
نظام جديد ومتطور يعزز قدرة النماذج اللغوية الكبيرة على الكلام
الاثنين، 26 مايو 2025

عند التعامل مع النماذج اللغوية الكبيرة الأكثر شيوعاً اليوم، مثل نماذج “GPT” من شركة “أوبن أيه آي” ونماذج “LLaMA” من شركة “ميتا”، يتفاعل المستخدمون معها عادةً من خلال النصوص المكتوبة. وهذا الأمر، كما يرى هشام شولاكال، الأستاذ المساعد في قسم الرؤية الحاسوبية بجامعة محمد بن زايد للذكاء الاصطناعي، يحدّ من قدرة النموذج اللغوي الكبير على أن يكون مساعداً افتراضياً حقيقياً قادراً على التفاعل بشكل سلس ومتعدد الوسائط يشبه التفاعل البشري.
أعدّ شولاكال، بالاشتراك مع مجموعة من الباحثين في الجامعة، دراسة تقترح نظاماً جديداً اسمه “LLMVoX” يتيح لأي نموذج لغوي كبير القدرة على الكلام. ويمكن تكييف هذا النظام مع النماذج اللغوية البصرية، كما أنه يدعم لغات متعددة. وقد عرض الفريق قدرات النظام باللغتين الإنجليزية والعربية. وهذه أول مرة يُطوَّر فيها نظام من هذا النوع للغة العربية.
نشر الباحثون التعليمات البرمجية والنماذج والبيانات المستخدمة في التدريب كموارد مفتوحة المصدر، وقُبلت ورقتهم البحثية عن النظام “LLMVoX“ للنشر في مجلة “Findings” الصادرة عن جمعية اللغويات الحاسوبية في عام 2025.
شارك في إعداد الدراسة كل من سامبال شيخار، ومحمد عرفان كوربات، وسهل شاجي مولابيلي، وجان لحود، وفهد خان، وراو محمد أنور، وسلمان خان، وجميعهم باحثون في جامعة محمد بن زايد للذكاء الاصطناعي.
وقد جرى تطوير النظام “LLMVoX” ضمن مشروع “OMER” الذي يقوده شولاكال وحصل مؤخراً على منحة بحثية إقليمية من شركة “ميتا”. ويهدف المشروع إلى تحسين قدرة النماذج اللغوية الكبيرة على أداء دور مساعد متعدد الوسائط (بصري صوتي)، خصوصاً في منطقة الشرق الأوسط.
مساعدة النماذج اللغوية الكبيرة على الكلام
على الرغم من أن النماذج اللغوية الكبيرة لا تُصمم عادةً لإنتاج الكلام مباشرة، فقد استخدم المطورون عدة أساليب مختلفة تتيح للمستخدمين التفاعل معها عبر الكلام.
أحد هذه الأساليب هو “النظام الشامل”، وفيه يُدرّب النموذج اللغوي الكبير باستخدام بيانات صوتية بالإضافة إلى النصوص. إلا أن هذا الأسلوب له عيوبه، حيث يشير شولاكال وزملاؤه إلى أن التدريب الإضافي على الصوت يؤثر سلباً على قدرات النموذج الأساسية في الاستدلال والتعبير، مما يؤدي إلى تراجع أدائه. بالإضافة إلى ذلك، نظراً لافتقار الأنظمة الشاملة إلى المرونة، فإن أي جهد لتحسين قدراتها يتطلب إعادة التدريب أو تعديلات إضافية.
وهناك أسلوب آخر يُعرف باسم “النظام التتابعي”، وفيه يُحوّل كلام المستخدم أولاً إلى نص باستخدام نظام التعرف التلقائي على الكلام، ثم يعالجه النموذج اللغوي الكبير، وأخيراً يُحوّل النص الناتج إلى كلام مرة أخرى باستخدام نظام تحويل النص إلى كلام.
تكمن ميزة النظام التتابعي في إمكانية تحسين كل جزء على حدة دون التأثير على الأجزاء الأخرى. لكن مشكلته تكمن في التأخير الناتج عن انتقال البيانات من مرحلة لأخرى، مما يجعل التجربة مختلفة عن إيقاع المحادثة الطبيعية بين البشر.
يُعزى السبب الرئيسي لهذا التأخير إلى الاختلاف بين النماذج اللغوية الكبيرة وأنظمة تحويل النص إلى كلام في كيفية توليد مخرجاتها. فالنماذج اللغوية الكبيرة تتبع نهجاً توليدياً تتابعياً، بمعنى أنها تنتج الكلمات بالتتابع وفقاً لما قبلها. أما أنظمة تحويل النص إلى كلام، فهي تحتاج عادةً إلى جزء كامل من النص لتبدأ في إنتاج الصوت. ومع أن بعض أنظمة تحويل النص إلى كلام تعمل أيضاً بطريقة التوليد التتابعي، إلا أنها ليست أنظمة بث مباشر، أي أنها لا تُصدر الصوت فور إنتاجه. وهذا أيضاً يؤدي إلى تأخير.
يجمع النظام “LLMVoX” بين قدرات التوليد التتابعي والبث المباشر ليجعل تجربة التواصل الصوتي مع النماذج اللغوية الكبيرة أقرب إلى الحوار الطبيعي بين البشر. ويعتمد النظام على نموذج محوِّل خفيف (وهي البنية الأساسية نفسها التي تعتمد عليها النماذج اللغوية الكبيرة) يعمل بالتوازي مع النموذج اللغوي الكبير، مما يمكّن النظام من البدء في توليد الصوت بمجرد توليد النص الأولي، وبالتالي يتجنب التأخير دون أن يؤثر ذلك على الدقة أو جودة الصوت.
يوضح شيخار، الباحث المساعد في جامعة محمد بن زايد للذكاء الاصطناعي والمؤلف الرئيسي للدراسة هدف الفريق قائلاً: “كان هدفنا تطوير نموذج لتحويل النص إلى كلام يعمل بطريقة التوليد التتابعي بحيث يبدأ إنتاج الصوت فور بدء النموذج اللغوي في توليد النص”.
رغم أن النظام “LLMVoX” هو في الأساس نظام تتابعي، فقد وجد الباحثون أن مدة التأخير فيه (300 ملّي ثانية فقط) أقل مما هي عليه في أي نظام تتابعي آخر (4,200 ملّي ثانية).
مميزات النظام “LLMVoX“
يُعدّ النظام “LLMVoX” نموذجاً خفيفاً لتحويل النص إلى كلام، حيث يحتوي على 30 مليون معامل فقط، ما يسمح باستخدامه على أجهزة متعددة وفي بيئات مختلفة.
كما طور الفريق نسخة منه يمكن تشغيلها على الحاسوب المحمول دون الحاجة إلى الاتصال بخوادم تحتوي على وحدات معالجة الرسوميات. وبحسب شيخار: “النموذج خفيف جداً، وحتى عند تشغيله على حاسوب محمول يمكن الحصول على إجابة خلال أقل من ثانية واحدة”.
وبينما تقتصر الأنظمة الأخرى على إنتاج مقاطع كلام محدودة الطول، يمكن للنظام “LLMVoX” إنتاج كلام بأي طول بفضل تصميمه المبتكر. ولتحقيق ذلك، يستخدم النظام آلية بث ثنائية تتكون من وحدتين متطابقتين، حيث تعالج الوحدة الأولى جزءاً من النص بينما تنتج الوحدة الثانية جزءاً آخر. ويتناوب النظام بين الوحدتين بشكل يتيح إنتاج مقاطع صوتية أطول بكثير. ويؤكد شيخار أنه لا يوجد حد أقصى لطول النص الذي يمكن معالجته.
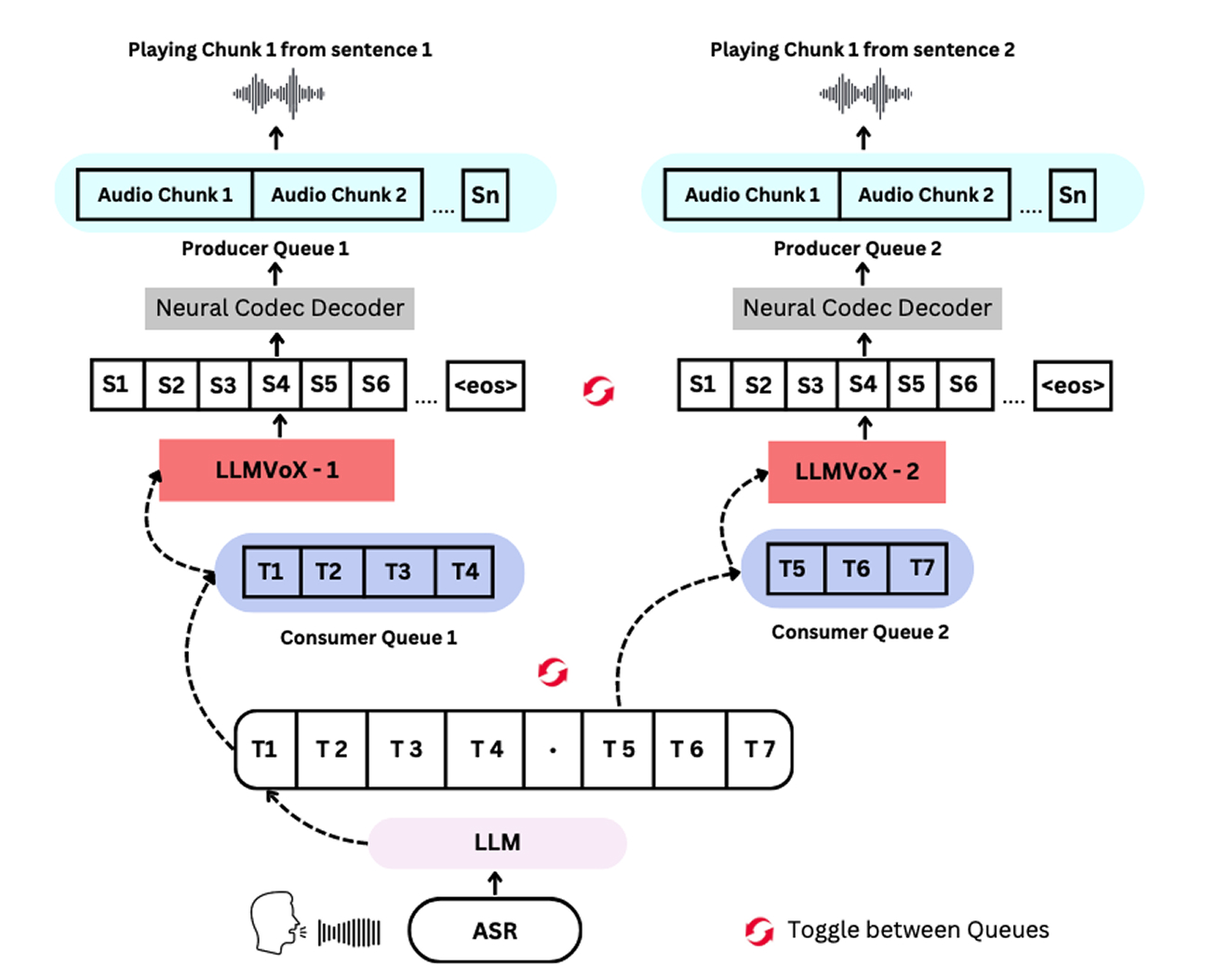
يستخدم النظام “LLMVoX” وحدتين متطابقتين لتحويل النص إلى كلام تتناوبان على معالجة النص الذي يولّده النموذج اللغوي الكبير، مما يمنح النظام القدرة على تحويل أي نص، مهما كان طوله، إلى كلام.
تحويل النص إلى كلام باللغة العربية ولغات أخرى
طوّر الباحثون مجموعة بيانات اصطناعية تحتوي على نصوص ومقاطع صوتية باللغة العربية لتدريب النموذج عليها، ثم ربطوها بعدة نماذج لغوية كبيرة تدعم اللغة العربية.
وهذه المرة الأولى التي يطور فيها العلماء نظاماً لتحويل النص إلى كلام باللغة العربية بطريقة التوليد التتابعي. لكن عمل الباحثين لم ينته عند هذا الحد، حيث يقول شولاكال: “صُمم نظامنا للعمل بلغات متعددة، ونعمل حالياً على توسيعه ليشمل لغات أخرى إلى جانب الإنجليزية والعربية”.
مقارنة “LLMVoX” مع الأنظمة الأخرى
استخدم الباحثون النموذج “GPT-4o” لتقييم أداء النظام “LLMVoX” على مجموعة بيانات تتكون من أسئلة وإجابات ومقارنته مع أداء غيره من الأنظمة الشاملة والأنظمة التوليدية التتابعية. (استخدم الفريق النموذج “GPT-4o” لتقييم النصوص الناتجة من الكلام الذي أنتجته تلك الأنظمة). وقد وجدوا أن أداء النظام “LLMVoX” أفضل من أداء الأنظمة الأخرى في الإجابة على الأسئلة وتقديم المعلومات العامة.
وطلب الباحثون من أشخاص آخرين تقييم أداء النظام “LLMVoX” مقارنةً بنموذج لغوي كبير مخصص للكلام اسمه “Freeze-Omni”. واختاروا لهذا الغرض 30 سؤالاً من مجالات مختلفة، وأعطوا خمسة أسئلة لكل مُقيِّم. وشارك في هذه الدراسة 30 شخصاً. في هذا الاختبار، استخدم الباحثون نظام “Whisper-Small” للتعرف التلقائي على الكلام، والنموذج اللغوي الكبير “LLaMA 3.1B”، ونظام “LLMVoX” لتحويل النص إلى كلام.
قيّم المشاركون أفضل إجابة قدمها النظامان وفقاً لمعيارين هما وضوح الكلام، وملاءمة الإجابة. وجُمعت هذه التقييمات للحصول على النتيجة النهائية لأداء النظامين. كان أداء النظام “LLMVoX” أفضل من حيث وضوح الكلام في 62% من الحالات، كما كان أفضل من حيث ملاءمة الإجابة في 52% من الحالات. في المقابل، كان أداء النظام “Freeze-Omni” أفضل في المعيارين في نسبة 20% فقط من الحالات. وكانت نتائج النظامين متعادلة في بقية الحالات.
نماذج لغوية ناطقة في المستقبل
مع زيادة انتشار النماذج اللغوية الكبيرة في حياتنا اليومية، يتوقع المستخدمون التفاعل معها عبر الكلام بدلاً من الكتابة على لوحة المفاتيح. وبحسب شيخار، من المرجح أيضاً أن نشهد زيادة كبيرة في أعداد النماذج اللغوية الكبيرة المتخصصة في مجالات ومهام محددة.
ويوضح شيخار هذه النقطة قائلاً: “قد يكون لدينا نموذج لغوي كبير متخصص في مجال الأسهم، ونموذج ناطق مدرب تحديداً للعمل في هذا القطاع. ومن خلال اتباع نهج مماثل لنظام “LLMVoX”، يمكن للمطور تدريب نموذج لغوي على بيانات متخصصة في مجال معين ثم ربطه بأداتنا ليصبح قادراً على الكلام”.
ويؤكد شولاكال أن “الميزة الأهم في النظام “LLMVoX” هي سهولة ربطه مع أي نموذج لغوي كبير. وهذه هي الفكرة الأساسية التي يقوم عليها، فهي تتيح للمستخدم التحدث مع أي نموذج لغوي كبير”.
أخبار ذات صلة

أخبار الخريجين: كيف تعلّم عبد الرحمن شاكر إعادة تعريف الأثر في الذكاء الاصطناعي
يوضح خريج جامعة محمد بن زايد للذكاء الاصطناعي كيف تحوّل تركيزه من النشر العلمي إلى إحداث أثر.....
- ما بعد الدكتوراه ,
- البحث ,
- التأثير ,
- الدكتوراه ,
- أخبار الخريجين ,
- الخريجون ,

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- معالجة اللغة الطبيعية ,
- غوغل ,
- التمويل ,
- funding ,
- Arabic ,
- Google ,
- اللغة العربية ,
- النماذج اللغوية الكبيرة ,
- natural language processing ,
- nlp ,
- llms ,

جامعة محمد بن زايد للذكاء الاصطناعي تعلن عن شراكة بحثية استراتيجية مع "مينيرفا هيومانويدز" لتطوير روبوتات بشرية لتطبيقات قطاع الطاقة
تجسّد هذه الشراكة جسراً يربط بين أبحاث الذكاء الاصطناعي التأسيسية والتطبيقات الصناعية.
اقرأ المزيد