
معيار جديد لاختبار قدرة النماذج اللغوية الكبيرة على الاستدلال
الخميس، 20 مارس 2025

لطالما كانت القدرة على استخدام اللغة ميزة ينفرد بها البشر وحدهم، إلى أن ظهرت النماذج اللغوية الكبيرة لتجاريهم في ذلك. واليوم، يعمل العلماء على توسيع قدرات الذكاء الاصطناعي بما يتجاوز القدرات اللغوية عبر تطوير أنظمة متخصصة تُعرف بنماذج الاستدلال صُمّمت لحل مسائل معقّدة. ومثلما غيّرت النماذج اللغوية الكبيرة نظرتنا للعلاقة بين البشر والآلات في استخدام اللغة، تسعى هذه النماذج الجديدة لمحاكاة قدرة أخرى طالما اعتُبرت ميزة بشرية خالصة، وهي القدرة على الاستدلال.
تهدف نماذج الاستدلال بشكل أساسي إلى حل المسائل بدلاً من مجرد التنبؤ بالإجابات، مستخدمة في ذلك عدة طرق، منها سلسلة الأفكار، حيث يتم تفكيك السؤال المعقّد إلى أجزاء صغيرة يسهل التعامل معها، والتقييم الذاتي، الذي يتيح للنموذج تقييم جودة مخرجاته.
للوصول إلى فهم أفضل لقدرة النماذج اللغوية الكبيرة على الاستدلال، أنشأ باحثون من جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى مجموعة بيانات معيارية جديدة تستخدم ألعاباً نصيّة بسيطة لاختبار تلك القدرات. وأطلق الباحثون على هذه المجموعة اسم “TextGames“، وهي تتطلب مهارات مثل التعرّف على الأنماط، والوعي المكاني، والحسابات الرياضية، والتفكير المنطقي. ورغم أن الألعاب المدرجة في هذه المجموعة ليست صعبة بالنسبة للبشر، فقد شكّلت تحدياً حقيقياً للنماذج اللغوية الكبيرة.
يقول الدكتور ألهم فكري آجي، الأستاذ المساعد في قسم معالجة اللغات الطبيعية في جامعة محمد بن زايد للذكاء الاصطناعي وأحد المؤلفين المشاركين في إعداد الدراسة إن معظم النماذج التي جرى اختبارها باستخدام مجموعة “TextGames” لم تتمكن من حلّ أصعب الأسئلة، مضيفاً: “هذه النتيجة مثيرة للاهتمام، خاصة في ضوء أبحاث حديثة تشير إلى أن النماذج اللغوية الكبيرة تُظهر مستوى من الذكاء يضاهي ذكاء البشر”.
شارك في إعداد الدراسة كل من فريدريجوس هودي، وجينتا إندرا ويناتا، وروشن زانغ. وقد ساهموا جميعاً في البحث بشكل متساوٍ.
ما هو الاستدلال؟
من الصعب وضع تعريف واحد الاستدلال، حيث استخدمه باحثو الذكاء الاصطناعي بطرق مختلفة. وبحسب الدكتور آجي وزملائه فإن الاستدلال هو “قدرة متعددة الأوجه تشمل فهم السياق، واستكشاف الحلول المحتملة واختبارها بفعالية ضمن القيود المفروضة، من أجل حل المسائل”.
في السابق، كان الباحثون في مجال الذكاء الاصطناعي يختبرون قدرة النماذج على الاستدلال من خلال جعلها تجيب على أسئلة اختبارات تشبه أسئلة الامتحانات في المرحلة الثانوية. لكن هذه الطريقة تواجه قيوداً من أبرزها احتمال أن تكون النماذج تدربت على أسئلة وإجابات مشابهة، حيث يُعتقد أن العديد من النماذج تدربت على معظم البيانات المتاحة للعموم على الإنترنت، وفي هذه الحالة قد تتمكن النماذج من إعطاء إجابات صحيحة دون أن تستدل عليها فعلياً، وإنما بمجرد استدعاء المعلومات من ذاكرتها.
تكمن أهمية الاستدلال في أنه يتطلب القدرة على التعميم والتعامل مع مواقف جديدة، بدلاً من الاعتماد على الحفظ فقط. ومن هذا المنطلق، عمل آجي وزملاؤه على إنشاء عدد كبير من سيناريوهات الألعاب الجديدة والمتنوعة ضمن مجموعة بيانات “TextGames”، وهي سيناريوهات لم يسبق للنماذج التعامل معها. يوضح آجي النهج الذي اتبعه فريقه قائلاً: “استطعنا توزيع سيناريوهات الألعاب في مجموعتنا بشكل عشوائي، وإنشاء سيناريوهات ألعاب جديدة كلياً”.
تفاصيل مجموعة البيانات
تتكوّن مجموعة البيانات “TextGames” من ثماني ألعاب ألغاز موزّعة على ثلاثة مستويات من الصعوبة. وهي تشمل لعبة كلمات المرور، التي يُطلب فيها من اللاعب إنشاء كلمات مرور تستوفي معايير معيّنة، مثل استخدام حروف كبيرة وصغيرة وأرقام ورموز خاصة. كما تتضمّن لعبة تُدعى “Anagram Scribble”، يُطلب فيها من اللاعب ترتيب مجموعة من الحروف اللاتينية لتشكيل كلمة إنجليزية تحتوي على عدد محدد من الحروف. وهناك أيضاً لعبة سودوكو، يُطلب فيها من اللاعب ملء الفراغات بأرقام بحيث لا تتكرر الأرقام ضمن الصف أو العمود أو المربع في الشبكة. وتتنوع طبيعة هذه الألعاب، فبعضها تتضمن بعداً واحداً، مثل لعبة كلمات المرور، وبعضها الآخر يتضمن بُعدين اثنين، مثل لعبة السودوكو.
أنشأ آجي وفريقه 24 ألف عينة اختبار، وأعدّوا عدداً قليلاً من العينات لأغراض التدريب. ونظراً إلى أن هدفهم كان اختبار أداء النماذج في حالة عدم وجود تدريب مسبق وفي حالة وجود تدريب مسبق محدود، فلم تكن هناك حاجة لتخصيص جزء للتدريب ضمن مجموعة البيانات.
أراد الباحثون معرفة ما إذا كان بإمكان النماذج اللغوية الكبيرة تحسين أدائها باستخدام آليات مثل التقييم الذاتي، وكذلك التأمل الذاتي، وهي قدرة النموذج على تحليل الخطوات التي يتبعها عند اتخاذ القرار. أثناء الاختبار، سُمِح للنماذج بثلاث محاولات للإجابة عن كل سؤال، ثم جرى تقييم الإجابات باستخدام نظام يُعرف باسم المُقيّم (grader) للتحقق من صحتها.
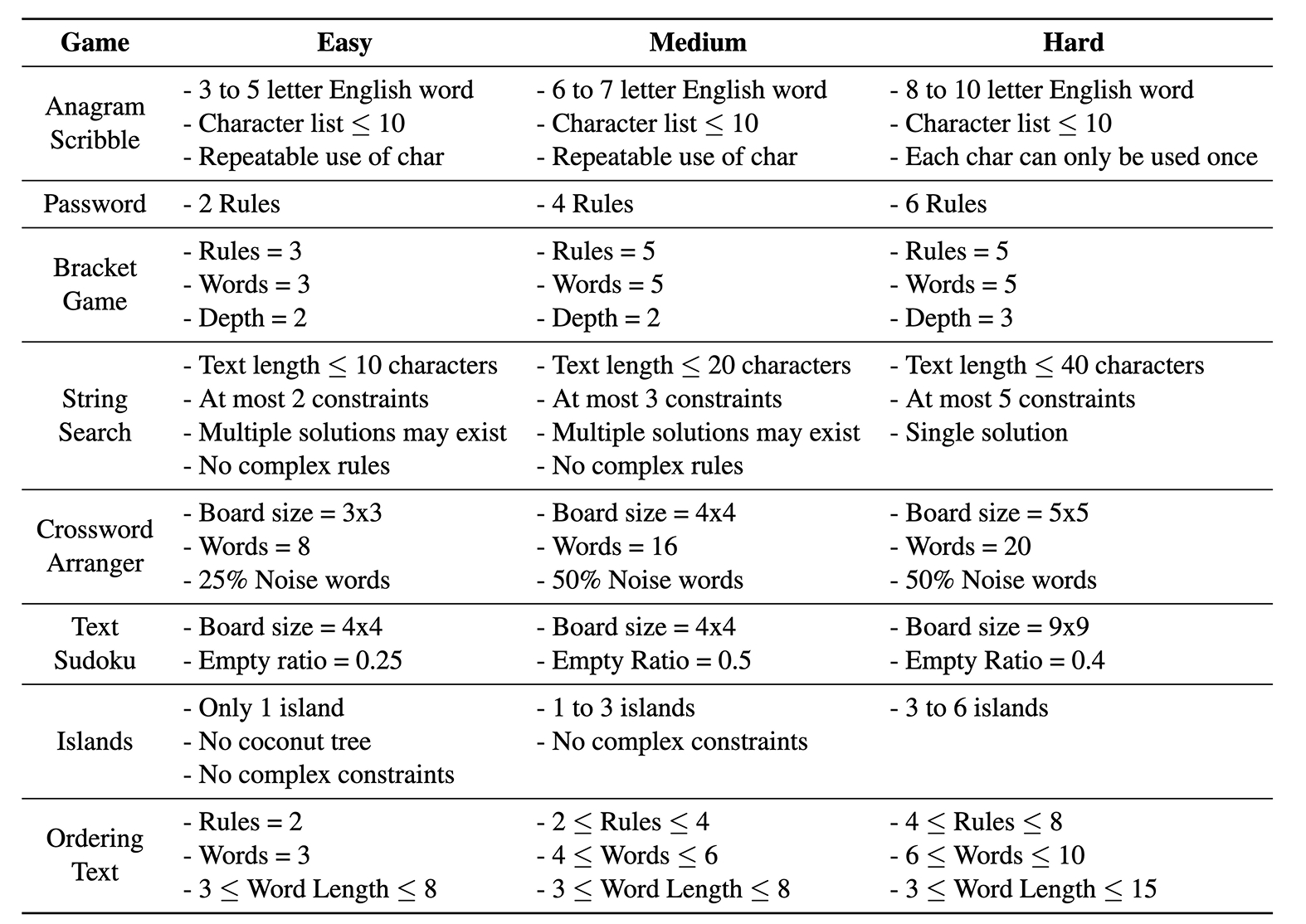
تتكون مجموعة البيانات “TextGames” من 24 ألف سؤال اختبار موزعة على ثماني ألعاب وثلاثة مستويات من الصعوبة.
النماذج والنتائج
أجرى آجي وزملاؤه مقارنة بين النماذج المصممة لتنفيذ التعليمات، مثل “Llama” من شركة “ميتا” و”Qwen” من شركة “علي بابا”، وبين نماذج مصممة خصيصاً للاستدلال، مثل “GPT-4o Mini” و”GPT-o3 Mini” من شركة “أوبن أيه آي”.
واجهت معظم النماذج صعوبة في حل الأسئلة، حتى السهلة منها. وكان النموذج “GPT-o3 Mini” أكثرها دقة، لكنه حقق نتائج عالية فقط في مجموعة محددة من الألعاب. أما نماذج تنفيذ التعليمات، فقد تمكّنت من الإجابة بشكل صحيح عن بعض الأسئلة السهلة والمتوسطة، لكنها عجزت عن التوصل إلى الإجابات الصحيحة في الأسئلة الصعبة. وتبيّن أن الألغاز ثنائية الأبعاد كانت أصعب بكثير من الألغاز ذات البعد الواحد.
على سبيل المثال، في الأسئلة السهلة ثنائية الأبعاد، عجزت جميع النماذج (باستثناء “GPT-o3”) عن تحقيق نسبة أعلى من 50% في دقة الإجابات حتى بعد ثلاث محاولات. أما في الأسئلة المتوسطة ثنائية الأبعاد، فلم تتجاوز نسبة دقة الإجابات 20% بعد ثلاث محاولات. ولم يتمكن أي نموذج، باستثناء “GPT-o3 Mini”، من تجاوز نسبة 4% في دقة الإجابات في الألغاز ثنائية الأبعاد، حتى بعد ثلاث محاولات.
من ناحية أخرى، تمكّن النموذج “GPT-o3 Mini” من الإجابة بشكل صحيح عن 78% من الأسئلة الصعبة ذات البعد الواحد بعد ثلاث محاولات، وعن 48.6% من الأسئلة الصعبة ثنائية الأبعاد بعد ثلاث محاولات أيضاً.
وبشكل عام، كان أداء النماذج الأكبر أفضل من أداء النماذج الأصغر، لكن حجم النموذج لم يُحدث فرقاً كبيراً في المهام الأكثر تعقيداً، كالتي تتطلب الاستدلال في بُعدين اثنين. وقد تحسّن أداء النماذج مع زيادة عدد المحاولات، وهو أمر متوقع.
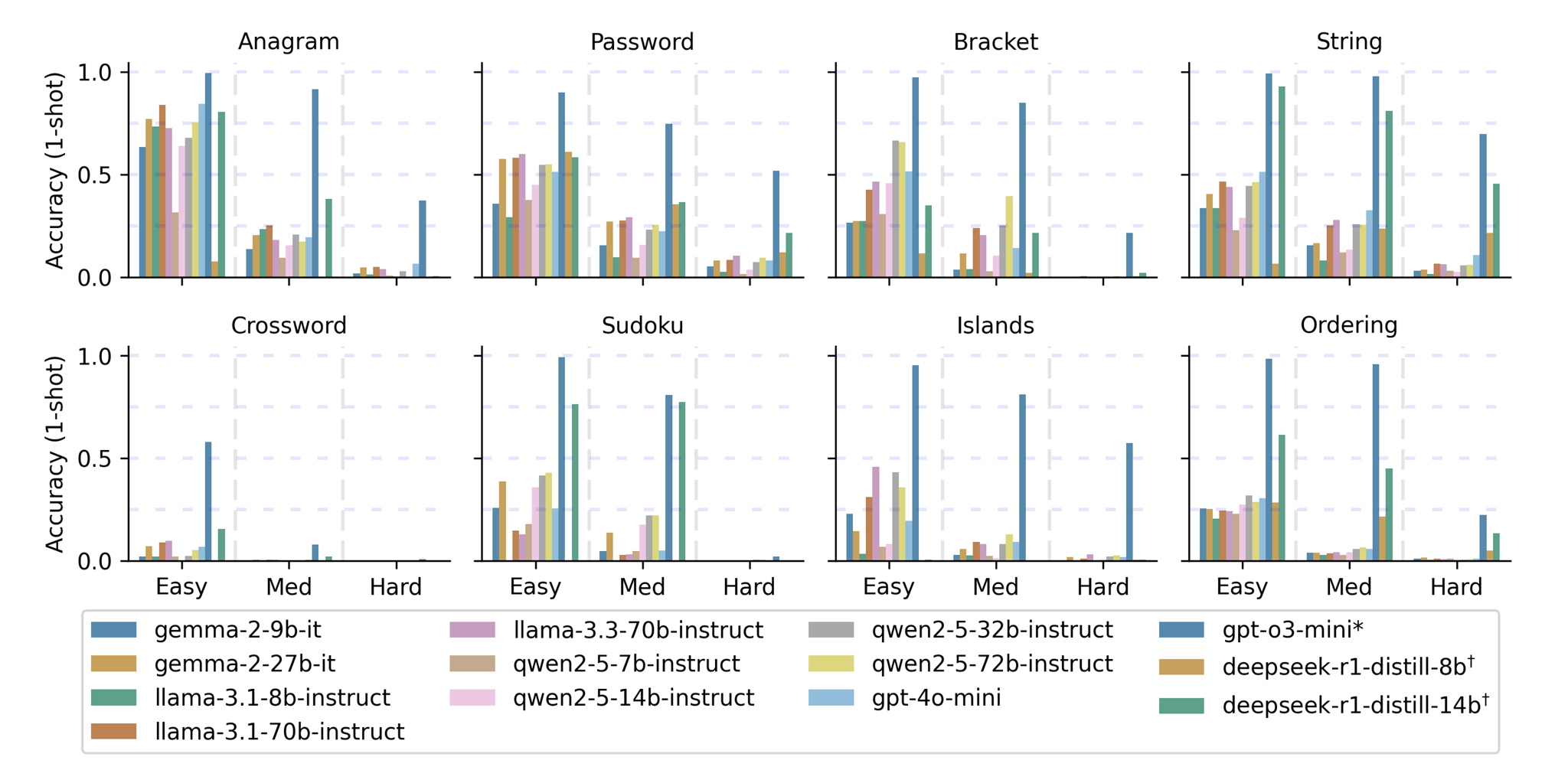
حقق النموذج “GPT-o3 Mini” من “أوبن أيه آي”، وهو نموذج مخصص للاستدلال، أفضل أداءً على مجموعة البيانات “TextGames”. ويُظهر الشكل أعلاه أداء كل نموذج في محاولة واحدة في الألعاب الثماني ومستويات الصعوبة الثلاثة.
التفكير المطوّل ليس أفضل دائماً
من المعتقد بشكل عام أن أداء النموذج يتحسّن كلما استغرق وقتاً أطول في عملية الاستدلال. لكن آجي وزملاءه وجدوا أن زيادة وقت الاستدلال في “TextGames” لم تؤدِّ إلى إجابات أفضل، خصوصاً في الأسئلة الأكثر صعوبة، بل نتج عنها تراجع في الأداء. كما لاحظ الباحثون أن زيادة وقت الاستدلال لم تقترن بتحسن في أداء أفضل نموذج في الدراسة، وهو “GPT-o3 Mini”.
يشير آجي وزملاؤه في دراستهم إلى أن “إطالة عملية الاستدلال قد تؤدي إلى إرباك النموذج وجعله يقدم حلولاً معقّدة أكثر من اللازم أو يفهم السؤال بشكل خاطئ”. وبما أن “GPT-o3 Mini” نموذج مغلق المصدر، لم يكن بمقدور الفريق الاطلاع على آلية استدلاله الداخلية. لكن عند اختبارهم نموذجاً آخر مفتوح المصدر، وهو “R1” من شركة “ديب سيك”، لاحظوا أنه في بعض الحالات كان يعطي إجابة صحيحة في المحاولة الأولى، لكنه يميل إلى الإفراط في التفكير ثم يغيّر الإجابة الصحيحة إلى إجابة خاطئة.
ويؤكد آجي على ضرورة أخذ التكلفة في الحسبان عند إطالة وقت الاستدلال لأنه “كلما زاد وقت الاستدلال، زادت التكلفة”.
الإنسان في مواجهة الآلة
أجرى آجي وفريقه مقارنة بين أداء النماذج اللغوية الكبيرة وأداء البشر. وأنشأوا لهذا الغرض تطبيقاً إلكترونياً يُتيح لمستخدمين من البشر حلّ نفس المسائل الموجودة في مجموعة البيانات، مع تسجيل الزمن المستغرق ونسبة الإجابات الصحيحة.
على الرغم من أن البشر ميّالون إلى التسرع في إعطاء إجابات خاطئة، فقد تمكنوا بشكل عام من حل جميع الأسئلة بشكل صحيح، بما في ذلك أصعبها، عند إعطائهم ما يكفي من الوقت وعدد المحاولات. أما معظم النماذج، فقد عجزت تماماً عن حل أي من الأسئلة الصعبة.
هذا التباين في الأداء دفع آجي إلى النظر في مكمن الاختلاف بين الاستدلال عند البشر والاستدلال عند الآلات. وهو يوضح ذلك بقوله: “نحن البشر نفكر في احتمالات كثيرة، ويمكننا تخيّل سيناريوهات متعددة واختيار المسار الذي يقودنا إلى الحل. أما النماذج اللغوية الكبيرة، فلا يمكنها فعل ذلك بالطريقة نفسها، لأنها مضطرة لإنتاج النص خطوة بخطوة، ولا يمكنها التخطيط المسبق كما يفعل البشر”.
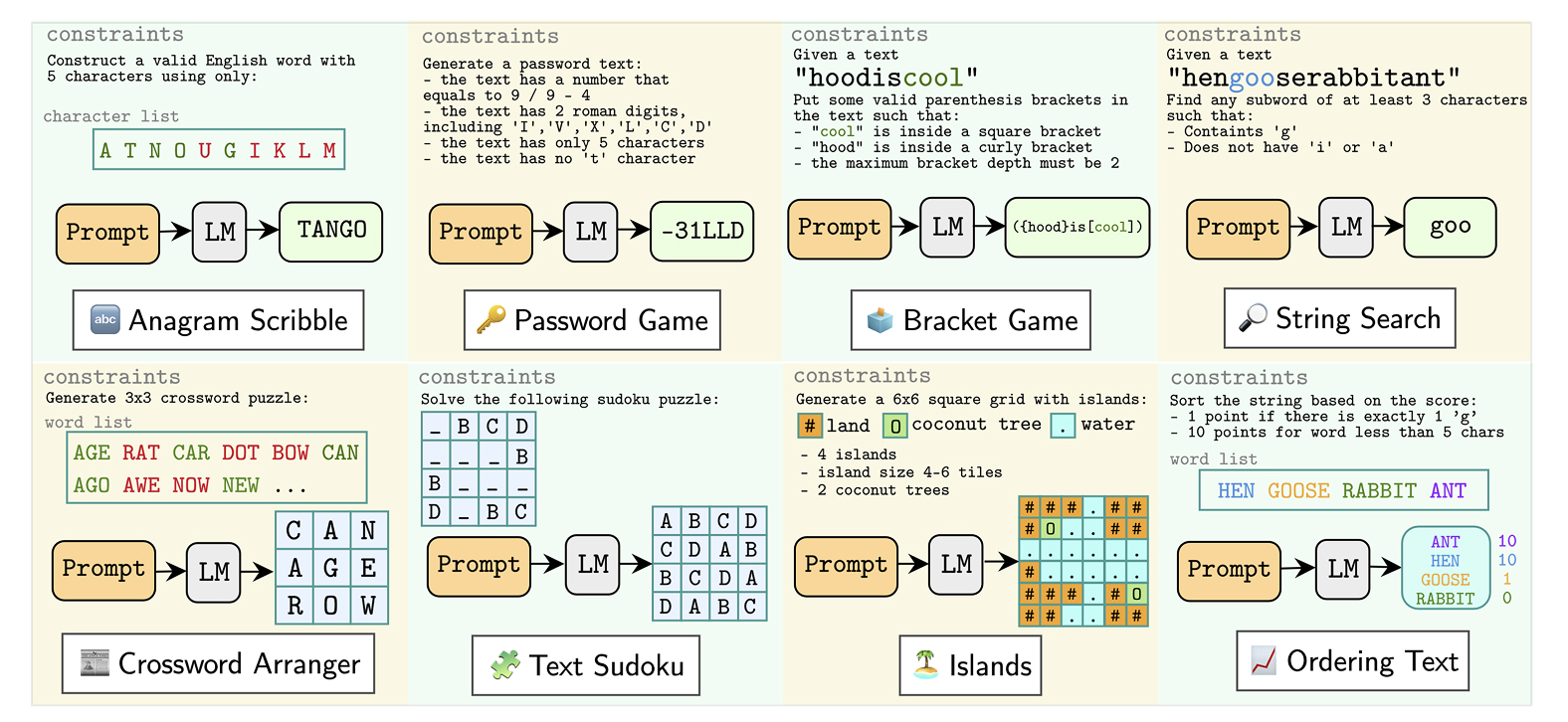
تتضمن مجموعة البيانات “TextGames” ثماني ألعاب تتطلب مهارات مثل التعرّف على الأنماط، والوعي المكاني، والحسابات الرياضية، والتفكير المنطقي.
آفاق مستقبلية
تُظهر نتائج الدراسة مجالات محددة يمكن فيها تحسين قدرات النماذج اللغوية الكبيرة على الاستدلال. فقد تُستخدم هذه النماذج مستقبلاً لتوفير قدرات استدلال داخل الروبوتات الذكية لمساعدتها على التخطيط وتنفيذ الأوامر. وهنا يقول آجي: “نريد أن نعرف ما إذا كان بإمكاننا الوثوق بهذه النماذج في أداء مهام تتطلب القدرة على الاستدلال”.
ويتساءل آجي عما إذا كان استخدام النماذج اللغوية الكبيرة للاستدلال هو النهج الأفضل في ضوء تقييد قدراتها نتيجة لحاجتها لإنتاج النصوص كوسيلة للاستدلال، مشيراً إلى أن مجال الذكاء الاصطناعي شهد منذ زمن طويل تطوير برامج متخصصة في ألعاب تتطلب القدرة على الاستدلال استطاعت التفوق على أفضل اللاعبين من البشر. فقد تمكّن العلماء من تطوير برامج تغلبت على أبطال العالم في ألعاب مثل الشطرنج ولعبة “غو”، وبالتالي لا يوجد ما يمنع إنشاء برامج متخصصة تحل ألعاباً مثل سودوكو بنفس الكفاءة.
ويختتم آجي كلامه بالتأكيد على أن النماذج اللغوية الكبيرة ستؤدي دوراً مهماً في مجال علوم الروبوتات المتقدمة، ولكنها مع ذلك قد لا تكون الوسيلة الوحيدة لتزويد الروبوتات بالقدرة على الاستدلال، موضحاً ذلك بقوله: “بدلاً من إجبار نموذج لغوي كبير على حل مسائل الاستدلال، يمكننا تخيّل طريقة بديلة يستعين فيها هذا النموذج بأنظمة خارجية مصممة للقيام بأشكال محددة من الاستدلال ومهام أخرى. ربما يكون هذا الحل الأمثل في المستقبل”.
- النماذج اللغوية الكبيرة ,
- الأبحاث ,
- مجموعة البيانات ,
- الذكاء ,
- المنطق ,
- التفكير ,
- معيار ,
أخبار ذات صلة

جامعة محمد بن زايد للذكاء الاصطناعي تصدر تقريرها حول الذكاء الاصطناعي للجنوب العالمي في الهند
يحدّد التقرير 12 سؤالاً بحثياً جوهرياً الهدف منها توجيه جهود العشرية القادم البحثية في اتجاه تطوير ذكاء.....
- قمة ,
- الشمولية ,
- AI4GS ,
- الجنوب العالمي ,
- تقرير ,
- التأثير الاجتماعي ,
- عادل ,

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- natural language processing ,
- غوغل ,
- التمويل ,
- funding ,
- Arabic ,
- nlp ,
- النماذج اللغوية الكبيرة ,
- Google ,
- llms ,
- اللغة العربية ,
- معالجة اللغة الطبيعية ,

تحسين فهم النماذج اللغوية للثقافة العربية عبر تبادل المعرفة بين الثقافات
تكشف أبحاث جديدة من جامعة محمد بن زايد للذكاء الاصطناعي كيف يمكن لعدد محدود من الأمثلة الموجّهة.....
- معالجة اللغات الطبيعية ,
- EMNLP ,
- اللغة العربية ,
- الثقافة ,
- الثقافة العربية ,
- nlp ,