
بين النظرية والتطبيق: مجموعة بيانات CausalVerse تغيّر قواعد اختبار نماذج الذكاء الاصطناعي
الأربعاء، 03 ديسمبر 2025

بإمكان الكثير من أنظمة الذكاء الاصطناعي الحديثة رصد الأنماط، مثل التعرّف على القطط في الصور، أو تتبّع الاتجاهات في لوحات البيانات، أو التقاط العبارات المألوفة في النصوص. ولكن عدداً أقل بكثير من هذه الأنظمة يستطيع تفسير أسباب ظهور تلك الأنماط أو التنبؤ بنتيجة أي تدخل يحدث. هذه القدرة على فهم الأسباب بدلاً من الاكتفاء برصد العلاقات تمثل الهدف الأساسي لما يُعرف بالتعلّم بالتمثيل السببي.
هذا يعني من الناحية العملية تحديد المتغيرات الخفية والعلاقات التي تولّد البيانات فعلياً، بدلاً من الاكتفاء بالعناصر السطحية. ولكن أبحاث التعلّم بالتمثيل السببي تواجه مشكلة مزمنة تتمثل في عدم وجود بيئة اختبار تجمع بين الواقعية والدقة بالقدر الذي يسمح بالحكم على ما إذا كانت الطريقة المتبعة أدت فعلاً إلى تحديد الأسباب الصحيحة. فإما أن نجد بيئات فيزيائية تجريبية مبسطة فيها علاقات سببية معلومة بشكل كامل لكنها تفتقر إلى الواقعية، أو بيانات حقيقية ذات مظهر بصري ثري ولكن دون وسيلة للتحقق مما إذا كان النموذج قد حدد العلاقة السببية الصحيحة.
في هذا السياق، تسعى ورقة بحثية أعدّها باحثون من جامعة محمد بن زايد للذكاء الاصطناعي وقُدمت في مؤتمر نظم معالجة المعلومات العصبية لعام 2025 إلى حل هذه الإشكالية من خلال “CausalVerse”، وهي مجموعة بيانات معيارية كبيرة مفتوحة تجمع بين التعقيدات البصرية الدقيقة ومعرفة المتغيرات السببية الكامنة والرسوم البيانية بشكل كامل.
يقول غوانغي تشن، الباحث العلمي والمؤلف الرئيسي للدراسة: “شهدت السنوات القليلة الماضية تطورات نظرية لافتة في مجال التعلم بالتمثيل السببي. ولكن لم تُختبر حتى الآن إمكانية تطبيق هذه الطرق على مسائل معقدة في العالم الحقيقي. ولكي يصبح التعلم بالتمثيل السببي عملياً وفعالاً، نعتقد أن تطوير بيئة اختبار موثوقة هو خطوة أولى بالغة الأهمية”.
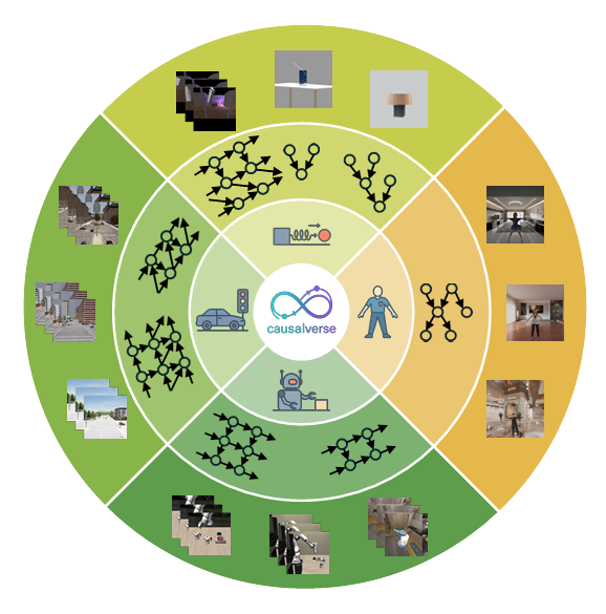
نطاق واسع وبيئات متعددة
تمثل مجموعة البيانات “CausalVerse” في جوهرها مجموعة من العناصر التي جرى توليدها بواسطة الأدوات المستخدمة في تطوير الألعاب ونماذج الروبوتات الأولية، بحيث يبدو مظهر هذه العناصر وسلوكها قريباً من تعقيد العالم الواقعي الذي ستواجهه النماذج. وتتميز هذه المجموعة بضخامة حجمها، حيث تضم نحو 200 ألف صورة و300 مليون إطار فيديو، موزعة على 24 مشهداً فرعياً في أربعة مجالات تغطي البيئات الساكنة والمتحركة معاً، وهي توليد صور ساكنة، ومحاكاة فيزيائية ديناميكية، وتعامل الروبوت مع الأجسام، والمواقف المرورية.
يقوم كل مشهد على مخطط سببي متكامل يتضمن المتغيرات الكامنة التي تحرّكه، ما يتيح للباحثين مقارنة ما تتعلّمه النماذج مباشرة مع العوامل السببية المعلومة، بدلاً من الاكتفاء بالاستدلال غير المباشر من خلال دقة الأداء في المهام اللاحقة. كما جرى تنظيم مجموعة البيانات المعيارية بشكل هرمي (من المجال إلى المشهد ثم إلى الحالة الفردية)، مما يسمح بالتحكم في مستوى التعقيد بصورة منهجية، بدءاً من جسم واحد تحت إضاءة متغيّرة، وصولاً إلى تفاعلات بين عدة أجسام متحركة ذات أهداف متنافسة.

ويبرز بين دوافع البحث التعارض القائم بين الواقعية والدقة الصارمة الذي أعاق تطور أبحاث التعلّم بالتمثيل السببي. فمجموعات البيانات الاصطناعية السابقة تسمح بالتحقق من القدرة على تحديد السبب، لكنها نادراً ما تشبه العالم الحقيقي، وغالباً ما تقتصر على عدد محدود من العوامل الكامنة. أما مجموعات البيانات التي تبدو واقعية، فتعتمد عادة على مؤشرات غير مباشرة (مثل التعميم بين المجالات أو النقل أو الاستدلال)، لكنها تفتقر إلى علاقات سببية معلومة، ما يمنع التأكد مما إذا كان النموذج قد حدد فعلاً العوامل الصحيحة أم أنه اكتفى بتحديد علاقات تصادف أنها صحيحة في تلك الحالة.
تسعى مجموعة البيانات “CausalVerse” إلى الجمع بين الجانبين من خلال توفير مشاهد تحاكي الواقع بدرجة عالية، إلى جانب شروح سببية دقيقة، مع إمكانية إعادة ضبط العلاقة السببية والتدخلات بحيث يمكن تقييم الطرق المختلفة عند تحقق الافتراضات النظرية المفضلة أو اختبار صحتها عندما لا تتحقق تلك الافتراضات. وهذه المرونة مهمة. فإذا كانت الافتراضات النظرية تتطلب مشاهد متعددة أو أنماطاً زمنية معينة، فيمكن توليدها بدقة. وإذا كان الهدف اختبار فعالية الطريقة في غياب تلك الشروط، فهذا ممكن أيضاً.
عندما سُئِل تشن عن أبرز النتائج التي فاجأته أثناء إعداد الورقة البحثية، أجاب قائلاً: “وجدنا أن دقة تمثيل الأجسام تشكل تحدياً كبيراً يؤثر على النتائج النهائية. وهذا يعني أن هناك عوامل عديدة قد تؤثر على أداء التعلّم بالتمثيل السببي في البيئات الواقعية، ما يسلط الضوء على وجود مجال واسع للتحسين وإجراء المزيد من البحوث”.
من المشاهد الساكنة إلى العوالم الديناميكية
بالنسبة للباحثين في مجال الذكاء الاصطناعي، فإن تنوّع العلاقات السببية التي تتيحها مجموعة البيانات “CausalVerse” مهم بنفس قدر أهمية حجمها الكبير، حيث تتدرج المشاهد الديناميكية في مجال الفيزياء من تمثيلات مجمّعة في إطار واحد (مثل أسطوانة تضغط نابضاً، أو انكسار الضوء عبر وسط مادي) إلى مسارات زمنية كاملة (تشمل السقوط الحر، وحركة المقذوفات، وتصادمات الأجسام المفردة والمتعددة). أما مشاهد علم الروبوتات، فتشمل التحكم بالأجسام والتنقل، مع ما يتطلبه ذلك من ترابط تسلسلي وديناميكيات تماس مع البيئة المحيطة. وفي مشاهد المرور، يجري تمثيل تفاعلات بين عدة أجسام في مدن مختلفة وفي ظروف طقس وكثافات مرورية متنوعة، حيث يمكن لتغيّر طفيف في سلوك أحد الأطراف أن يؤدي إلى حوادث أو إلى اندماجات مرورية سلسة، وهي بالضبط من الظواهر التي تحدث نتيجة تدخلات يدّعي التعلّم بالتمثيل السببي قدرته على تحديدها. وتشمل المتغيرات الكامنة نطاقاً واسعاً يمتد من عدد محدود من العوامل العامة إلى مئات المتغيرات لكل إطار في المجالات الزمنية (المواضع والاتجاهات والسرعات)، ما يضع الطرق التي لا تنجح إلا في عوالم تجريبية مبسطة قليلة المتغيرات أمام اختبار صارم وصريح.
كما توفر مجموعة البيانات “CausalVerse” إطاراً موحداً لقياس ما إذا كانت الطرق المختلفة تحدد الأسباب فعلاً. فهي تظهر القدرة على تحديد السبب باستخدام معامل الارتباط المتوسط، وذلك بعد إجراء مطابقة مثلى بين المتغيرات الكامنة المعلومة وتلك التي تعلّمها النموذج، إضافة إلى قياس أداء الانحدار، ونسخة موسّعة من معامل الارتباط المتوسط تعالج الحالة الشائعة التي يتعلّم فيها النموذج عدداً من المتغيرات الكامنة يفوق العدد الحقيقي الموجود في البيانات.
أخضع المؤلفون مجموعة واسعة من الطرق الشائعة في التعلّم بالتمثيل السببي لاختبارات دقيقة في ظل افتراضات غير مستوفاة، أي ضمن مشاهد تبدو واقعية بصرياً لكنها لا تنسجم تماماً مع المتطلبات النظرية لكل طريقة. ففي ثلاث مشاهد ساكنة (“كرة على المنحدر” و”الأسطوانة والنابض” و”انكسار الضوء”)، حقق نموذج خاضع للإشراف يمثل الحد الأعلى للأداء ويتعلم المتغيرات الكامنة مباشرة من الشروح السببية، نتائج تقترب من الكمال، ما يثبت أن سعة المُشفر ليست عنق الزجاجة في هذه الحالة. أما الطرق غير الخاضعة للإشراف في التعلّم بالتمثيل السببي، فترسم صورة مختلفة، حيث ينجح العديد منها في تحديد إشارات تفسيرية على نحو إجمالي، لكنها تواجه صعوبة في تحديد المتغيرات الكامنة وراء كل حالة بشكل دقيق، وهو المستوى المطلوب للوصول إلى تفسير سببي واضح ودقيق.
ويزداد الأمر صعوبة عند الانتقال إلى التعلّم بالتمثيل السببي في المجالات الزمنية. ففي مشهدي فيديو (“السقوط البسيط” في مجال الفيزياء و”دراسة في علم الروبوتات”)، سجّلت مجموعة من الطرق المعروفة نتائج دون المستوى المأمول. وقد أظهرت الطرق التي تتضمن عدداً قليلاً من المتغيرات أو تستفيد من السياق الزمني أداءً أفضل نسبياً، إلا أن القيم المطلقة للنتائج تبرز ضعف القدرة على تحديد السبب في السياقات الزمنية خارج البيئات التجريبية المبسطة. ومن اللافت أن مشهد علم الروبوتات، حيث تكون بنية العلاقات أكثر كثافة، حقق نتائج أعلى نسبياً من مشهد السقوط البسيط، ما يشير إلى أن زيادة الإشارات المنظمة تساعد على تحسين الأداء، لكنها تبقى غير كافية لسد الفجوة بالكامل.
ونظراً لأن مجموعة البيانات “CausalVerse” تتيح إعادة الضبط والتكوين، فقد تمكن المؤلفون أيضاً من توضيح أهمية الافتراضات النظرية عملياً. على سبيل المثال، يتطلب مبدأ “التغيّر الكافي” نظرياً وجود عدد كافٍ من المشاهد أو البيئات المختلفة مقارنة بعدد العوامل المربِكة. وعندما أنشأ الفريق نسخة من مشهد “الأسطوانة والنابض” تستوفي هذا الشرط عبر إضافة عدد مناسب من المجالات، قفزت قيمة معامل الارتباط المتوسط بشكل ملحوظ، في تأكيد واضح على أن المشكلة ليست في الصياغة الرياضية، بل في نظام البيانات المستخدم. وعلى العكس من ذلك، فإن تشويه شروح المجالات أو اختزال المشهد إلى حالة واحدة يؤدي، كما هو متوقع، إلى تراجع القدرة على تحديد السبب، ما يبيّن مدى سهولة الوقوع في وهم تحديد الأسباب عندما لا تُستوفى الشروط المسبقة. وتُعد “CausalVerse” من مجموعات البيانات المعيارية النادرة التي تتيح تبديل الافتراضات ومراقبة تأثير ذلك على النتائج بهذه الدرجة من الوضوح.
ما الذي تكشفه النتائج
يمكن تفسير هذه النتائج بشكل متشائم مفاده أن التعلّم بالتمثيل السببي، بصيغته الحالية، يتعثر عند التعامل مع المشاهد البصرية المعقدة. لكن التفسير البنّاء الذي يشجع عليه المؤلفون يشير إلى أن الجمع بين الواقعية العالية وتوافر الحقيقة السببية المعلومة يتيح أخيراً رؤية مواضع الإخفاق وأسبابه بوضوح. وتُظهر نتائج الاختبار في حالة عدم وجود تدريب مسبق أن الطرق التي تعتمد على آليات متفرقة يمكن أن تساعد، لكنها ليست حلاً سحرياً، حيث تتطلب القدرة على تحديد السبب في السياقات الزمنية إشارات تسلسلية أقوى أو افتراضات بنيوية أوضح، كما أن الاستراتيجيات متعددة المشاهد أو القائمة على التعلم التبايني تنجح في تحديد كتلة من المتغيرات، لكنها لا تحدد المتغيرات الفردية إلا عند استيفاء الشروط النظرية.
ومع “CausalVerse”، أصبح بالإمكان اختبار الحلول المقترحة بصورة منهجية، حيث يمكن إضافة مزيد من المجالات إلى أن يصبح “التغيّر الكافي” كافياً فعلاً، أو إدخال بنى زمنية صريحة، أو توجيه المشفرات بانحيازات هندسية أو باتساق في مشاهد متعددة، أو تصميم أهداف هجينة تمزج بين القيود على مستوى الكتل والمكوّنات. وبهذا تحوِّل هذه المجموعة المعيارية الإرشادات العامة والغامضة إلى تجارب قابلة للتنفيذ والقياس.
ويحرص المؤلفون أيضاً على توضيح نطاق العمل وحدوده. فمجموعة البيانات “CausalVerse” تمثل بيئة محاكاة وليست بيانات مأخوذة مباشرة من العالم الواقعي. ورغم أن المشاهد البصرية عالية الدقة، فإن الواقع أكثر فوضوية، حيث تنحرف الحساسات، ويتصرف البشر بشكل غير متوقع، وقد تكون البنى السببية غامضة أو موضع خلاف. ومع ذلك، يشير تشن إلى أن المحاكاة، في سياق السؤال الجوهري للتعلّم بالتمثيل السببي، تتيح الحفاظ على قدر كافٍ من الواقعية دون التخلي عن إمكانية تقييم النتائج بصورة عادلة ودقيقة. ويضيف قائلاً: “بناءً على هذه المجموعة المعيارية، نخطط لتطوير قائمة مفصلة لتقييم الطرق الحالية بشكل منهجي واستكشاف التحديات العملية المحتملة والحلول الممكنة”.
أما بالنسبة للباحثين العاملين في مجال الذكاء الاصطناعي المتجسّد أو الروبوتات أو أنظمة الإدراك ذات الحساسية العالية للسلامة، فإن قيمة هذا العمل واضحة. فالنماذج التي تفهم المشهد على أساس العلاقات فقط ستفشل عند حدوث تدخلات مثل تغيير الإضاءة، أو اعتماد سياسة تحكم مختلفة للروبوت، أو دفعة تغير حركة جسم ما. أما الطرق التي تستوعب الآليات السببية فتكون أقدر على التعميم في مواجهة تلك التغيرات ودعم التخطيط القائم على السؤال: ماذا سيحدث إذا فعلت هذا؟ وتوفر مجموعة البيانات “CausalVerse” أداة عملية للتمييز بين الحالتين، وللتكرار والتحسين إلى أن يصبح الجواب قائماً على أسس أقوى من الأماني فقط.
- المؤتمرات ,
- neurips ,
- السببية ,
- البحوث ,
- المتغيرات ,
- الأساس المعياري ,
- التعلم بالتمثيل السببي ,
أخبار ذات صلة

باحثو الذكاء الاصطناعي في أبوظبي يعيدون صياغة قواعد الطب في مختلف مراحل الحياة
On World Health Day, MBZUAI showcases how artificial intelligence is transforming healthcare, from predicting Alzheimer’s years in.....
- World Health Day ,
- health ,
- healthcare ,
- AI ,

كيف يمكن للتعلم المعزز أن يساعد أنظمة الذكاء الاصطناعي الطبي على التفكير مثل الطبيب
MBZUAI researchers received an NVIDIA Academic Grant for MediX-R1 – a framework that fine-tunes multimodal language models.....
- التعلم المعزز ,
- منحة ,
- الاستدلال ,
- طبي ,
- الرعاية الصحية ,
- التعلّم التعزيزي ,

أخبار الخريجين: كيف تعلّم عبد الرحمن شاكر إعادة تعريف الأثر في الذكاء الاصطناعي
يوضح خريج جامعة محمد بن زايد للذكاء الاصطناعي كيف تحوّل تركيزه من النشر العلمي إلى إحداث أثر.....
- الخريجون ,
- أخبار الخريجين ,
- الدكتوراه ,
- التأثير ,
- البحث ,
- ما بعد الدكتوراه ,