
حين ترى الآلة ولا تفهم: لماذا تعجز نماذج الذكاء الاصطناعي عن إدراك السياق الثقافي للصور؟
الاثنين، 23 مارس 2026

في زمن تتسارع فيه قدرات الذكاء الاصطناعي، يبرز إشكال يتمثل في الخلط بين الطلاقة اللغوية لهذه النظم وقدرتها على الفهم الحقيقي. فكثيراً ما يُطلب من نظام ذكي وصف صورة، فيقدّم نصاً سلساً ومتقناً، ما يوحي بامتلاكه إدراكاً عميقاً لمحتواها. غير أن هذا الانطباع قد يكون مضللاً؛ إذ تستطيع النماذج تحديد عناصر بصرية واضحة، لكنها غالباً ما تعجز عن استيعاب السياق الاجتماعي والثقافي الذي تنتمي إليه الصورة.
وتشكّل هذه الإشكالية محور دراسة حديثة أصدرتها جامعة محمد بن زايد للذكاء الاصطناعي بمشاركة الباحثين: كريمة قدّاوي وحنين عطواني وحمدان آل علي، والتي قُبلت ضمن فعاليات مؤتمر الفرع الأوروبي لجمعية اللغويات الحاسوبية في نسخته لعام 2026. وتتناول الدراسة مدى قدرة النماذج البصرية – اللغوية على التعامل مع صور يرج مصدرها إلى مجتمعات عربية متعددة، ومدى تمكنها من التعبير عنها باستخدام اللهجات المحلية التي يتداولها الناس في حياتهم اليومية.
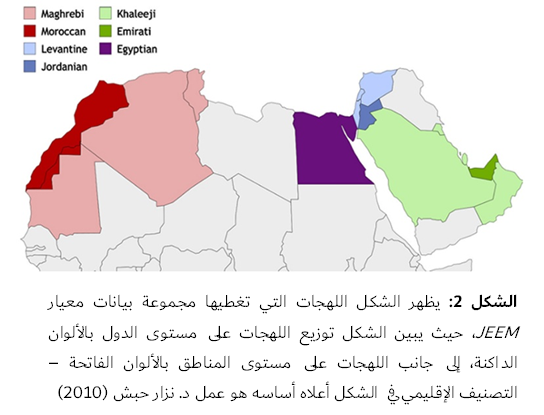
ويحمل المعيار البحثي [أي مجموعة البيانات] الجديد الذي يشمل أربع دول عربية بما فيها الأردن والإمارات ومصر والمغرب اسم “JEEM“. ويركّز على مهمتين أساسيتين مرتبطتين بمجال الذكاء الاصطناعي متعدد الوسائط وهما: وصف الصور والإجابة عن الأسئلة المرتبطة بها، غير أن ما يميّز هذا المعيار أو مجموعة البيانات هذه هو عدم الاكتفاء فقط بالتنوع الجغرافي لمصادر الصور، بل الامتداد إلى عمق المعالجة اللغوية ذاتها.
فعلى خلاف العديد من موارد معالجة اللغة الطبيعية التي تعتمد على العربية الفصحى الحديثة بشكل كبير، فإن معيار“JEEM” يعتمد أيضاً على اللهجات المحلية – الأردنية والإماراتية والمصرية والمغربية – وهو ما يعكس واقع اللغة العربية بوصفها منظومة لغوية غنية بالاختلافات الإقليمية المتأثرة بالتباينات التاريخية والثقافية واللفظية والمجتمعية. ويؤكد ذلك أن فهم الصورة لا ينفصل عن فهم اللغة التي تُروى بها، ولا عن السياق الذي يمنحها معناها الحقيقي.
وتخلص الدراسة إلى أن التحدي الأكبر لا يكمن في ما تراه الآلة، بل في ما لا تدركه: أي الطبقات الثقافية والاجتماعية التي تتجاوز حدود الوصف البصري. وهو ما يفتح الباب أمام إعادة التفكير في كيفية تطوير نماذج أكثر وعياً بالسياق، وقادرة على تمثيل المجتمعات بلغتها الحقيقية، لا بصيغها المجرّدة فقط.
بين الطلاقة والوهم المعرفي
حتى اليوم، ما تزال معظم الجهود التي تصب في اتجاه تقييم النماذج البصرية – اللغوية باللغة العربية تعتمد على ترجمة مجموعات بيانات باللغة الإنجليزية أو تستند إلى محتوى هزيل ثقافياً أو تتعامل مع العربية بوصفها لغة موحّدة مجردة عن تنوعها الطبيعي. غير أن مجموعة بيانات “JEEM” تسعى إلى تجاوز هذا النهج عبر مقاربة أكثر ارتباطاً بالواقع المحلي والإقليمي للعربية.
فقد جُمعت صور مجموعة بيانات “JEEM” من مصادر ذات صلة بالمنطقة، مثل “ويكيميديا” و”فليكر” وأرشيفات شخصية. كما تم استقطاب متحدثين ناطقين بلهجات الدول المعنية لكتابة توصيفات للصور وصياغة أسئلة وأجوبة باستخدام لهجاتهم. والنتيجة قاعدة بيانات تضم 2178 صورة و10,890 زوجاً من الأسئلة والأجوبة، تعكس تفاصيل الحياة اليومية والمشغولات المحلية والمشاهد الثقافية الخاصة بكل مجتمع، بدلاً من تقديم نسخة مترجمة لمشاهد مستوردة من منظومات ثقافية أخرى.
طلاقة لغوية مقنعة.. لكنها تفتقر للدقة الثقافية
اختبرت الدراسة أداء خمسة نماذج مفتوحة المصدر تدعم اللغة العربية، وهي: Maya وPALO وPeacock وAIN وAyaV، إلى جانب نموذج GPT-4o. وقد أظهرت النتائج نمطاً واضحاً في كلٍ من مهمتي وصف الصور والإجابة عن الأسئلة: إذ يتبيّن أن توليد لغة سليمة وطليقة أسهل بكثير من تحقيق فهم حقيقي وعميق للمحتوى.
فعلى الرغم من تحقيق النماذج أداءً جيداً نسبياً من حيث الطلاقة اللغوية، فإنها ما تزال متأخرة في معايير دلالية أكثر تعقيداً، مثل الاتساق والملاءمة. كما تشير النتائج إلى أن المقاييس الحالية لا تعكس الحكم البشري بدقة، لا سيما في سياق اللهجات العربية، وذلك على نحو مشابه لما يُستخدم عادةً في تقييم قدرات النماذج – وبعبارة أخرى، قد تبدو هذه النماذج مقنعة في أسلوبها اللغوي، لكنها لا تنجح دائماً في الإجابة عن الأسئلة بشكل صحيح أو في تقديم وصف دقيق يعكس محتوى الصورة.
وتتجلى الفجوة بشكل أوضح عندما يدخل البعد الثقافي في التقييم؛ ففي إحدى الحالات التي تناولتها الدراسة، طُلب من مُقيّمين من دول عربية مختلفة تفسير صورة لحلوى عُمانية تقليدية – وجاءت النتائج لافتة، حيث لم يتمكن سوى المُقيّم الإماراتي من التعرف عليها بدقة، بينما وصفها آخرون بأنها نوع مختلف من الحلوى، بل ذهب بعضهم إلى اعتبارها “بودينغ الشوكولاتة”.
تعكس هذه الحالة حقيقة معروفة مفادها أن التعرف على الأشياء يرتبط بالخبرة الثقافية. وإذا كان البشر يواجهون هذا التحدي أحياناً، فإن أنظمة الذكاء الاصطناعي تواجهه على نطاق أوسع. فالنموذج، مهما دُرّب على كميات هائلة من البيانات، قد يعجز عن تفسير عناصر أو عادات أو سياقات ثقافية لا تحظى بتمثيل كافٍ في بياناته التدريبية.
وتؤكد الدراسة، في ضوء هذا، أن تطوير ذكاء اصطناعي أكثر دقة لا يتطلب فقط بيانات أكبر، بل بيانات أكثر تنوعاً وارتباطاً بالسياقات الثقافية الحقيقية – وهو ما قد يشكّل الخطوة الحاسمة نحو نماذج تفهم العالم ولا تكتفي بوصفه.

لماذا ما يزال الذكاء الاصطناعي بعيداً عن فهم المجتمعات؟
على صعيد النتائج، تصدّر نموذج GPT-4o الأداء العام، وهو ما يتماشى مع توقعات الباحثين لنماذج متعددة الوسائط من الفئة المتقدمة؛ غير أن هذا التفوق لا يخلو من ثغرات واضحة؛ إذ أظهر النموذج ضعفاً ملحوظاً في الارتباط الدلالي، كما واجه صعوبة في التعبير الأصيل باللهجات المحلية. وتراجع أداؤه بشكل لافت في الجزء الخاص باللهجة الإماراتية ضمن مجموعة بيانات “JEEM“، وهو ما يفسّره الباحثون باستمرار التحديات المرتبطة باللهجات الأقل تمثيلاً في بيانات التدريب.
أما النماذج العربية المفتوحة، فجاء أداؤها دون ذلك بكثير. فبينما تمكن بعضها من إنتاج نصوص سلسة لغوياً، إلا أنها غالباً ما أخفقت في التقاط المعنى الحقيقي للمشهد، أو في التعبير عنه بصورة طبيعية تعكس روح اللهجة المستهدفة. ويؤكد ذلك أن الطلاقة، مرة أخرى، لا تعني الفهم.
ما وراء أرقام الأداء القياسي
يتزايد الترويج لنماذج الذكاء الاصطناعي متعدد الوسائط بوصفها نظم شاملة ومتكاملة قادرة على الوصف واسترجاع المعلومات والإجابة والتحليل عبر مختلف اللغات والسياقات. غير أن هذه “الشمولية” تصبح موضع تساؤل عندما تستند إلى معايير تقييم محدودة ثقافياً أو تعتمد على الترجمة أو تركز على اللغة المعيارية دون غيرها.
وفي هذا السياق، يبرز معيار مجموعة بيانات “JEEM” كتذكير مهم بأن شمولية النماذج الحقيقية لا تتحقق بمجرد إضافة لغات جديدة إلى قوائم الأداء، بل بقدرة النموذج على ربط الإشارات البصرية بدلالاتها الاجتماعية الصحيحة، والتعبير عنها باللغة التي يستخدمها الناس فعلياً في حياتهم اليومية.
تقييم متعدد الأبعاد لفهم أعمق
لم يقتصر الباحثون في دراستهم على أسلوب تقييم واحد، بل اعتمدوا مقاربة متعددة تجمع بين المقاييس الآلية التقليدية، وتقييمات مستندة إلى نماذج GPT-4، إضافة إلى أحكام/توصيفات المعلقين. ويُعد هذا التوجه منطقياً، خاصة في مهام مثل وصف الصور والإجابة عن الأسئلة باللهجات العربية، حيث تفشل المقاييس القائمة على التشابه السطحي في تجسيد الفهم الحقيقي. فاللغة العربية، بما تتميز به من ثراء صرفي وتنوع إقليمي، تجعل من الاعتماد على تطابق الكلمات أو التراكيب مؤشراً مضللاً. ومن هنا، تعكس منهجية التقييم في الدراسة اتجاهاً متنامياً في أبحاث الذكاء الاصطناعي، يقوم على أن المهام المرتبطة بالسياق الثقافي تتطلب أدوات قياس أكثر عمقاً، تتجاوز الاختزال.
وفي المحصلة تؤكد الدراسة أن الطريق نحو ذكاء اصطناعي “يفهم” العالم ما يزال يمر عبر بوابة الثقافة، لا البيانات وحدها.
خلاصة
تُظهر هذه النتائج بوضوح أن تطوير منتجات ذكاء اصطناعي متعددة اللغات لم يعد يكتفي بالادعاء بدعم اللغة العربية أو حتى القدرة على فهم الصور ضمن هذا الإطار اللغوي. فالدعم بالقدرات البصرية لأي لغة قد يخفي وراءه فجوات عميقة بين الفصحى ولهجاتها، وبين اللهجات الغنية بالبيانات وتلك المهمّشة، فضلاً عن الفرق الجوهري بين التعرف العام على العناصر البصرية وفهمها ضمن سياقها الثقافي الحقيقي.
وبالتالي، قد يحقق نظام ما أداءً قوياً وفق المعايير الشائعة، لكنه يتعثر في المواقف التي تهم المستخدمين فعلياً حين تكون اللغة محلية، والسياق ثقافياً، والمعنى أبعد من مجرد توصيف بصري مباشر.
في هذا الإطار، لا يدّعي معيار “JEEM” أنه يقدم حلاً نهائياً لهذه الإشكالية، لكنه يشكّل خطوة مهمة نحو مواجهتها بجدية. فمن خلال توجيه التقييم نحو اللهجات، والصور المحلية، والمشاهد المحمّلة بالدلالات الثقافية، تطرح الدراسة سؤالاً أكثر صراحة وعمقاً على مجتمع البحث: عندما نقول إن النموذج “يفهم العالم”، فعن أي عالم نتحدث تحديداً؟
حتى الآن، ما تزال الإجابة تميل إلى التحفّظ – فالآلة التي تستطيع وصف صورة بدقة لغوية، ليست بالضرورة قادرة على فهم ما تنظر إليه. وبين الوصف والفهم، ما تزال هناك فجوة لا يرأبها إلا إدراك السياق—وهو التحدي الأكبر الذي لم يُحسم بعد في مسيرة الذكاء الاصطناعي.
- اللغة ,
- 2026 ,
- مؤتمرات ,
- النماذج البصرية-اللغوية ,
- الصور ,
- العربية ,
- الثقافة العربية ,
- الثقافة ,
- متعدد الوسائط ,
- EACL ,
- معالجة اللغة الطبيعية ,
- البحوث ,
أخبار ذات صلة
بناء نموذج ذكاء اصطناعي يتحدث الهندية
تُظهر نماذج ناندا (Nanda) التي طوّرتها جامعة محمد بن زايد للذكاء الاصطناعي للغتين الهندية والإنجليزية أن فعالية.....
- الثقافة ,
- IFM ,
- معهد النماذج التأسيسية ,
- Nanda ,
- الهندية ,
- اللغة ,
- nlp ,
- معالجة اللغات الطبيعية ,

نماذج الذكاء الاصطناعي… أرشيفات ثقافية خفية تعكس تفاصيل الحياة اليومية للمجتمعات
في وقتٍ تُوصَف فيه النماذج اللغوية الحديثة تارة بأنها نظم للتنبؤ، وتارة أخرى كمحرّكات للاستدلال المنطقي أو.....
- النماذج اللغوية الكبيرة ,
- natural language processing ,
- research ,
- conference ,
- nlp ,
- البحوث ,
- llms ,
- معالجة اللغة الطبيعية ,
- EACL ,
- language ,
- اللغة ,
- culture ,
- الثقافة ,
- مؤتمرات ,

من الغموض إلى الفهم: كيف تستفيد نماذج الذكاء الاصطناعي من تعدد الأحكام والتصنيفات التي يضعها الإنسان
دراسة حديثة، أُنجزت بالتعاون بين جامعة محمد بن زايد للذكاء الاصطناعي وجامعة ملبورن، تكشف عن تطوير مقاييس.....
- اختلاف التصنيفات ,
- التصنيفات ,
- دورية علمية ,
- اختلاف الأحكام ,
- معالجة اللغة الطبيعية ,
- الأبحاث ,
- اللغة ,
- Computational linguistics ,
- labels ,