
البحث عن الفيديوهات بأسلوب يحاكي طريقة البشر في البحث عن المقاطع
الأحد، 09 نوفمبر 2025

لا تزال معظم عمليات البحث عن الفيديو اليوم تبدو غير دقيقة وغير مُرضية فإمّا أن يكتب المستخدم بضع كلمات مفتاحية على أمل الوصول إلى النتيجة المناسبة، أو يتصفح الصور المصغّرة واحدة تلو الأخرى، لكن ما يريده المستخدم في كثير من الأحيان هو أمر مختلف تماماً: أن يُشير إلى مقطع فيديو ويقول: “ابحث لي عن مقاطع مشابهة لهذا، ولكن عند الغسق، ومع درّاج واحد بدلاً من ثلاثة”.
هذه المهمة، التي تبدو بسيطةً ظاهرياً، تمثّل جوهر مجالٍ بحثيٍّ متنامي يُعرف باسم استرجاع الفيديو المركَّب (CoVR) ؛ إذ يتيح للمستخدم أن يُقدم مقطعاً كمثال أو عيّنة، ثم يصف التعديل المطلوب عليه بلغةٍ طبيعية.
تدفع ورقة بحثية جديد عرضت خلال المؤتمر الدولي للرؤية الحاسوبية 2025 هذه الفكرة بقوة للمضي قدماً، من خلال لغةٍ أكثر تركيزاً، ونموذجِ دمجٍ موحَّدٍ أقوى، واهتمامٍ أكبر بكيفية تقييم المهمة. ويوضح ديمتري ديميدوف، طالب الدكتوراه في جامعة محمد بن زايد للذكاء الاصطناعي وأحد مؤلفي الورقة، أن هذه المشكلة التي تبدو متخصصةً ترتبط بمجالاتٍ إبداعية وتحليلية متعددة حقيقية، من البحث عن لقطات ثانوية ( بي رول) في الإنتاج المرئي، وصولاً إلى استخراج لقطات متشابهة في تحليلات الفيديو الرياضي.
يجادل مؤلفو الورقة بأن مجموعات بيانات CoVR السابقة كانت تصف التعديلات بعباراتٍ قصيرةٍ وغامضة، مثل: «عندما كان طفلاً» أو «قم بإزالة المرطبان»، وهي أوصافٌ لا تُجبر النموذج على مواءمة اللغة مع التغييرات البصرية الفعلية عبر الزمن. وجاء ردّهم بتقديم Dense‑WebVid‑CoVR، وهو معيارٌ قياسي جديد يضم 1.6 مليون عيّنة، ويتميّز بأوصاف فيديو طويلةٍ وغنيةٍ بالسياق (بمتوسط 81 كلمة)، إلى جانب نصوص تعديلٍ يبلغ متوسط طولها 31 كلمة، أي أطول بنحو سبع مرات من المعيار السابق. والأهم من ذلك أن هذه التعديلات ليست ملخّصاتٍ مستقلةً للمقطع المستهدف، بل كُتبت لتكون معتمدةً صراحةً على مقطع الاستعلام، مما يمنع «التحايل» القائم على الاسترجاع النصّي فقط دون الرجوع إلى الفيديو.
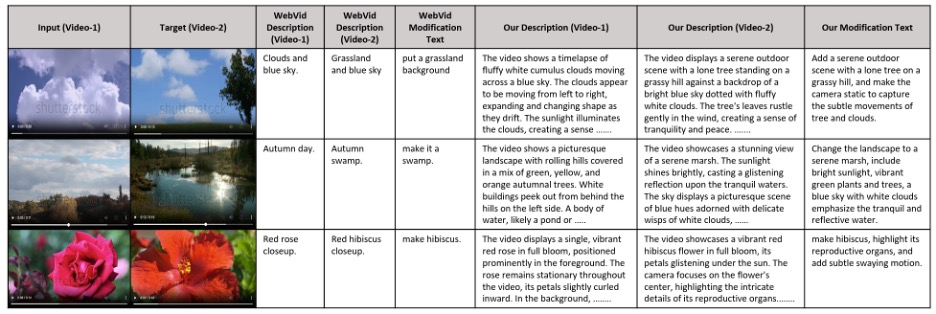
لبناء هذه المجموعة، استخدم الفريق Gemini Pro من جوجل لتوليد أوصاف الفيديو، ثم استعان بـ GPT-4o لإنتاج نصوص التعديل، قبل إجراء مرحلة تحقق بشري شاملة لتصحيح التكرار، والأعداد، والإشارات الزمنية، بما يضمن أن التعديل يتطلب فعلاً استدلالاً متعدد الوسائط. تم التحقق من مجموعة الاختبار بالكامل بشرياً. ورغم أن العملية معقدة، إلا أنها ضرورية: فالمعيار الجديد يدفع النماذج لإثبات قدرتها على التعامل مع تغييرات دقيقة في الكائنات، والأعداد، وحركة الكاميرا، والتوقيت.
منهجيةٌ أذكى لاسترجاع الفيديو المركَّب
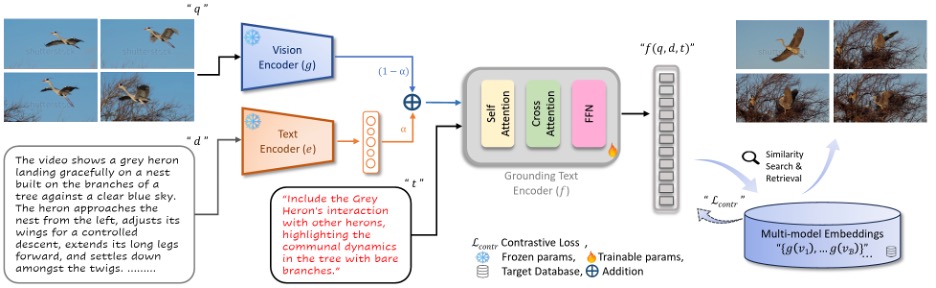
اعتمدت الأنظمة السابقة غالباً على دمجٍ ثنائيٍ بين الوسائط، مثل الجمع بين الفيديو والنص، أو الوصف والنص، أو الفيديو والوصف، ثم محاولة التوفيق بين هذه النتائج لاحقاً. أمّا النهج الجديد فيعتمد دمجاً موحّداً منذ البداية، إذ يُمثَّل فيديو الاستعلام مع وصفه التفصيلي في تمثيلٍ واحدٍ، ويُدمجان باستخدام وزنٍ متعلَّمٍ، ثم يُمرَّران إلى مُشفِّرٍ نصّيٍ مخصّصٍ للمواءمة الدلالية. يقوم هذا المُشفِّر بربط التمثيل الناتج بنصّ التعديل التفصيلي، بحيث يوجّه كل عنصرٍ في الوصف عمليةَ الفهم وفق السياق المطلوب. على مستوى الرؤية، يعتمد النموذج على هيكلٍ من نوع ViT-L، بينما تستند المكوّنات النصّية إلى بنيةٍ من نوع BLIP-2. أمّا عمليةُ التدريب فتعتمد على دالّةِ خسارةٍ تقابليةٍ، تعمل على تقريب تمثيل الاستعلام المدمج مع التعديل من المقطع الصحيح ضمن قاعدة بياناتٍ كبيرةٍ.
قد يبدو هذا الاختلاف دقيقاً، لكنه يظهر بوضوح في الأرقام والسلوك: الاستدلال المشترك عبر المدخلات الثلاثة يُقلّل ميل النماذج إلى تفويت تفاصيل التحرير الدقيقة التي تُسقطها مخططات الدمج الثنائي، وفي تحليلات التحقُّق، يكون التضمين الموحَّد أقرب، بشكل قابل للقياس، من الأهداف الصحيحة مقارنةً بعمليات الدمج الثنائي.
على المعيار الرئيسي، يحقق النموذج مكاسبَ واضحةً عند استخدام مدخلات الفيديو والنص مع دمجٍ موحّدٍ للمعلومات. إذ يصل إلى قيمة Recall@1 تقارب 71.3% على مجموعة Dense-WebVid-CoVR، بزيادةٍ قدرها نحو 3.4 نقاط مقارنةً بأقوى الطرق السابقة التي استخدمت الهيكل والوسائط نفسيهما. وبعبارةٍ مبسّطةٍ، فإن ما يقارب ثلاثةَ أرباعِ عمليات البحث تُعيد المقطع الصحيح في النتيجة الأولى، وهو ما يختبره محرّر الفيديو عملياً على أنه نظامٌ «يجد المطلوب مباشرةً».
ويتميّز النظام أيضاً بسرعة أعلى بنحو ثلاث مرّات مقارنةً بخط الأساس الثنائي، نظراً لتجنّبه المعالجة المتكرّرة عبر مسارات دمجٍ متعدّدةٍ. كما تظهر فائدةُ اللغة الغنيّة على مستويين، إذ يساهم كلٌّ من التدريب على تعديلات تفصيليةٍ، والاستدلال باستخدام أوصاف فيديو كثيفةٍ، في تحسين الأداء بشكل مستقلّ، مع تحقيق أفضل النتائج عند الجمع بينهما.
يُطرح سؤالٌ مشروعٌ مع النصوص الأطول، وهو ما إذا كان CoVR قد يتحوّل إلى مجرّد استرجاعٍ من نصٍّ إلى فيديو، وقد توقّع المؤلفون ذلك وصاغوا المحفّزات بحيث تُجبر على الرجوع إلى مقطع الاستعلام، باستخدام تعديلاتٍ من نوع: حوّل الرجل البالغ إلى طفلٍ صغيرٍ يتدرّب مع مدرّبٍ قريبٍ وورقة نوتةٍ على الحامل، بدلاً من أوصافٍ يمكن مطابقتها دون النظر إلى المقطع الأصلي، وأكّد ديميدوف أن التحقّق البشري استهدف تحديداً هذه مواطن الفشل، ما قلّل من الحالات التي يصف فيها النص الهدفَ بمعزلٍ عن الاستعلام، وبعبارةٍ أخرى فإن اللغة الكثيفة تجعل الاختبار أكثر صرامةً.
فيما يخص خيارات البنية، صُمّم مُشفّر الرؤية مع التركيز على الكفاءة، وغالباً ما يعتمد على الإطار الأوسط لتمثيل المقطع، أسوةً بالأعمال السابقة. ويقرّ المؤلفون بأن هذا الاختيار قد يحدّ من تمثيل الانتقالات الزمنية، لذلك يقترحون إدخال وحداتٍ زمنيةٍ خفيفةِ الوزن كخطوةٍ لاحقةٍ. ويصبح هذا القيد أكثر وضوحاً عند اختبار النموذج خارج نطاق التدريب. فعلى معيار Ego-CVR، وهو معيارٌ صغيرٌ قائمٌ على منظور الشخص الأول، يعتمد نحو 79% من الاستعلامات على أحداثٍ زمنيةٍ.
ورغم ذلك، يواصل الدمج الموحّد تحقيق نتائج متقدّمةٍ في إعداد الضبط الصفري، بما يقدّم دليلاً واضحاً على قابلية تعميم التعديلات اللغوية الكثيفة والاستدلال المشترك. ومع هذا، يشير المؤلفون إلى أن زوايا الرؤية غير المعتادة والتغيّرات السريعة في الحركة تضع المعالجة الزمنية الحالية عند حدودها. ومن اللافت أن المنهجية نفسها تنجح أيضاً في استرجاع الصور المركّب، إذ تسجّل نتائج جديدةً على مجموعتَي CIRR وFashionIQ، سواء في الإعدادات التدريبية أو في الضبط الصفري، ما يدلّ على أن مخطّط الدمج المعتمد لا يقتصر على الفيديو وحده.
من البحث إلى التأثير الواقعي
لماذا يهمّ كل هذا خارج لوحات الترتيب؟ لأن الاستعلامات المركّبة تعبّر عن الطريقة التي يفكّر بها الناس فعلاً. ففي الإنتاج الإبداعي، نادراً ما يبحث المرء عن «غروبٍ عامٍّ»، بل عن لقطته المعدّلة: الشارع نفسه ولكن عند الغسق، المطبخ نفسه ولكن بعد ترتيب الأطباق، الراكب نفسه ولكن على درّاجةٍ خضراء تُرى من الخلف.
وفي المقارنات النوعية التي عرضها المؤلفون، يميل خط الأساس الثنائي إلى استرجاع نتائج قريبةٍ ولكن غير دقيقةٍ، بينما ينجح النموذج الموحّد في التقاط التفاصيل الصحيحة. مثل إرجاع توليبٍ أصفر بدلاً من توليبٍ أصفر تحيط به ألسنةُ لهبٍ حمراء على جدارٍ من الطوب الأبيض، أو اختيار لقطةٍ مقرّبةٍ لدرّاجةٍ نارية بدلاً من لقطةٍ أوسع لميكانيكي يعمل عليها. وهي فروقٌ قد تبدو بسيطةً، لكنها في الواقع تستهلك وقتاً ثميناً في عمل المحررين.

يرى ديميدوف أن هذا النهج يمكن أن يمتدّ إلى تحليلات الرياضة، مثل الركنية نفسها ولكن مع إنهاءٍ برأسيةٍ، وإلى التعليم من خلال نسخٍ معدّلةٍ من العروض مع تغييراتٍ طفيفةٍ في الإعداد، وإلى المكتبات الشخصية مثل مشهد عيد الميلاد نفسه ولكن مع الجدة وهي تقطع الكعكة، مع التأكيد على الضوابط المعروفة المتعلّقة بالخصوصية والتحيّز.
بالنسبة للباحثين، تبرز عدّة خلاصاتٍ تقنيةٍ، أولاً تفيد كثافة اللغة ليس لأنها تضيف مزيداً من الرموز النصّية فحسب، بل لأنها تُرغم النماذج على مواءمة العبارات مع الشواهد البصرية عبر الانتباه المتقاطع، ثانياً تُعدّ استراتيجية الدمج عنصراً حاسماً، إذ إن توحيد الفيديو والوصف والتعديل داخل مُشفّرٍ واحدٍ يحافظ على التفاعلات التي تُضعفها المسارات الثنائية، ثالثاً تُعدّ نظافة التقييم خياراً تصميمياً من الدرجة الأولى، حيث تؤدّي المحفّزات المتحقّق منها بشرياً وبُنى الاستعلام التي تمنع وصف الهدف بمعزلٍ عن الاستعلام إلى نتائج أكثر موثوقيةً وتحدّ من الاختصارات النصّية، وعلى الرغم من التزام الورقة بمعايير الكفاءة المتّبعة، تُظهر دراسات الاستبعاد أن معظم المكاسب تعود إلى إشرافٍ أفضل ودمجٍ أحسن، لا إلى بنيةٍ أكبر أو قدرات أعلى فقط لوحدات معالجة الرسوميات.
القيود واضحةٌ بالقدر نفسه وتشكل في الوقت ذاته خارطة طريقٍ، إذ يظل الفهم الزمني سطحيّاً عندما يعتمد التمثيل على إطارٍ واحدٍ، كما أن مهام العدّ وتغيّر الأدوار التي تتكشّف خلال ثوانٍ قليلةٍ ما تزال هشّةً، ويقترح المؤلفون دمجاً معزّزاً بالأدوات عبر إدراج محدّدٍ زمنيٍّ يسبق عملية الدمج لتحديد موضع التغيّر المرجّح، بحيث لا يضطر المُشفّر إلى التخمين عبر المقطع بأكمله، أمّا استرجاع الفيديو المركّب متعدّد اللغات فيمثّل جبهةً أخرى، إذ يتطلّب الحفاظ على كثافة التعديلات، مع دعم اللغات منخفضة الموارد، مزيجاً من نصوصٍ مكتوبةٍ باللغة الأصلية، وترجمةٍ دقيقةٍ، وتدريبٍ على الاتّساق لضمان تصنيف التعديل نفسه الهدف ذاته عبر اللغات، كما أن التوسّع إلى مقاطع طويلةٍ جداً يستلزم إعادة التفكير في كيفية تجزئة الأوصاف والتعديلات واللقطات ضمن ميزانيةٍ حسابيةٍ ثابتةٍ.
في أفضل حالاتها، تُعيد المعايير تشكيل طريقة الحديث عن التقدّم داخل أي مجالٍ. ويقوم Dense-WebVid-CoVR بهذا الدور من خلال دفع الأنظمة إلى التصرّف كشركاء حقيقيين في البحث: هذا هو مقطعي، وهذا هو التعديل الذي أريده، اعثر لي على أفضل تطابق. ويُظهر النموذج المصاحب أن إدخال تغييراتٍ معماريةٍ محدودةٍ، عند تغذيتها بنوع اللغة المناسب، يمكن أن يُحدث فرقاً عملياً ملموساً، إذ يرفع دقّة الوصول إلى النتيجة الصحيحة من المحاولة الأولى إلى مستوى يهمّ المحرّرين والمحلّلين وكل من يعتمد على البحث بالمثال. ولا يزال هناك الكثير مما يمكن تحسينه، لا سيما في ما يتعلّق بالبعد الزمني. لكن، كما أشار ديميدوف، ما إن تصبح التعديلات صريحةً ومُرتبطةً مباشرةً بمقطع الاستعلام، نكون أقرب بكثيرٍ إلى الطريقة التي يفكّر بها الناس بالفعل. وعندها، يتوقّف البحث عن كونه لعبةَ تخمينٍ، ويبدأ في أن يبدو كحوار حقيقيّ.
- المؤتمرات ,
- الرؤية الحاسوبية ,
- ICCV ,
- البحث ,
- أوراق بحثية ,
- الفيديوهات ,
- اللغة الطبيعية ,
أخبار ذات صلة

جامعة محمد بن زايد للذكاء الاصطناعي تعلن عن شراكة بحثية استراتيجية مع "مينيرفا هيومانويدز" لتطوير روبوتات بشرية لتطبيقات قطاع الطاقة
تجسّد هذه الشراكة جسراً يربط بين أبحاث الذكاء الاصطناعي التأسيسية والتطبيقات الصناعية.
اقرأ المزيد
لماذا ما زالت أنظمة الذكاء الاصطناعي اليوم عاجزة عن الاستدلال المكاني ثلاثي الأبعاد
A new benchmark by MBZUAI researchers shows how poorly current multimodal methods handle real-world geometric and perspective-based.....
- الاستدلال المكاني ,
- ثلاثي الأبعاد ,
- الأساس المعياري ,
- النماذج اللغوية-البصرية ,
- البحوث ,
- neurips ,
- المؤتمرات ,
السير مايكل برادي يدعو إلى انتقال الذكاء الاصطناعي الطبي من التشخيص إلى شرح القرارات
في إطار سلسلة المحاضرات المتميزة في جامعة محمد بن زايد للذكاء الاصطناعي، ناقش السير مايكل برادي مستقبل.....
- محاضرة زائر ,
- علم الأورام ,
- الاستدلال السببي ,
- الحرم الجامعي ,
- الطب ,
- الرعاية الصحية ,
- الرؤية الحاسوبية ,