
A new stress test for AI agents that plan, look and click
Monday, August 25, 2025

A team of MBZUAI researchers have won second place at the AgentX Competition hosted by UC Berkeley for their new benchmark that measures the ability of agents to think and act across images, multi-image comparisons, and video while invoking external tools.
Presented at Berkeley’s Agentic AI Summit in August, the prize recognized the team’s efforts to prove that today’s best multimodal agents – systems that read, watch, browse, and call tools – still break in messy real-world workflows.
The research paper, ‘Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks’, featured in the competition’s Planning and Reasoning track. Its lead authors are MBZUAI research engineers Tajamul Ashraf and Amal Saqib, with contributions from MBZUAI colleagues Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Fahad Shahbaz Khan, Rao Muhammad Anwer, and Salman Khan, as well as Mubarak Shah from the University of Central Florida, and Philip Torr from the University of Oxford.
You can see their code here.
A benchmark for doing, not just answering
Unlike typical agent evaluations that focus only on final answers, Agent-X analyzes their full reasoning trajectory, examining how they ground references in video frames, select tools, and structure arguments step by step.
The new dataset includes 828 tasks across images, multi-image comparisons, and videos – spanning six domains, from visual reasoning and web browsing to security, autonomous driving, sports, and math.
Agents must solve these tasks using 14 executable tools including OCR, object counters, calculators and web utilities.
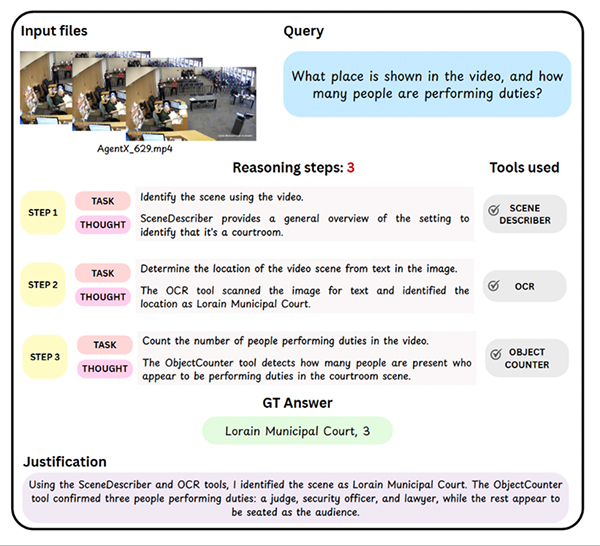
Example tasks from Agent-X, illustrating multimodal queries that require step-by-step reasoning, tool use, and visual understanding across images and video.
Queries deliberately avoid tool hints, to avoid unrealistic agentic language. Instead of saying ‘use OCR’, for example, queries use natural language commands, meaning the agent must infer whether a tool is needed; if so, which one; and with what arguments – mapping the three common failure points in the wild.

Task comparison of Agent-X with existing benchmarks. Unlike prior benchmarks, the queries in Agent-X avoid explicit references and direct instructions; encouraging agents to reason and act independently.
Agent -X is built via a semi-automated pipeline. large multimodal models draft tasks and traces, while human annotators fix ambiguity, enforce determinism, and align every step to evidence.
Looking at agent behavior through three lenses
Agent-X evaluates along three modes:
- Step-by-step: Can the agent ground its references, pick the right tool, and format valid arguments? Important metrics include: Grounding Score (Gs), Tool Precision (Tp), and tool accuracy (Ta).
- Deep reasoning: Is the chain coherent, faithful to tool I/O, and semantically complete? Metrics include: Faithfulness (Facc), Context Score (Cs), Factual Precision (Fp), and Semantic Accuracy (Sacc).
- Outcome: Did the agent solve the task and use the tools correctly overall? Metrics include: Goal Accuracy (Gacc), Goal Accuract w/ImgGen (G*acc), and Toolset Accuract (Tacc).
Lead author Tajamul Ashraf explains that the best predictor the real-world reliability isn’t the final answer, but the bundle Facc + Sacc from Deep Reasoning, combined with Ta/Tp from Step-by-Step.
Models that keep their rationale consistent with evidence, and call the right tools with valid arguments, break less under distributions shift. Outcome-only leaderboards can mask brittle, unreproducible paths.
Under 50% success rate – even for the best models
Despite the industry’s claim, no model cleared 50% Goal Accuracy on Agent-X. The top entry, o4-mini, reached 45%, while most open-source models scored less than 30%. Stronger chains (higher Facc or Sacc) correlated with better outcomes. For example, GPT-4o scored high on deep-reasoning metrics and translated that into comparatively higher task success. Bur the ceiling remained low. Challenges include grounding, tool use, and maintaining consistency throughout.
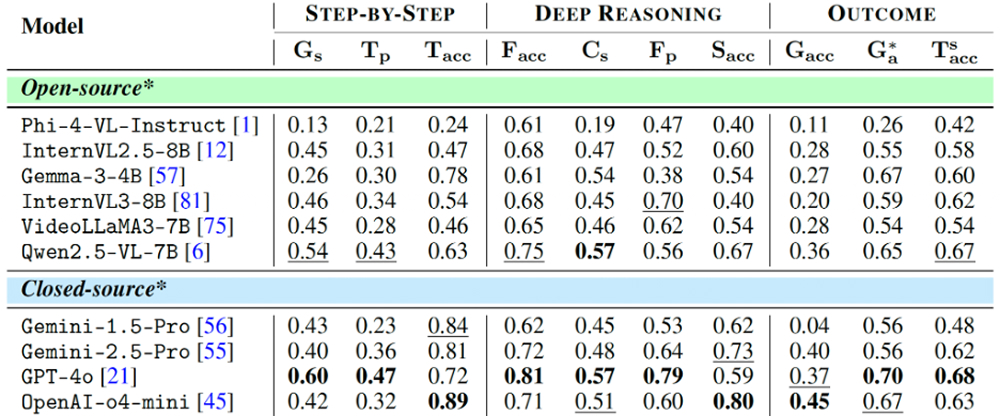
Overall results on Agent-X across a variety of open and closed source models.
The low performance reflects recurring errors: agents skip frame-by-frame video reasoning, hallucinate unregistered tools, violate JSON schemas, and bypass visual checks – producing factual mistakes. GPT-4o sometimes outputs polished by format-invalid traces, while VideoLLaMA struggles with temporal alignment.
Other errors involve spatial reasoning failures or inaction, which stem more from control-loop and interface flaws than model size. Even stronger models like GPT-5 may improve reasoning metrics, but meaningful gains in Goal Accuracy depend on schema-enforced tool calls and minimal retry policies.
The key to real world progress
According to Ashraf, moving from 45% to real-world deployable will require better contracts between models and tools. He advocates typed JSON schemas, strict validators, soft-error retries, and deterministic seeds for reproducibility.
Agent-X also shows agent personas matter: aggressive agents maximize recall but hurt argument validity, conservative agents underuse tools, while balanced agents perform best – especially with validators and retry policies. These insights focus on practical reliability rather than leaderboard scores.
Across modalities, video is the most brittle. Keeping track of ‘who is where’ across frames, handling occlusion, and aligning tool call to the correct time index routinely derails even flagship systems. Multi-image comparisons come second; weak cross-image coreference and sloppy attention hand-offs are common.
How Agent-X was built and why that matters
The curation pipeline for Agent-X is semi automated. Large multimodal models draft tasks, distractors, tool arguments, and evidence chains while humans refine them. This removes ambiguity, enforcing grounding, verifying tools, adjusting difficulty, and rewriting culturally sensitive content, resulting in deterministic, verifiable tasks with step-level traces.
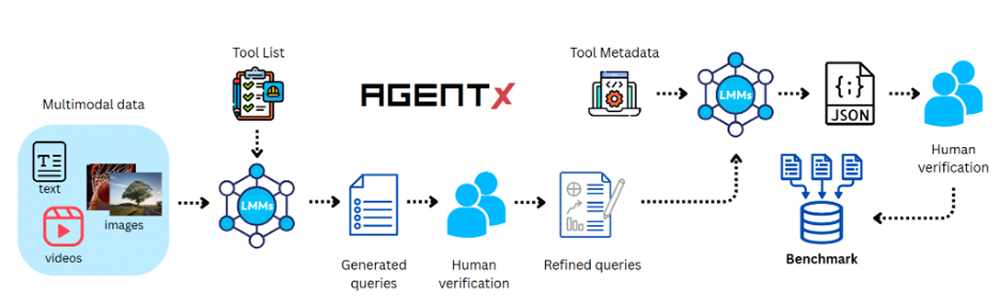
The Agent-X benchmark pipeline begins with multimodal data and a set of tools. An LMM generated initial queries that annotators refine for accuracy, then produces step-by-step reasoning that is polished into a high-quality, tool-augmented reasoning trace.
The human-in-the-loop step leads to the difference between a pretty dataset and a reliable test bench. The authors even built a small verification tool so annotators could align every tool I/O and final answer before a sample passes.
Because some answers are descriptive, Agent-X uses a mix of large language model-based judges (e.g., GPT-4o, Qwen) and humans. The top systems keep their relative order across judges; differences mostly appear on borderline cases. Humans are stricter on hallucinated justifications, while Qwen can be more tolerant of paraphrases but may under-penalize minor mistakes. To blunt ‘judge hacking’, the benchmark aggregates multiple judges where needed and hard-checks evidence for grounding.
Next steps: multilingual, longer horizons, real apps
Agent-X is currently monolingual, with a multilingual version planned – starting with Arabic and Spanish, and featuring localized scenarios and native-speaker annotation. Ashraf measures success pragmatically: predicting on-call incidents in production, targeting a 10–15 point rise in session success and a 50% drop in tool-argument errors through stricter typed I/O, temporal metrics, cost/latency tracking, and eval-as-a-service.
Unlike competitions that reward single numbers, Agent-X uses multiple metrics to reflect real-world workflows – spreadsheets, multi-camera security, video analysis, dynamic web forms. The lesson: agents fail due to fuzzy contracts with the world, not poor prose. Typed schemas, stricter judging, and action-focused evaluation could produce correct, ordered actions with solid reasoning.
- research ,
- computer vision ,
- research assistant ,
- multimodal ,
- benchmark ,
- agentic ,
- paper ,
Related

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More
MBZUAI and Minerva Humanoids announce strategic research partnership to advance humanoid robotics for applications in the energy sector
The partnership will facilitate the development of next-generation humanoid robotics tailored for safety-critical industrial operations.
Read More
AI and the silver screen: how cinema has imagined intelligent machines
Movies have given audiences countless visions of how artificial intelligence might affect our lives. Here are some.....
- cinema ,
- art ,
- science fiction ,
- fiction ,
- AI ,
- artificial intelligence ,