
A compact multimodal model for real-time video understanding on edge devices
Monday, June 23, 2025

When people interact with multimodal models, they typically do so with large systems that are hosted remotely. As powerful and convenient as these systems are, they have limitations. In a practical sense, users must be connected to the internet to access them. People may also be reluctant to share personal or sensitive information with these systems.
One solution is for researchers to develop models that are hosted locally on what are known as edge devices, such as mobile phones. These devices, however, are much less powerful than the massive systems that run today’s large multimodal models. For models to be compatible with edge devices, they would need to be much smaller and more efficient.
A team of researchers from MBZUAI and other institutions has taken a step towards addressing this challenge by developing a compact and efficient multimodal system called Mobile-VideoGPT.
The researchers tested Mobile-VideoGPT on several video understanding benchmarks and found that their system was faster and performed better than others while being significantly smaller. The team describes it as the first efficient video understanding framework that is designed for real-time throughput.
“Our goal was to design an efficient system for real-time video understanding without sacrificing performance,” explains Abdelrahman Mohamed Shaker, a recent graduate of the Ph.D. program in computer vision at MBZUAI, postdoctoral associate at the University, and lead author of the study.
Muhammad Maaz, Chenhui Gou, Hamid Rezatofighi, Salman Khan, and Fahad Shahbaz Khan are coauthors of the study. The researchers have made the model and code publicly available.
How Mobile-VideoGPT works
Today’s multimodal systems, like OpenAI’s GPT series and Google Gemini, have the ability to analyze and explain the content of videos. These models, however, are closed-source, limiting their availability for deployment on edge devices. They also require massive computational infrastructure and a huge amount of energy.
Researchers have developed small- and medium-sized multimodal models, such as LLaVa-One-Vision and LLaVa-Mini, but these models aren’t specifically designed for real-time throughput on edge devices, which led Shaker and his team to develop their system.
Mobile-VideoGPT selects relevant keyframes from videos and uses a technique called efficient token projection that enhances the model’s efficiency while maintaining high performance.
The team’s approach is inspired by previous work by researchers at Meta GenAI and Stanford University and MBZUAI and other institutions.
Mobile-VideoGPT consists of four components: an image encoder based on CLIP (contrastive language-image pretraining) that captures spatial and semantic features in images, a video encoder called VideoMamba that extracts temporal information, an efficient token projection module, and a small language model based on Qwen-2.5-0.5B.

Overview of Mobile-VideoGPT.
The system takes in video and uses the CLIP-based image encoder to extract spatial features from all the frames of the video. A proposed attention-based frame scoring method is used to select relevant keyframes, dropping frames that aren’t relevant. “The main idea of this approach, which hasn’t been done before for this kind of system, is to remove irrelevant frames,” Shaker said.
The VideoMamba encoder is very efficient with only 73M parameters and processes the keyframes and captures temporal aspects of the video. These representations are then projected into a unified vision–language space using the efficient token projector. Finally, the small language model uses the tokens that are projected into the shared representation space to generate responses to prompts from users.
Shaker and his coauthors explain that “a straightforward approach would be to feed all sampled frames directly into the video encoder” but selecting keyframes makes the system much more efficient without affecting the performance.
The approach the researchers took to training the system had a major impact on its performance. The image and video encoders are frozen, while the efficient token projector were trained. Additionally, they applied LoRA (Low-Rank Adaptation) to the compact language model to enable parameter-efficient fine-tuning. They developed two versions of Mobile-VideoGPT: one with 0.6 billion total parameters and another with 1.6 billion parameters.
Results and next steps
The team compared Mobile-VideoGPT to other systems on six video understanding benchmarks, including ActivityNet-QA, EgoSchema, and MVBench. It achieved an average improvement of six points over another similarly sized model called LLaVA-OneVision0.5B. It also performed 20% to 30% better on movement tasks compared to other systems.
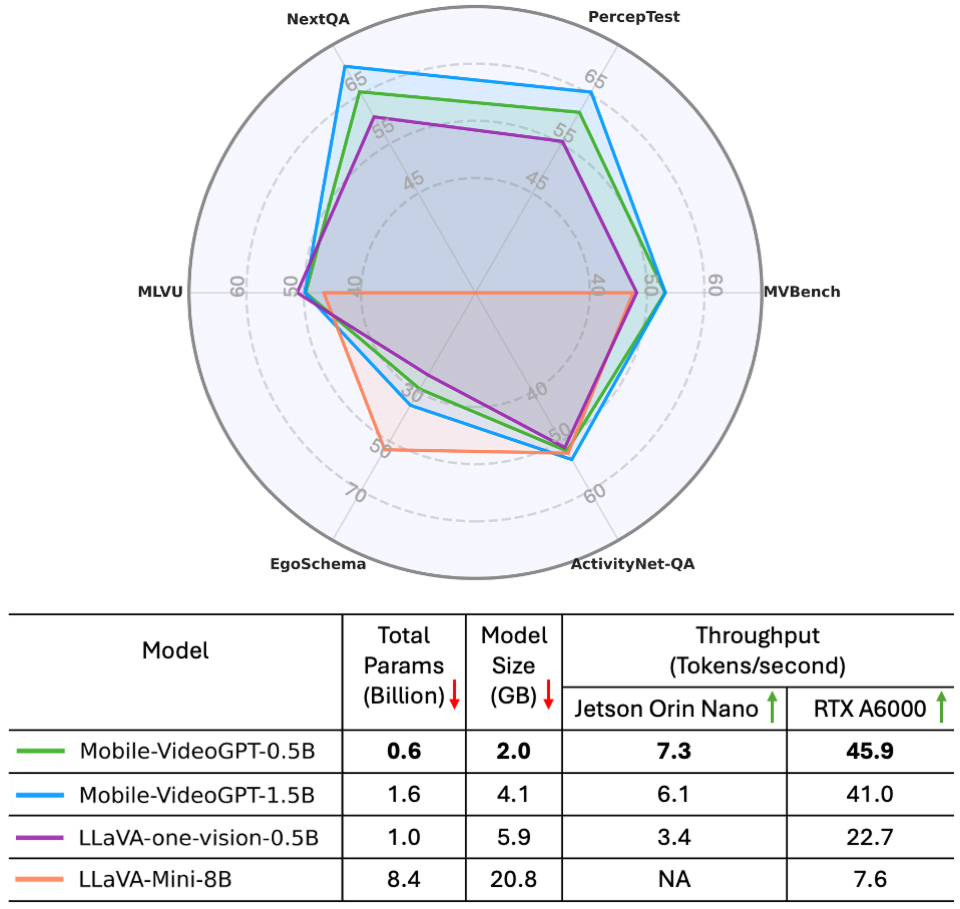
The performance of Mobile-VideoGPT compared to state-of-the-art models on six video benchmarks. The models were deployed and tested on an edge device. Mobile-VideoGPT-0.5B was more than two times faster than LLaVa-one-vision-0.5B.
The researchers also asked Mobile-VideoGPT to explain actions that were happening in videos on both AI-generated and captured video. The model was able to generate rich descriptions that described details like clothing, body language, and settings.

Mobile-VideoGPT, an efficient model for video understanding, was able to generate rich descriptions of an out-of-domain, AI-generated video.
Overall, Shaker and his coauthors found that they could significantly reduce the parameters of their system while maintaining performance. “Our system is smaller, has better performance, and is double the speed of others,” Shaker says. The throughput for Mobile-VideoGPT was also twice the speed of the next-best system, LLaVA-OneVision-0.5B.
While Shaker noted that more work needs to be done to test Mobile-VideoGPT on resource-constrained environments, such as mobile phones, he and his colleagues have taken a significant step towards building a compact multimodal model that delivers both speed and performance.
- computer vision ,
- multimodal ,
- edge devices ,
- GPT ,
Related

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More
MBZUAI and Minerva Humanoids announce strategic research partnership to advance humanoid robotics for applications in the energy sector
The partnership will facilitate the development of next-generation humanoid robotics tailored for safety-critical industrial operations.
Read More
AI and the silver screen: how cinema has imagined intelligent machines
Movies have given audiences countless visions of how artificial intelligence might affect our lives. Here are some.....
- cinema ,
- art ,
- science fiction ,
- fiction ,
- AI ,
- artificial intelligence ,