
الفن الرقمي من العشوائية إلى الدقة في التنفيذ
الاثنين، 21 يوليو 2025

تخيّل أنك تطلب من Midjourney أو DALL-E إضافة تاج على صورة كلب تم إنشاؤها من نصٍ مُدخلٍ في أحدهما، لكن النتيجة غالباً صورة جديدة كلياً: وضعية مختلفة، وخلفية جديدة، وربما حتى كلب آخر!
يقول شاوان زي وينجينغ كونغ، وهما طالبين في برنامج الدكتوراه في جامعة كارنيجي ميلون وجامعة محمد بن زايد للذكاء الاصطناعي: “كنا نلاحظ هذا الانحراف باستمرار، حيث إن كلمة صغيرة في النص أو الأمر المدخل قد تكون سببا في توليد صورة مختلفة تماماً”.
ولا يشكل عدم القدرة على التحكم في المخرجات التي يتم توليدها مجرد أمر مزعج لفناني الفن الرقمي، بل إنه شيء يحدّ من فائدة الذكاء الاصطناعي في مجالات مثل الإعلانات أو الطب حيث التنفيذ الدقيق للتعديلات له أهميته؛ والدقة في التنفيذ هي ما سعى زي وكونغ، بالضبط، إليه من خلال ورقتهما البحثية الجديدة التي قدماها الأسبوع الماضي في “المؤتمر الدولي لتعلم الآلة” (ICML)، والتي يقترحان بها حلاً لهذا التحدي.
وقد تناولت الورقة البحثية بالشَّرح نظرية “المفاهيم الدقيقة” في الرياضيات وعلاقتها بنموذج “ConceptAligner” التجريبي الذي يتيح إمكانية إنشاء الصور وتعديلها بدقة عالية دون أي إدخال أو إضافة لأي تغيير أو تغييرات غير مرغوب فيها.
الملاحظ، في هذا الصدد، أن مولدات الصور الحديثة تحول أو تترجم الأوامر النصية إلى “تضمينات متجهة” في نطاق عالي الأبعاد، ثم تقوم بإزالة الضوضاء تدريجياً من وحدات البكسل العشوائية إلى أن تتشكل الصورة، غير أن المشكلة هي أن هذه “التضمينات المتجهة” متشابكة بمعنى أن المتجهات التي تصف “كلباً يضع تاجاً من الألماس” و”كلباً يضع تاجاً من الزهور” قد تكون مختلفة جداً وقد تؤثر على الصور المولدة بطرق غير متوقعة.
الحل المقترح لهذه المشكلة هو تحليل التضمينات النصية [تضمينات متجهة لتمثيل بيانات اللغة الطبيعية] وتقسيمها إلى وحدات مستقلة تُسمى “المفاهيم الدقيقة”. واعتمادا على هذه المقاربة يصبح العنصر المشترك في الجملتين السالفتي الذكر هو “الكلب” في حين أن الفرق بينهما هو التاج الذي إذا ما تمكنا من عزله وتمثيله بالحد الأدنى من التوصيفات اللغوية وتمكنا من إرساء العلاقة بين النص والمفهوم البصري، فيمكننا عندئذ تعديل التاج فقط دون التأثير على الصورة بأكملها؛ ويقوم – وبناءً على ما تقدم – جوهر الورقة البحثية التي قدمها الطالبين على شرطين استناداً لهما يمكن فك هذا التشابك في التضمينات اللغوية/النصية بين الكلي والخاص [أي الدقيقة].
الشرط الأول: يتطلب تنوعاً في البيانات، حيث إن وجود مجموعة كبيرة من المفاهيم الكلية مثل “القطط” و”الكلاب” يساعد في تمييز المفاهيم البصرية الخاصة مثل “العيون” و”الأنوف” التي تظهر أنماط متغيرة ومختلفة.
الشرط الثاني: يفرض قيد التباعد – أي أن كل مفهوم نصي يكون تأثيره فقط على مجموعة محدودة من المفاهيم البصرية، والذي من دونه [أي القيد] لا يمكن فك التشابك بين المفاهيم الكلية والخاصة.
النتيجة؟ تحديد مكونات مستقلة، حيث يرتبط كل عامل كامن – اللون، الوضعية، المادة – بمفتاح تحكم واحد يمكن للمستخدم التحكم فيه، وهذه قفزة كبيرة مقارنة بالأعمال السابقة التي كانت تحدد فقط مجموعات عامة من السمات، وليس المكونات الدقيقة الفردية. ويمكن، مع هذا التحديد الدقيق، ترجمة أوامر التعديل (مثل “أضف تاجاً من الألماس”) إلى تعديلات دقيقة على مستوى المفاهيم، مما يتيح إيجاد أداة لتوليد الصور يمكن التحكم فيها بدقة عالية.
بناء نموذج ConceptAligner
اعتماداً على مقاربتهم النظرية، قام الفريق بتطوير نظام من أربعة أجزاء:
- شبكة النصوص: وهي وحدة للتعرف وإعادة التشكيل تقوم بتحويل التضمينات النصية الأولية إلى 64 مفهوماً نصياً دقيقاً [خاصاً].
- مشفر الصور: وهو آلية لنمذجة المتغيرات العشوائية أو الدقيقة التي لا يمكن تفسيرها أو فهمها نصياً.
- شبكة المفاهيم: وهي جزئية مهمتها التعرف على الروابط الدلالية الدقيقة [روابط انتقائية وذات معنى] بين الكلمات والبكسلات باستخدام مصفوفة ثنائية تفرض قيوداً تجعل بعض الروابط نشطة وأخرى غير نشطة.
- محول الانتشار: هو نموذج توليدي مهيأ باستخدام تقنية LoRA، يولد مخرجات اعتماداً على متجهة منظمة ومكونة من مفاهيم بصرية واضحة ومفككة بدلاً من الاعتماد على نصوص توجيهية [أوامر] غامضة.
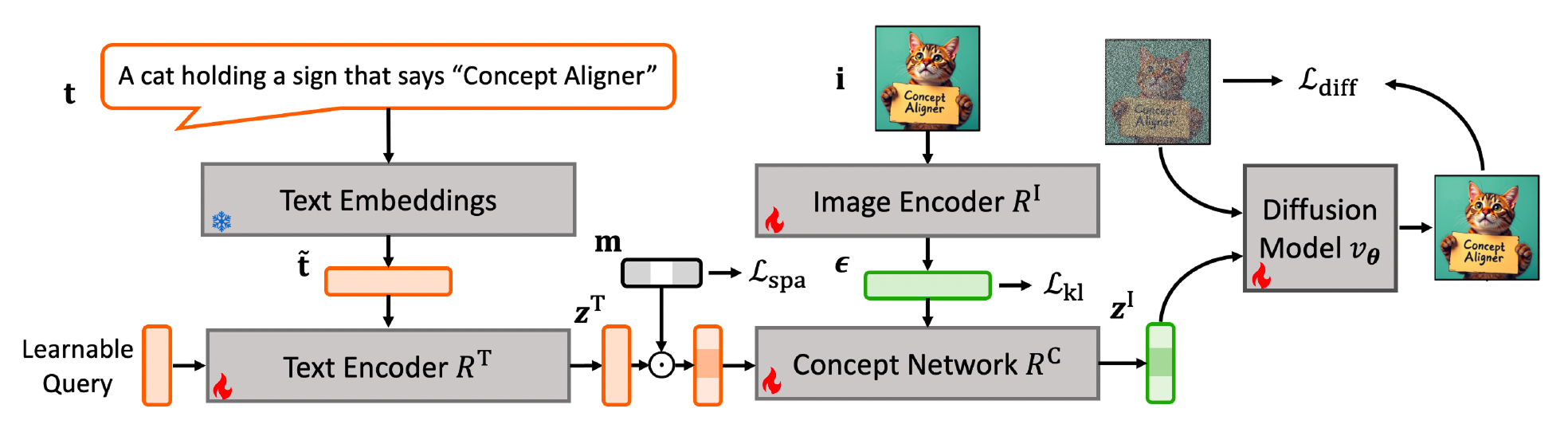
تفوق ConceptAligner في اختبار Emu Edit (مجموعة من 3,589 زوجاً من النصوص مثل “كلب يبتسم” إلى “كلب مندهش”) على نموذج Stable Diffusion 3.5 وستة نظم أخرى لتوليد الصور على مستوى كل المقاييس المرتبطة بالتحكم.
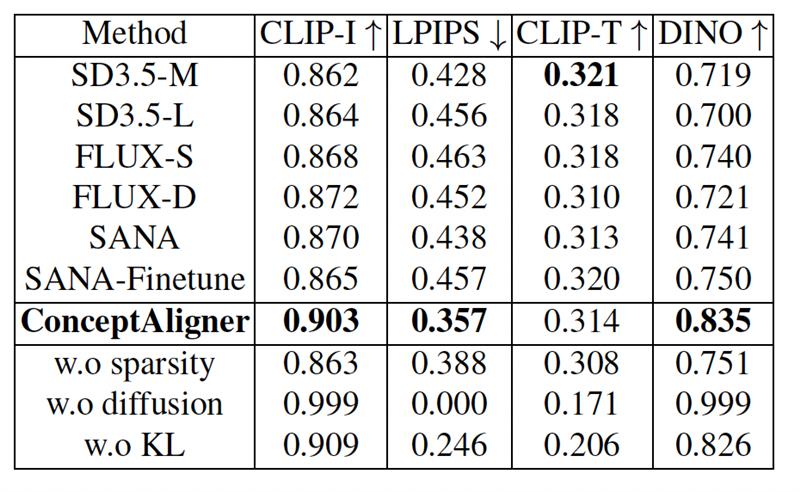
المثال أعلاه يُظهر بوضوح تفوق نموذج ConceptAligner الذي استبدل فقط “تاج الألماس” بـ “تاج الزهور” على رأس كلب لابرادور مقارنة مع النماذج المنافسة التي غيرت لافتة المتجر والخلفية.

بفضل قدرته على تحديد/التعرف على المفاهيم الدقيقة [الخاصة]، يُمَكِننا نموذج ConceptAligner من استخدام تمثيل مختزل لمدخلات المستخدم بدلاً من التضمينات النصية الطويلة والمركبة. وبفضل هذه القدرة يستطيع النموذج معالجة التعديلات بسرعة كبيرة ما يرى فيه زي وكونغ تغيرا جذرياً سيشكل منعطفاً في أسلوب إنتاج الفن الرقمي، ومعه يصبح فنان كوميكس – مثلاً – قادراً على تعديل حاجب شخصية أو مصمم أزياء يجرب أنماط القماش من دون أي تغييرات غير مقصودة في الصور المولدة.
تطبيقات أخرى لنموذج ConceptAligner
- التصوير الطبي: تحويل صور التصوير المقطعي إلى صور التصوير المقطعي بالإصدار البوزيتروني دون تشويه، والتي قد تساعد في التشخيص.
- الروبوتات: تنفيذ مهمة مثل “الإمساك بالمقبض الأحمر بدلا من اللوحة الزرقاء” تصبح مهمةً مقدورٌ عليها عندما يتم التمييز بين اللون والشكل.
- الوصول: أدوات يمكنها زيادة قوة التباين [contrast] بين النص المكتوب والخلفية أو تساعد في إبراز حواف الأشياء يمكنها أن تساعد الأشخاص ذوي الإعاقات البصرية وتحسن تجربتهم الخاصة بقراءة أي محتوى.
يُشار إلى أن نموذج ConceptAligner ما يزال يواجه صعوبات مع اللغات منخفضة الموارد والنصوص عالية التجريد –وعن هذه الصعوبة يوضح زي وكونغ أنه “في حال عدم ظهور المفهوم في بيانات التدريب، فإن عزله يكون غير ممكنا” فعلى سبيل المثال فإن هويات المشاهير صعبة بشكل خاص لأن مظهر النجم – الشعر، العيون، المظهر العام – هو نفسه مفهوم مركب.
وهناك أيضاً مخاطر سوء الاستخدام ، إذ يمكن للتحكم الدقيق في النموذج أن يسهل توليد ما يعرف بـ “التزييف العميق”، والذي يؤكد الفريق البحثي بخصوصه على ضرورة اعتماد فلاتر قوية لمنع المحتوى غير اللائق أو اللاأخلاقي مع اشتراط موافقة صريحة لتعديل الوجوه الحقيقية واقتراح وضع علامات مائية على التعديلات – التي بدورها يحذر الباحثان من أن ضمان متانتها [أي العلامات المائية] يمثل تحدياً تقنياً مستمراً.
يوجه الفريق أنظاره الآن نحو تطوير الفيديو، حيث يتطلب الاتساق الزمني أن يحتفظ كائن، مثل “كلب”، بالهوية نفسها في الفيديو، حيث تُعد المعلومات الزمنية أداة حيوية لفصل المفاهيم في بيانات الفيديو. ويطمح الباحثان إلى الاستفادة من قدرات نموذجهم في توليد “القصص التفاعلية” التي تجمع بين النصوص والصور والصوت لإنشاء قصص متعددة الوسائط بأمر صوتي واحد.
كما يخطط الفريق، في خطوة طموحة، لإطلاق منصة تكون متاحة للجميع مدعومة بنماذج أساسية متقدمة، وذلك بهدف تمكين المستخدمين – حتى على أجهزة الحاسوب المحمولة البسيطة – من تعديل الصور بسرعة وسهولة عبر أوامر.
كان الفن بالذكاء الاصطناعي في السابق يشبه السحر – مثير للإعجاب ولكنه غير متوقع.. لكن التحكم في المفاهيم الخاصة تجعل من النموذج الذي طوره الباحثان نموذجا قويا شبيها بآلة موسيقية رقمية دقيقة سيصبح معها العشوائية في توليد الصور شيئاً من الماضي.
أخبار ذات صلة

أخبار الخريجين: كيف تعلّم عبد الرحمن شاكر إعادة تعريف الأثر في الذكاء الاصطناعي
يوضح خريج جامعة محمد بن زايد للذكاء الاصطناعي كيف تحوّل تركيزه من النشر العلمي إلى إحداث أثر.....
- أخبار الخريجين ,
- ما بعد الدكتوراه ,
- البحث ,
- التأثير ,
- الدكتوراه ,
- الخريجون ,

جامعة محمد بن زايد للذكاء الاصطناعي تصدر تقريرها حول الذكاء الاصطناعي للجنوب العالمي في الهند
يحدّد التقرير 12 سؤالاً بحثياً جوهرياً الهدف منها توجيه جهود العشرية القادم البحثية في اتجاه تطوير ذكاء.....
- عادل ,
- التأثير الاجتماعي ,
- تقرير ,
- الجنوب العالمي ,
- AI4GS ,
- الشمولية ,
- قمة ,

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- natural language processing ,
- nlp ,
- النماذج اللغوية الكبيرة ,
- llms ,
- معالجة اللغة الطبيعية ,
- اللغة العربية ,
- Google ,
- Arabic ,
- funding ,
- التمويل ,
- غوغل ,