
كشف التزييف العميق في حالات التناوب اللغوي
الثلاثاء، 12 أغسطس 2025

يشير التزييف العميق إلى استخدام الذكاء الاصطناعي لإنشاء مقاطع فيديو تبدو حقيقية لكنها تُظهر أحداثاً لم تقع في الحقيقة. ومع تزايد انتشار نماذج الذكاء الاصطناعي التوليدي القادرة على إنتاج مقاطع فيديو عالية الجودة بسرعة وتكلفة منخفضة بالاعتماد على أوامر نصية بسيطة، أصبحت هذه الظاهرة أكثر شيوعاً، مع ما تحمله من مخاطر تقويض الثقة بالأفراد والمؤسسات.
ورغم أن الباحثين طوروا أدوات تكشف التزييف العميق، إلا أن معظم هذه الأدوات جرى تدريبها على اللغة الإنجليزية، مما يحد من فعاليتها في اللغات الأخرى.
وهناك تحدٍ آخر يتمثل في أن الناس يتواصلون في كثير من الحالات باستخدام كلمات من أكثر من لغة واحدة. تُعرف هذه الظاهرة باسم التناوب اللغوي، وهي شائعة في العالم العربي، حيث يدمج كثيرون بين العربية والإنجليزية في جملة واحدة. ورغم سهولة فهم الحديث بهذا الأسلوب بالنسبة للبشر، إلا أنه يمثل ثغرة بالنسبة لأنظمة كشف التزييف العميق المُدرّبة على لغة واحدة، كما يوضح الدكتور محمد حارس خان، الأستاذ المساعد في قسم الرؤية الحاسوبية بجامعة محمد بن زايد للذكاء الاصطناعي.
يعمل خان، بالتعاون مع زملائه من الجامعة وجامعة موناش، على معالجة هذه المشكلة من خلال بناء أول مجموعة بيانات تتضمن ساعات طويلة من تسجيلات الصوت والفيديو التي تركز تحديداً على التناوب اللغوي بين العربية والإنجليزية.
وقد اختبر الباحثون عدداً من أدوات كشف التزييف العميق على مجموعة البيانات الجديدة التي أطلقوا عليها اسم “ArEnAV”، ووجدوا أن التناوب اللغوي أدى إلى تراجع كبير في قدرة هذه الأدوات على كشف المقاطع المزيّفة. ونُشرت هذه النتائج مؤخراً في دراسة بعنوان “أخبرني، هل هذا حقيقي أم مزيف؟” لتؤكد الحاجة الملحّة إلى موارد تعكس ديناميكية التواصل الواقعي.
يقول كارتِك كوكريا، الباحث المساعد في جامعة محمد بن زايد للذكاء الاصطناعي والمؤلف الرئيسي للدراسة، إن عمل الفريق يقع في صميم الجهود الرامية إلى ضمان أن تكون تكنولوجيا الذكاء الاصطناعي واعية ثقافياً ومسؤولة اجتماعياً.
وشارك أيضاً في إعداد الدراسة كل من بارول غوبتا، وإنجي حامد، وثامار سولوريو، وأبهيناف دهال.
تحديات التناوب اللغوي
التناوب بين اللغتين العربية والإنجليزية ليس ظاهرة نادرة، بل أمر شائع جداً، خاصة في دولة الإمارات العربية المتحدة ودول الخليج الأخرى.
وبينما أنشأ الباحثون قواعد بيانات متعددة اللغات لدعم أدوات كشف التزييف العميق، إلا أن الكلام في تلك القواعد عادة ما يكون بلغة واحدة فقط. هذا الأمر دفع خان وكوكريا وزملاءهما إلى بناء مجموعة البيانات “ArEnAV”، وهي أكبر وأشمل مجموعة بيانات مصممة خصيصاً لاختبار قدرة أنظمة كشف التزييف العميق على التعامل مع محتوى يتضمن تناوباً لغوياً بين العربية والإنجليزية.
تتكون مجموعة البيانات من 765 ساعة من مقاطع الفيديو العربية المأخوذة من موقع يوتيوب، والتي عُدّلت لتشمل حالات من التناوب اللغوي بين العربية والإنجليزية وتغيير اللهجات.
يتحدث خان عن هذه المجموعة قائلاً: “إن حجم هذه المجموعة غير مسبوق، وهي تعالج مباشرة تحدي تعدد اللغات الذي أخفقت مجموعات البيانات السابقة في التعامل معه. وتكمن قوتها في أنها تتضمن تناوباً لغوياً وتنوعاً في اللهجات ضمن الجملة الواحدة، مما يجعلها مجموعة معيارية تمثل الواقع إلى حد كبير”.
بناء مجموعة البيانات “ArEnAV“
بدأ الباحثون في إنشاء مجموعة البيانات “ArEnAV” من خلال جمع روابط مقاطع يوتيوب من مجموعة بيانات موجودة سابقاً اسمها “VisPer”. ثم قسّموا المقاطع الطويلة إلى مقاطع قصيرة وعالجوها لاستخراج تعابير وجه المتحدثين في كل إطار. بعد ذلك، ولّد الباحثون نصوصاً مفرّغة لكل مقطع، ثم قاموا بمواءمة هذه النصوص مع الصوت للحصول على توقيت يمثل بدقة لحظات التناوب اللغوي بين العربية والإنجليزية.
استخدم الفريق بعدها النموذج اللغوي “GPT-4.1-mini” من شركة “أوبن أيه آي” لإدخال تعديلات على النصوص تشبه التغييرات التي تحدث في حالة التزييف العميق. وقد شملت التعديلات ثلاثة أنواع: تغييرات في المعنى فقط، وتغييرات في المعنى واللهجة، وتغييرات في المعنى واللغة (أي الترجمة من العربية إلى الإنجليزية لمحاكاة التناوب اللغوي). ويشرح كوكريا هذه الخطوة قائلاً: “قدّمنا للنموذج اللغوي تعليمات دقيقة للسيطرة على التعديلات وضمان واقعيتها”.
بعد تعديل النصوص، أنشأ الباحثون تسجيلات صوتية جديدة تحافظ على الخصائص الصوتية للمتحدثين الأصليين باستخدام أسلوب يسمى استنساخ الصوت. وأخيراً، ولّدوا مقاطع فيديو جديدة متوافقة مع المقاطع الصوتية المعدّلة.
يعلّق خان على هذه العملية قائلاً: “كان بناء مجموعة البيانات “ArEnAV” عملية معقدة تطلبت عدة أنظمة لأن الاعتماد على سلسلة أدوات واحدة لم يكن كافياً بسبب تعقيدات علم الأصوات العربية والحاجة إلى محاكاة حركة الشفاه في أكثر من لغة واحدة”.
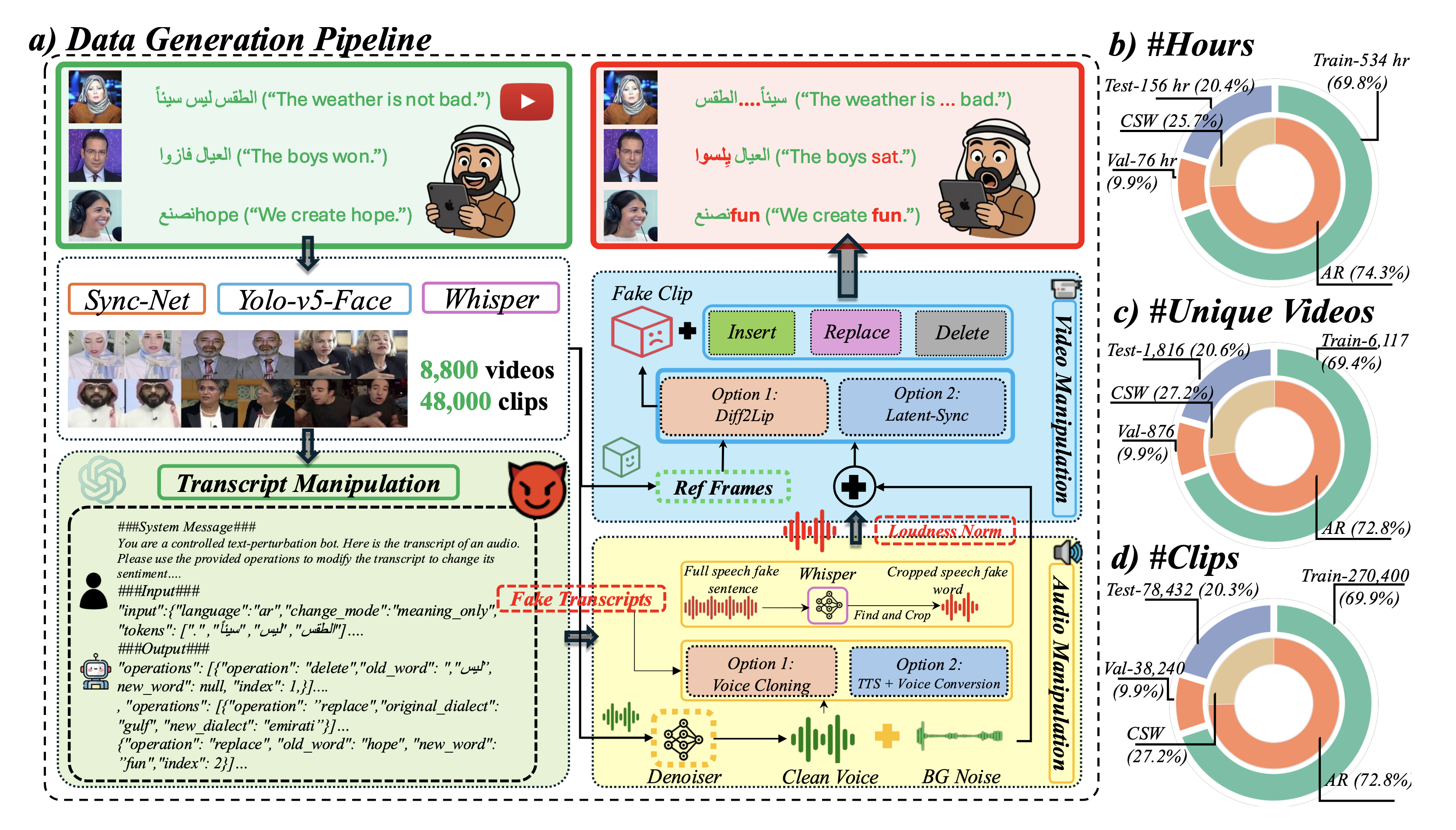
مراحل توليد البيانات في مجموعة البيانات “ArEnAV” (في الجهة اليسرى) وتوزيع البيانات على مجموعات التدريب والتحقق والاختبار (في الجهة اليمنى).
خداع البشر بالتزييف العميق
ربما يكون ما يجعل التزييف العميق خطيراً للغاية ليس فقط قدرته على خداع أنظمة الكشف الآلية، بل قدرته أيضاً على خداع البشر أنفسهم. فقد أجرى الباحثون تجربة تضمنت عرض مجموعة من المقاطع في مجموعة البيانات “ArEnAV” على أشخاص لتقييم قدرتهم على تمييز المقاطع الحقيقية من المزيفة. وكانت النتائج لافتة، حيث لم تتجاوز دقة المشاركين، وكثير منهم ناطقون أصليون بالعربية، في التمييز بينها نسبة 60% فقط. كما واجهوا صعوبة في تحديد اللحظات التي جرى فيها تعديل الكلام داخل مقاطع الفيديو.
ووجد الباحثون أيضاً أن 85% من المشاركين أخفقوا في اكتشاف التزييف عندما طالت التعديلات الكلمات الإنجليزية. ويعزو الفريق هذه النتيجة إلى أن أدوات استنساخ الصوت أكثر تطوراً ودقة في اللغة الإنجليزية مقارنة بالعربية. وهناك تفسير آخر محتمل، وهو أن التقلبات الطبيعية في النبرة عند الانتقال من لغة إلى أخرى قد تجعل التغييرات أقل وضوحاً على المستمع.
مجال للتحسين والاتجاه المستقبلي
قسّم الباحثون مجموعة البيانات “ArEnAV” إلى مجموعات قياسية للتدريب والتحقق والاختبار، ثم قيّموا أداء عدة أنظمة لكشف التزييف العميق عليها في حالة عدم وجود تدريب مسبق وبعد إعادة الضبط.
أظهرت النتائج أن النماذج التي دُرّبت على مجموعات بيانات قياسية مثل “AV-1M” أو “LAV-DF” سجلت انخفاضاً في الدقة وتحديد مواقع التلاعب تجاوز 35% عند اختبارها على مجموعة البيانات “ArEnAV”. كما تبيّن أن بعض أنظمة الكشف التي حققت أداءً جيداً على مجموعات بيانات أحادية اللغة فشلت في كشف المحتوى المزيف الذي يتضمن تناوباً لغوياً.
يؤكد الدكتور خان أن هذه النتائج تحمل أبعاداً عملية مهمة بالنسبة للعلاقة المعقدة بين التكنولوجيا والسياسات العامة اليوم: “يجب أن تكون أنظمة فحص التزييف العميق في منطقة الشرق الأوسط وشمال إفريقيا قادرة على التعامل مع المحتوى الذي يتضمن تناوباً لغوياً. فالاعتماد على نماذج أحادية اللغة يترك ثغرات خطيرة تجعل المنصات عرضة للمعلومات المضللة وانتحال الهوية”.
ويضيف قائلاً إن موارد مثل مجموعة البيانات “ArEnAV” يمكن أن تكون أداة حيوية لوسائل الإعلام ومجموعات التحقق من صحة المعلومات التي تبني أنظمة للتحقق من صحة المحتوى. كما يمكن أن تكتسب أهمية خاصة في الفترات التي تشهد أحداثاً مجتمعية كبرى مثل الانتخابات.
نشر الباحثون مجموعة البيانات عبر إصدار مقيّد يتطلب توقيع المستخدم على اتفاقية ترخيص. ويؤكد خان أن الهدف من ذلك هو الموازنة بين إتاحة مجموعة البيانات للباحثين وضمان استخدامها بشكل مسؤول.
أخبار ذات صلة

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- Google ,
- Arabic ,
- funding ,
- التمويل ,
- غوغل ,
- اللغة العربية ,
- llms ,
- معالجة اللغة الطبيعية ,
- النماذج اللغوية الكبيرة ,
- nlp ,
- natural language processing ,

جامعة محمد بن زايد للذكاء الاصطناعي تعلن عن شراكة بحثية استراتيجية مع "مينيرفا هيومانويدز" لتطوير روبوتات بشرية لتطبيقات قطاع الطاقة
تجسّد هذه الشراكة جسراً يربط بين أبحاث الذكاء الاصطناعي التأسيسية والتطبيقات الصناعية.
اقرأ المزيد
تحسين فهم النماذج اللغوية للثقافة العربية عبر تبادل المعرفة بين الثقافات
تكشف أبحاث جديدة من جامعة محمد بن زايد للذكاء الاصطناعي كيف يمكن لعدد محدود من الأمثلة الموجّهة.....
- معالجة اللغات الطبيعية ,
- nlp ,
- EMNLP ,
- اللغة العربية ,
- الثقافة ,
- الثقافة العربية ,