
Can LLMs reason? New benchmark puts models to the test
Thursday, March 20, 2025

Language was once thought to be a uniquely human ability — at least until large language models (LLMs) came along. Today, scientists are working to advance AI’s abilities beyond language by developing specialized systems known as “reasoning models” that are designed to tackle complex problems. Just as LLMs challenged our understanding of what it means for humans and machines to use language, these new models aim to replicate another capability long thought to belong only to us — reasoning.
At a basic level, reasoning models are designed to work through problems rather than simply predict a response. They use various methods do this, such as chain-of-thought, which breaks down complex questions into smaller and easier-to-answer parts, and self-evaluation, which allows a model to evaluate the quality of its own outputs.
To better understand the ability of LLMs to reason, scientists from MBZUAI and other institutions recently created a benchmark dataset that uses simple, text-based games to test them. The researchers call their dataset TextGames, and it requires skills like pattern recognition, spatial awareness, arithmetic, and logical thinking. While the games included in the dataset aren’t particularly difficult for people, they proved to be challenging for LLMs.
Most of the models tested on TextGames were unable to solve the hardest questions. “This finding is particularly interesting given that recent research suggests LLMs exhibit intelligence seemingly on par with humans,” said Alham Fikri Aji, assistant professor of natural language processing at MBZUAI and co-author of the study.
Frederijus Hudi, Genta Indra Winata and Rouchen Zhang are also co-authors. All authors contributed equally.
What is reasoning?
The concept of reasoning is difficult to define and has been used by AI researchers in different ways. Aji and his co-authors describe reasoning as a “multifaceted ability that involves understanding the context and effectively exploring and testing potential solutions that fit the constraints to solve problems.”
In the past, AI researchers have tested models’ abilities to reason by asking them to answer exam questions, like those high school students take in standardized settings. A limitation of this approach, however, is that it’s possible that models have been exposed to question-and-answer pairs during training, as many models are thought to have been trained on all the publicly available data on the Internet. When this is the case, a model could answer correctly without reasoning, simply by recalling the answer from memory.
A key aspect of reasoning is that it requires generalization to new situations rather than relying purely on memorization. With TextGames, Aji and his colleagues created many different and new iterations of game scenarios that models couldn’t have seen before. “We were able to randomize the games in our dataset,” creating brand new game scenarios, Aji said.
Details of the dataset
TextGames is made up of eight puzzle games in three different levels of difficulty. It includes a password game in which the player needs to compose passwords that fit certain criteria, such as using upper- and lower-case letters, numbers, and special characters. It includes a game called Anagram Scribble in which the player is given a set of Latin characters and is asked to arrange them into an English word that contains a certain number of characters. And it includes text Sudoku, where the player is asked to fill blank cells with numbers so that no identical numbers appear within the same row, column or subsection of the grid. Some of the games, like the password arranger, work in one dimension, while others, like Sudoku, work in two.
Aji and his team generated 24,000 test samples and created a few samples for training. Since the researchers’ intention was to test the models in zero-shot and few-shot contexts, it was not necessary to provide a training split for this dataset.
The researchers wanted to see if the LLMs could improve their performance using self-evaluation and another technique called self-reflection, which refers to a model’s ability to analyze its decision-making process. During testing, models were able to attempt up to three solutions to each question and used a system called a grader to verify the accuracy of their responses.
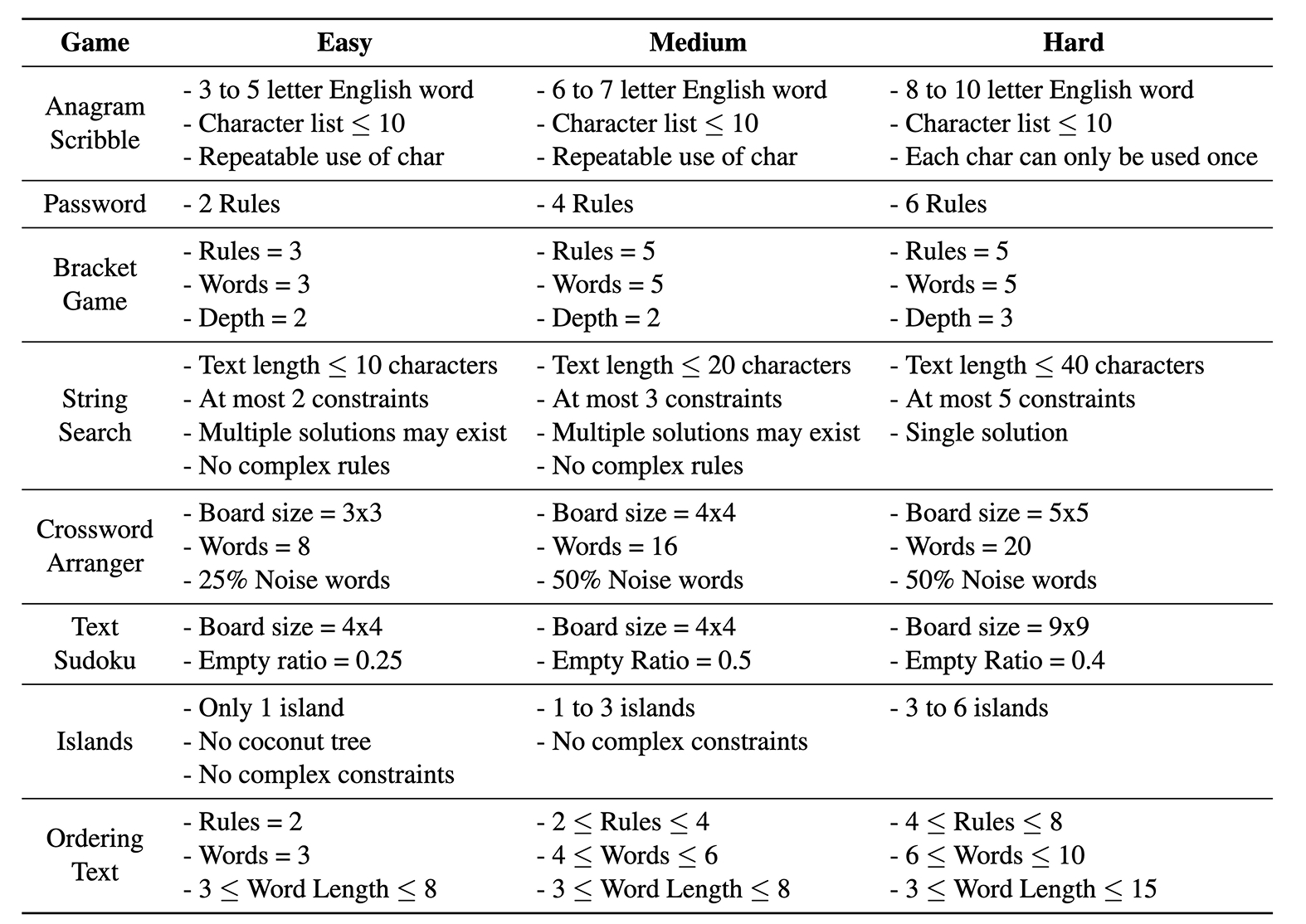
The TextGames dataset includes 24,000 test questions that span eight games and three levels of difficulty.
Models and results
Aji and his colleagues compared “instruction-following models,” like Meta’s Llama and Alibaba’s Qwen, with models that have been specifically designed for reasoning, such as OpenAI’s GPT-4o Mini and GPT-o3 Mini.
Most of the models had difficulty solving even the easiest questions. GPT-o3 Mini was the most accurate, but it received high marks only on a subset of games. While the instruction-following models were able to answer some easy and medium questions correctly, they were unable to come up with the right answers on hard questions. The 2D puzzles also proved to be much more difficult than the 1D puzzles.
On the easy 2D questions, all the models (except for GPT-o3) struggled to surpass 50% accuracy after three attempts. On the medium 2D questions, they were unable to do better than 20% after three attempts. No model, except for GPT-o3 Mini, achieved an accuracy score above 4% on the 2D puzzles, even after three attempts.
GPT-o3 Mini answered 78% of hard 1D questions correctly after three tries and 48.6% of hard 2D questions after three tries.
Overall, larger models typically performed better than smaller models, but model size didn’t seem to make much of a difference on more complex tasks, like those requiring reasoning in two dimensions. Perhaps unsurprisingly, with more attempts, the models got better.
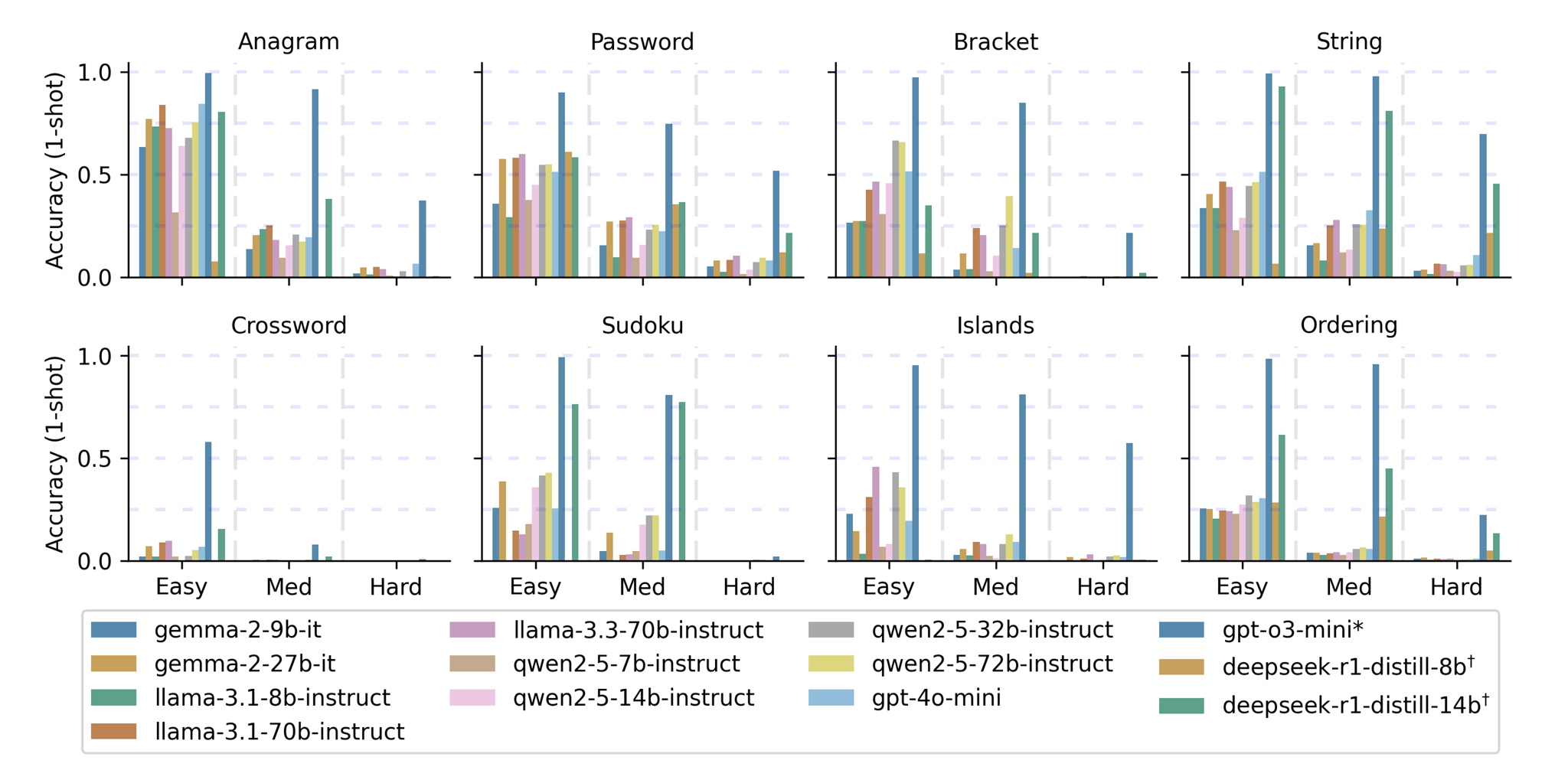
OpenAI’s GPT-o3 Mini, a reasoning model, performed the best on the TextGames dataset. The figure above shows one-shot performance of each model studied across eight games and three levels of difficulty.
Taking the time to think
It’s generally thought that a model’s performance will increase as it spends more time on inference — a phenomenon known as test-time scaling. But Aji and his colleagues found that there were diminishing returns spending more time on inference for TextGames, particularly on the most difficult questions. They also observed that increasing inference time didn’t improve the performance of the best performing model, GPT-o3 Mini.
Aji and his co-authors write that a model “may become confused by its own extended reasoning, resulting in over complicated solutions or incorrect understanding.” Because GPT-o3 Mini is a closed-source model, they couldn’t gain insight into its reasoning process. But with an open-source model they also tested, DeepSeek’s R1, they saw that while the model might provide a correct answer on its first try, it had the tendency to overthink and subsequently turn a good response into a bad one.
Aji noted that it’s also important to consider the cost of increased time spent on inference: “The longer you’re reasoning, the more expensive it gets.”
Machine v. human
Aji and his team compared the performance of the LLMs to humans. To do this, they built a web application that allowed human testers to solve the same problems from the dataset while capturing information like time to completion and solve rate.
While humans had the tendency to make careless mistakes, given enough time and attempts, they were generally able to answer all the questions, even the hardest ones, correctly. Most models failed to solve any hard problems.
This divergence in performance encourages Aji to consider how humans and machines may approach reasoning in different ways. “We do a lot of branching in our mind, we can think of different scenarios and choose a path that gets us to a solution,” he said. “LLMs can’t really do that because they have to generate text. They can’t plan ahead in the same way we do.”
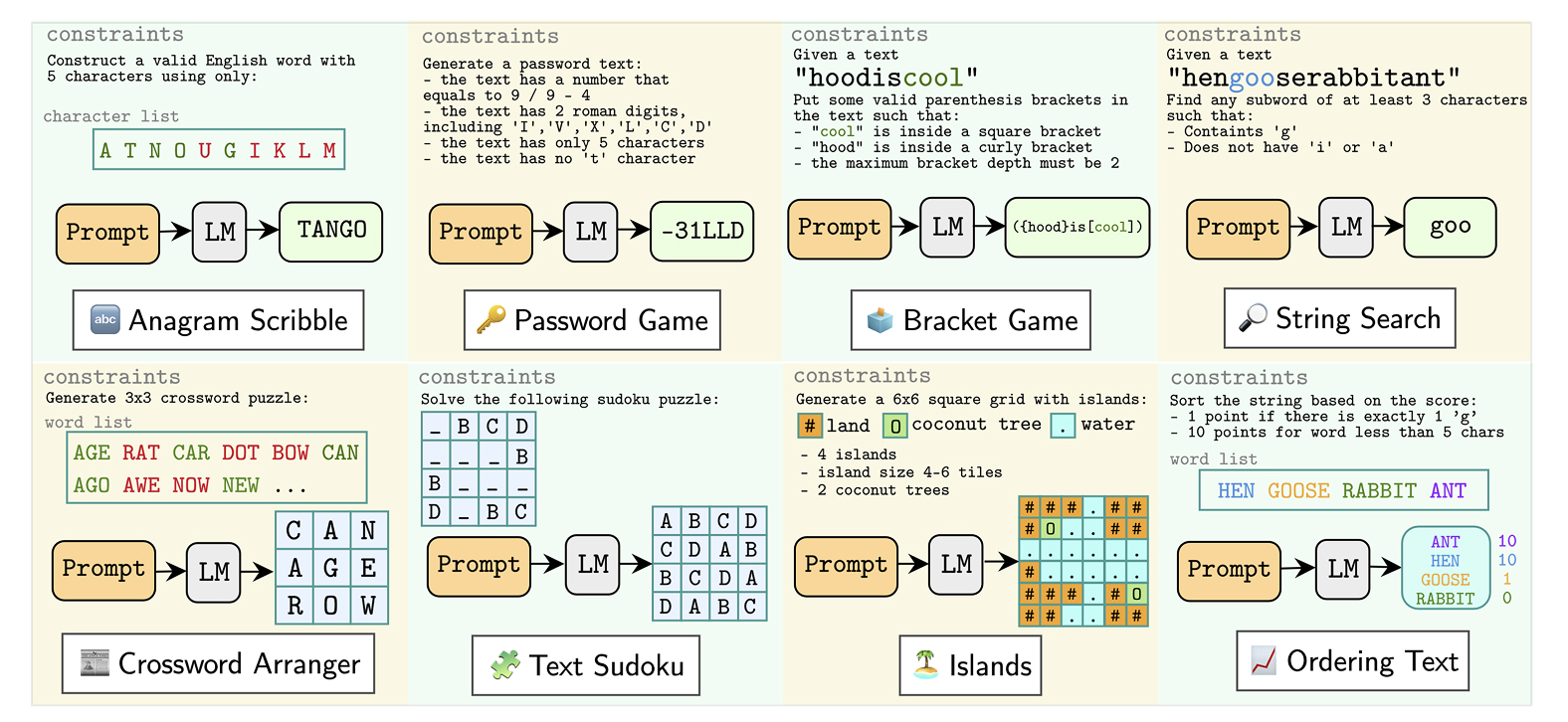
The eight games in the TextGames dataset. The games require the abilities of pattern recognition, spatial awareness, arithmetic, and logical thinking.
Thinking ahead
The results of the study show specific areas in which the reasoning abilities of LLMs can be improved. In the future, LLMs may be used to provide reasoning capabilities in robots, helping them plan and execute on commands. “We want to know if we can trust LLMs to do tasks that require reasoning,” Aji said.
Aji wonders if using LLMs for reasoning is the best approach because they may be limited by their need to reason through generating text. There is a long history in AI of scientists developing dedicated programs that can reason in the context of games, defeating even the best human players. Scientists have been able to build programs for games like chess and go that have beaten world champions; there’s no reason the same couldn’t be done for a game like Sudoku.
While LLMs will likely play an important role in advanced robotics, they might not be the only way to provide robots with the ability to reason. “Instead of forcing an LLM to solve reasoning problems, you could imagine an approach where an LLM calls on third-party modules that are designed for specific forms of reasoning and other tasks,” Aji said. “That could be a way forward.”
- research ,
- large language models ,
- dataset ,
- llms ,
- benchmark ,
- reasoning ,
- intelligence ,
Related

MBZUAI researcher continues journey to reshape AI for global languages
Former MBZUAI researcher Atnafu Lambebo Tonja has been appointed Google DeepMind Academic Fellow at the UCL, where.....
- DeepMind ,
- low-resource languages ,
- researcher ,
- postdoc ,
- fellowship ,
- language ,
- nlp ,
- research ,
Building an AI model that actually speaks Hindi
MBZUAI’s Nanda models for Hindi and English show that effective multilingual AI depends on cultural and linguistic.....
- natural language processing ,
- nlp ,
- Hindi ,
- language ,
- Nanda ,
- Institute of Foundation Models ,
- culture ,
- IFM ,

AI models are becoming cultural archives
MBZUAI research shows how language models encode cultural knowledge — and how unevenly they express it across.....
- conference ,
- culture ,
- language ,
- EACL ,
- llms ,
- nlp ,
- research ,
- natural language processing ,