
طريقة جديدة تكشف فجوات كبيرة في أداء النماذج اللغوية عبر اللغات المختلفة
الثلاثاء، 19 أغسطس 2025

طوّر المبرمجون نماذج لغوية متعددة اللغات قادرة على الاستجابة لأوامر المستخدمين بلغات مختلفة. إلا أن أداء هذه النماذج يختلف من لغة إلى أخرى، حيث تُظهر أداءً أفضل في اللغات التي تتوفر لها موارد تدريبية ضخمة مثل اللغة الإنجليزية مقارنةً باللغات الأخرى.
لذلك شرع الباحثون في دراسة كفاءة النماذج اللغوية في العمل عبر اللغات المختلفة، أي قدرتها على نقل المعرفة المكتسبة من لغة إلى أخرى، لأن فهم هذه القدرة بشكل أفضل يمكن أن يساعد المطوّرين على بناء نماذج تخدم شرائح أوسع من المستخدمين حول العالم.
وفي هذا السياق، أعد باحثون من جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى دراسة جديدة اقترحوا فيها طريقة آلية جديدة لاختبار كفاءة النماذج اللغوية في العمل عبر اللغات المختلفة. ووجد الباحثون أنه في اللغات التي شملتها الدراسة، والتي تضمنت لغات أفريقية وشرق آسيوية وأوروبية، كان أداء معظم النماذج أقل بنسبة 50% مقارنة بأدائها في اللغة الإنجليزية. والمفاجئ أن هذا التراجع لم يقتصر على اللغات ذات الموارد المحدودة مثل الأمهرية والبنغالية والزولو، بل شمل أيضاً اللغة الصينية التي انخفضت دقة النماذج فيها بمعدل يقارب 60% على الرغم من توفر كميات هائلة من بيانات التدريب.
يقول زيشيانغ شو، الطالب الزائر في جامعة محمد بن زايد للذكاء الاصطناعي والمشارك في إعداد الدراسة: “إن الفجوة بين اللغة الإنجليزية والعديد من اللغات الأخرى كبيرة جداً، وقد صُممت طريقتنا للكشف عن هذه الفجوات بطريقة فعّالة”.
شارك في إعداد الدراسة كل من يانبو وانغ، ويوي هوانغ، وشيويينغ تشن، وجيو جاو، ومينغ جيانغ، وشيانغليانغ تشانغ، وعُرِضت نتائجها في الاجتماع السنوي الثالث والستين لجمعية اللغويات الحاسوبية الذي عُقد في العاصمة النمساوية فيينا.
دراسة الكفاءة عبر اللغات المختلفة
يشرح وانغ، وهو أيضاً طالب زائر في جامعة محمد بن زايد للذكاء الاصطناعي، أن العديد من الدراسات تناولت قدرة النماذج اللغوية على العمل بلغات متعددة، لكن الكفاءة في العمل عبر اللغات المختلفة أمر مختلف. فقدرة النموذج على العمل بلغات متعددة تعني أن بإمكانه الاستجابة لأوامر بلغات مختلفة، أما الكفاءة في العمل عبر اللغات فتشير إلى قدرة النموذج على توظيف المعرفة التي اكتسبها بلغة معينة للإجابة عن الأسئلة المطروحة بلغة أخرى.
درس شو ووانغ وزملاؤهما كفاءة عشرة نماذج لغوية في العمل عبر 16 لغة مختلفة. ولهذه الغاية دمجوا بين أسلوب يُعرف بالبحث الشعاعي ونظام محاكاة قائم على النماذج اللغوية، ونجحوا في توليد ستة آلاف زوج من الأسئلة باللغتين الإنجليزية واللغة المستهدفة.
انطلق الباحثون في عملهم من مجموعات بيانات قائمة باللغة الإنجليزية، واستخدموا النموذج اللغوي “GPT-4o” لترجمتها إلى اللغات المستهدفة. ثم استخدموا البحث الشعاعي ونظام المحاكاة القائم على النماذج اللغوية لإدخال تغييرات طفيفة على الأسئلة تحافظ على المعنى نفسه لكنها تجعل السؤال أصعب في اللغة المستهدفة. ويوضح شو هذه النقطة قائلاً: “هذه التغييرات تضعف قدرة النموذج على التذكّر، ما يجبره على التفكير بعمق للإجابة على السؤال”.
هذه الطريقة تسمح بقياس مقدار المعرفة المنقولة من اللغة الإنجليزية إلى لغات أخرى.
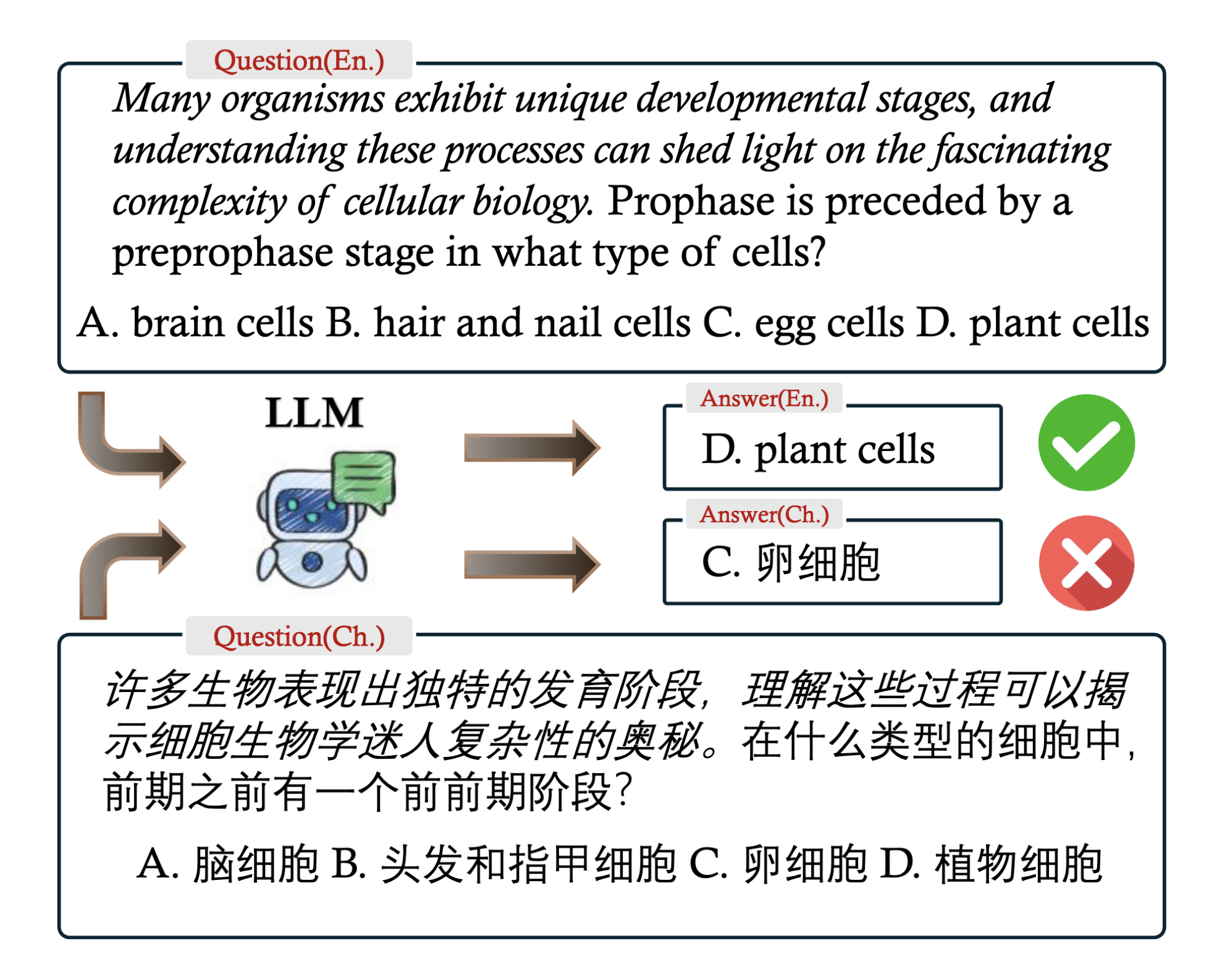
مثال على زوج من الأسئلة باللغتين الإنجليزية والصينية تم توليده باستخدام أسلوب البحث الشعاعي ونظام المحاكاة القائم على النماذج اللغوية. وقد أنشأ الفريق ستة آلاف زوج من هذه الأسئلة في 16 لغة مختلفة. ورغم أن السؤالين بالإنجليزية والصينية يحملان المعنى نفسه تقريباً، إلا أن الفروق الطفيفة بينهما تكشف عن فجوات في الأداء عبر اللغات المختلفة. والمثير للاهتمام أن النموذج “GPT-4o” من شركة “أوبن أيه آي” أجاب عن النسخة الصينية من السؤال بشكل خاطئ.
اختبر الباحثون عدداً من النماذج مفتوحة ومغلقة المصدر وبأحجام مختلفة على هذه الأزواج من الأسئلة. وشملت النماذج التي جرى اختبارها النموذج “Yi Lightning” من شركة “01.AI”، والنموذج “Qwen 2.5 (72B)” من شركة “علي بابا”، والنموذج “Claude 3.5 Sonnet” من شركة “أنثروبيك”، والنموذج “Gemma 2” (بنسختيه 9B و27B) من شركة “جوجل”، والنموذج “LLaMA 3.1” (بنسختيه 8B و70B) من شركة “ميتا”، بالإضافة إلى النماذج “GPT-4o-mini” و”o1-mini” و”GPT-4o” من شركة “أوبن أيه آي”.
ووجد الباحثون تفاوتات كبيرة في الأداء بين اللغة الإنجليزية واللغات الأخرى. على سبيل المثال، انخفضت دقة النموذج “LLaMA 3.1 (8B)” بأكثر من 83% في اللغات المستهدفة.
وفي المتوسط، كان أداء النموذج “Claude 3.5 Sonnet” الأفضل، يليه “GPT-4o”، لكن كلا النموذجين سجلا تراجعاً حاداً في الدقة في بعض اللغات. فقد انخفضت دقة الأول بنسبة 51.5% في لغة اليوروبا وبنسبة 44.1% في اللغة الأمهرية، بينما تراجع أداء الثاني بنسبة 60% في الأمهرية وبنسبة 50.4% في اليوروبا.
كما تباين الأداء بين المجالات المختلفة، حيث كانت نتائج النماذج أضعف في اللغات ذات الموارد المحدودة مثل الأمهرية والعربية واليوروبا في الأسئلة المتعلقة بالعلوم والتكنولوجيا، بينما حققت أداءً أفضل في اللغات ذات الموارد الوفيرة في الموضوع نفسه. في المقابل، أظهرت النماذج أداءً أضعف في الأسئلة باللغة الصينية التي تناولت موضوعات المجتمع والثقافة، وباللغة الكورية في موضوعات الجغرافيا والبيئة.

يُظهر الشكل نتائج تقييم 10 نماذج لغوية على 6600 زوج من الأسئلة الثنائية في 16 لغة مختلفة. وقد حققت النماذج دقة تقارب 100% في اللغة الإنجليزية، لكنها سجلت انخفاضاً في الدقة بمعدل تجاوز 50% في اللغات المستهدفة. وحتى أفضل النماذج، مثل “GPT-4o” و”Claude 3.5 Sonnet”، أظهرت نقاط ضعف كبيرة في الأداء عبر اللغات المختلفة.
ورغم أن الهدف الرئيسي من البحث كان تطوير اختبار يكشف عن نقاط ضعف النماذج في الأداء عبر اللغات المختلفة، إلا أن الباحثين حرصوا على أن يتم ذلك بكفاءة. فقد حسبوا تكلفة توليد الأسئلة باللغات المستهدفة التي كشفت عن نقاط الضعف، ووجدوا أنها بلغت نحو خمسة سنتات أمريكية في المتوسط عبر اللغات. ولكن التكلفة كانت أعلى بكثير في اللغات الأوروبية القريبة من الإنجليزية مثل الفرنسية والألمانية والإسبانية، حيث تطلّب الأمر موارد حسابية أكبر لاكتشاف الأسئلة التي تربك النماذج في هذه اللغات.
بشكل عام، كان أداء النماذج أفضل في اللغات الأوروبية مقارنة بلغات أفريقيا وشرق آسيا. وفي هذا الشأن يقول شو: “سجلت النماذج أفضل أداء لها في اللغات الأقرب إلى الإنجليزية من حيث الدلالات أو المفردات، بينما تراجع أداؤها إلى أدنى مستوياته في اللغات الأبعد عن الإنجليزية بسبب اختلاف خصائصها اللغوية”.
سبل تحسين الكفاءة عبر اللغات المختلفة
ماذا تعني هذه النتائج بالنسبة للباحثين والمطورين في مجال الذكاء الاصطناعي؟
يؤكد الباحثون في دراستهم أن جهودهم لم تكن “مجرد بحث أكاديمي”، بل تمثل خطوة عملية نحو تحسين أداء النماذج اللغوية عبر اللغات المختلفة. وهم يشيرون إلى أن استراتيجيات الضبط الدقيق يمكن أن تُستخدم لتحسين الأداء في لغات أو تراكيب نحوية معينة تواجه فيها النماذج صعوبة.
وقد أثبت الباحثون فعالية هذا النهج، فعندما أجروا ضبطاً دقيقاً للنماذج في اللغة الصينية، لاحظوا تحسناً في أدائها ليس فقط في الصينية، بل أيضاً في اليابانية والكورية. كما أجروا ضبطاً دقيقاً في اللغة الفرنسية فحققوا نتائج مشابهة في لغات قريبة منها مثل الألمانية والإسبانية. ويقول شو إن هذه الملاحظات تؤكد أوجه التشابه ضمن العائلات اللغوية، وإمكانية استخدام الضبط الدقيق بشكل استراتيجي لتحسين الأداء في اللغات المتقاربة. أما لتحسين أداء النماذج في مجالات محددة، فيمكن إضافة بيانات تدريب إضافية لتعزيز أدائها في الموضوعات التي تظهر فيها ضعفاً.
باختصار، يرى الباحثون أن هذا التحليل المفصّل يمثل خطوة مهمة نحو تطوير نماذج لغوية أكثر فائدة لمتحدثي مجموعة واسعة من اللغات. وقد نشر الفريق مجموعة البيانات الخاصة بالدراسة، وهو يدعو جميع المهتمين بكفاءة النماذج اللغوية عبر اللغات المختلفة إلى استخدامها.
أخبار ذات صلة

جامعة محمد بن زايد للذكاء الاصطناعي تصدر تقريرها حول الذكاء الاصطناعي للجنوب العالمي في الهند
يحدّد التقرير 12 سؤالاً بحثياً جوهرياً الهدف منها توجيه جهود العشرية القادم البحثية في اتجاه تطوير ذكاء.....
- قمة ,
- الشمولية ,
- AI4GS ,
- الجنوب العالمي ,
- تقرير ,
- التأثير الاجتماعي ,
- عادل ,

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- natural language processing ,
- غوغل ,
- التمويل ,
- funding ,
- Arabic ,
- nlp ,
- النماذج اللغوية الكبيرة ,
- Google ,
- llms ,
- اللغة العربية ,
- معالجة اللغة الطبيعية ,

تحسين فهم النماذج اللغوية للثقافة العربية عبر تبادل المعرفة بين الثقافات
تكشف أبحاث جديدة من جامعة محمد بن زايد للذكاء الاصطناعي كيف يمكن لعدد محدود من الأمثلة الموجّهة.....
- معالجة اللغات الطبيعية ,
- EMNLP ,
- اللغة العربية ,
- الثقافة ,
- الثقافة العربية ,
- nlp ,