbles on low‑resource languages and highly abstract prompts. “If the concept never shows up in the training data, we can’t isolate it,” Xie and Kong admit. Celebrity likenesses are especially thorny because a star’s identity – hair, eyes, style – is itself an entangled concept.
Then there’s misuse. Perfect control makes deepfakes easier. The team favors robust NSFW filters, consent requirements for editing real faces, and possibly watermarking edits—though watermark robustness is its own arms race.
The team is already eyeing video. Temporal consistency means a ‘dog’ must stay the same identity across frames, and the temporal information itself becomes another useful tool for disentangling concepts in video data. Interactive storytelling is the dream: align text, image, and audio atoms so a single voice command can spin a cohesive, multimodal tale.
They’re also planning a public platform with larger foundation models baked in. “We want anyone, even on a modest laptop, to say ‘make this photo moodier’ and watch it happen instantly,” Xie and Kong say.
AI art once felt like stage magic: powerful but unpredictable. These atomic concepts turn it into something closer to a digital synthesizer – every knob labeled, every effect intentional. If the theory scales, the days of accidental ducks could soon be behind us.
- machine learning ,
- computer vision ,
- nlp ,
- icml ,
- text to image ,
- prompting ,
- image generator ,
Related
Building an AI model that actually speaks Hindi
MBZUAI’s Nanda models for Hindi and English show that effective multilingual AI depends on cultural and linguistic.....
- culture ,
- natural language processing ,
- nlp ,
- language ,
- IFM ,
- Institute of Foundation Models ,
- Nanda ,
- Hindi ,

AI models are becoming cultural archives
MBZUAI research shows how language models encode cultural knowledge — and how unevenly they express it across.....
- culture ,
- language ,
- EACL ,
- llms ,
- conference ,
- nlp ,
- research ,
- natural language processing ,

When disagreement becomes a signal for AI models
Research from MBZUAI and Melbourne offers new metrics and training approaches that aim to better align AI.....
- language ,
- labels ,
- human judgment ,
- Computational linguistics ,
- benchmark ,
- nlp ,
- research ,