
بناء نموذج ذكاء اصطناعي يتحدث الهندية
الخميس، 26 مارس 2026
على الرغم من الحديث المتزايد عن عالمية الذكاء الاصطناعي، لا تزال النماذج اللغوية الكبيرة تميل إلى رؤية العالم من خلال اللغة والثقافة الإنجليزية. فهي قد تدعم عشرات اللغات، لكن الدعم لا يعني الطلاقة، والطلاقة لا تعني بالضرورة الملاءمة الثقافية. وتقدّم ورقة بحثية جديدة من جامعة محمد بن زايد للذكاء الاصطناعي، قُبلت في فعاليات المؤتمر 19 للفرع الأوروبي لجمعية اللغويات الحاسوبية (EACL 2026) ، نموذجين ثنائيي اللغة بأوزان مفتوحة صُمّما خصيصاً للهندية والإنجليزية. وتتمثل الخلاصة الرئيسة في أن تحسين الذكاء الاصطناعي متعدد اللغات لا يتحقق بمجرد إضافة المزيد من البيانات، بل من خلال اتخاذ قرارات مدروسة تتعلق باللغة، والكتابة، والثقافة، والسلامة.
يحمل النموذجان اسمي Nanda-10B وNanda-87B، وقد طُوّرا في معهد النماذج التأسيسية في الجامعة بالتعاون مع G42 وسيريبرا. قد يبدو النموذجان كأنهما مجرد نسخة مُحسّنة من عائلة Llama ذات الأوزان المفتوحة من “ميتا” لكن التعمق في تفاصيل البناء يكشف جوانب مهمة في منهجية الفريق. إذ تشير الورقة إلى أن اللغة الهندية لم تحظَ بالخدمة الكافية، ليس فقط بسبب قلة البيانات مقارنة بالإنجليزية، بل لأن البيانات والأدوات المتاحة لها غالباً لا تعكس كيفية استخدام اللغة فعلياً.
فاللغة الهندية لا تظهر في شكل نصي واحد؛ فهي تُكتب رسمياً بخط الديفناغاري، وتظهر بصيغة لاتينية على الإنترنت، كما تُستخدم بشكل هجين مع الإنجليزية في المحادثات ووسائل التواصل الاجتماعي والحياة الرقمية اليومية. وأي نموذج يتعلم أحد هذه الأشكال فقط، لن يفهم سوى جزء من البيئة اللغوية التي يفترض أن يخدمها.
استجابةً لهذا التحدي، اتبع الباحثون ثلاث خطوات رئيسة. أولاً، قاموا ببناء محلل وحدات نصية (Tokenizer) يوسّع مفردات نموذج Llama الأصلية بإضافة وحدات خاصة باللغة الهندية. وعملياً، يتيح ذلك للنموذج تقسيم النصوص الهندية إلى وحدات طبيعية بصورة أكبر بدلاً من تجزئتها بشكل غير فعّال. وتشير الورقة إلى أن هذا النهج خفّض معدل تجزئة النصوص الهندية إلى النصف تقريباً، مع الحفاظ على كفاءة الإنجليزية، وهو مؤشر تقني واضح على أن النموذج صُمم فعلاً للاستخدام ثنائي اللغة، وليس مجرد تعريضه لمزيد من النصوص الهندية.
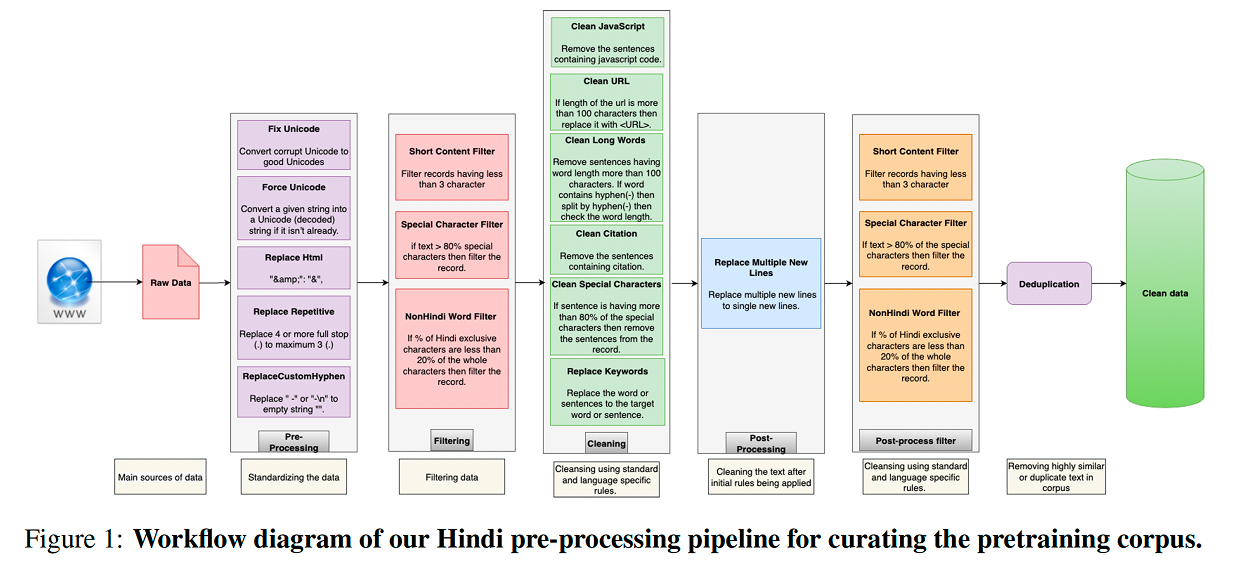
ثانياً، أجرى الفريق تدريباً مسبقاً مستمراً يركز على الهندية أولاً، باستخدام مجموعة بيانات تضم 65 مليار وحدة نصية، صُممت لتمثيل أشكال متعددة من اللغة، بما في ذلك الديفناغاري، والهندية المكتوبة بالحروف اللاتينية، والنصوص المختلطة بين الهندية والإنجليزية.

ثالثاً، جرى مواءمة النموذجين باستخدام بيانات تعليمات ثنائية اللغة، إلى جانب مجموعة بيانات كبيرة للسلامة مبنية على سياق ثقافي. وتُعد هذه الخطوة الأخيرة ذات أهمية خاصة، إذ يمكن تحسين قدرات النماذج في لغة جديدة، لكن تدريبها على الاستجابة بشكل آمن ومناسب ثقافياً يظل أقل شيوعاً.
وبحسب الورقة، يتفوق نموذج Nanda-87B على نماذج أخرى مماثلة ذات أوزان مفتوحة في مهام التلخيص، والترجمة، والتحويل بين أنظمة الكتابة واتباع التعليمات. أما النموذج الأصغر Nanda-10B، فيُظهر أداءً متبايناً بشكل عام، لكنه يظل منافساً قوياً، ويبرز بشكل خاص مقارنة بالنماذج التي تقل عن 10 مليارات معلمة في مجالات مثل السلامة والمعرفة الثقافية. وفي تقييمات توليدية ثنائية باستخدام GPT-4o كمحكّم، أظهر النموذجان تفوقاً واضحاً في اللغة الهندية مقارنة بنماذج Llama المُحسّنة بالتعليمات.
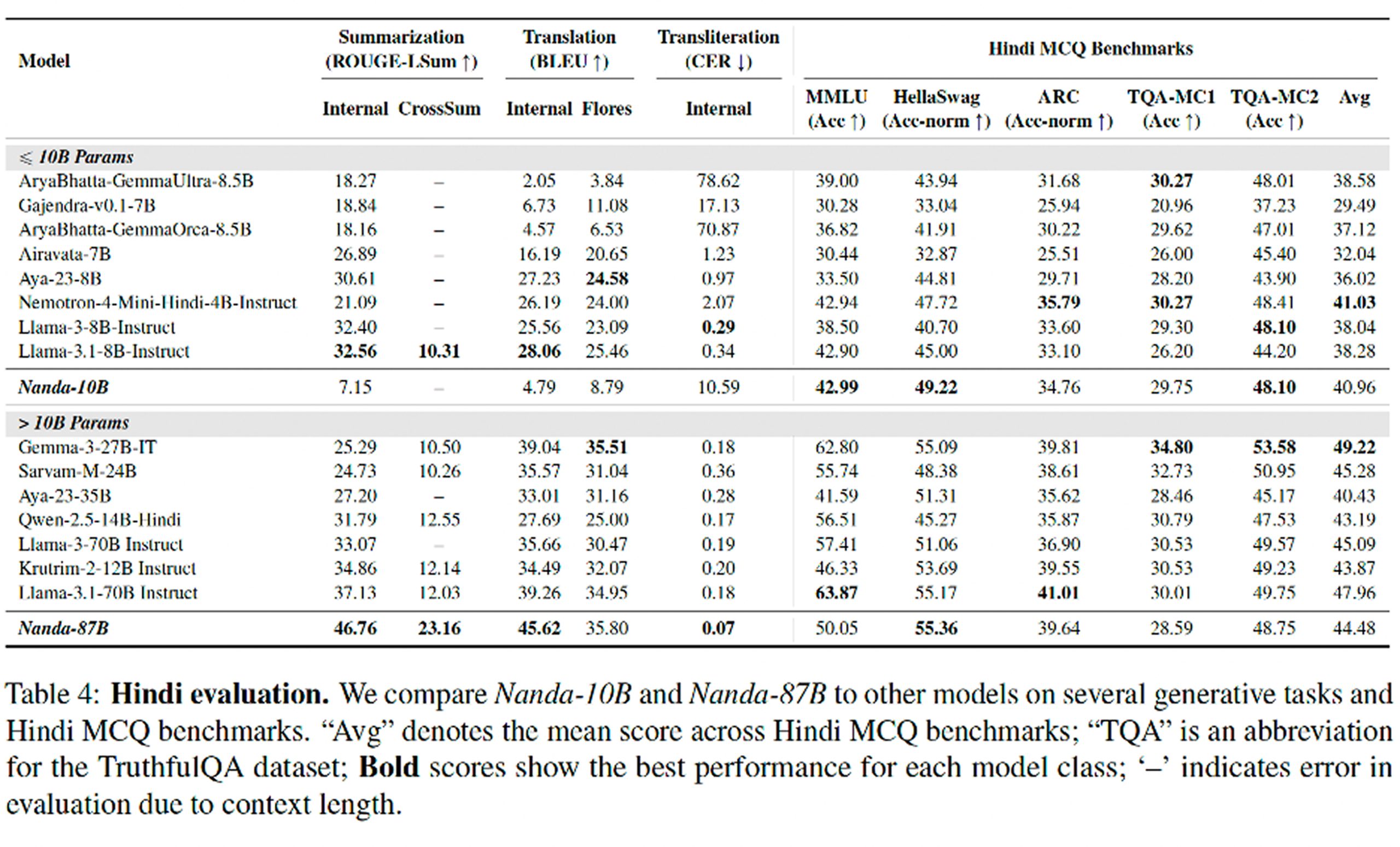
وتسلط الورقة الضوء أيضاً على الفرق بين الأداء التوليدي والأداء في الاختبارات القياسية. ففي اختبارات الاختيار من متعدد، كانت نماذج Nanda منافسة، لكن الفارق لم يكن دائماً كبيراً. ويرجع ذلك إلى أن هذه الاختبارات لا تعكس سوى جزء من قدرة النموذج اللغوية. أما إذا كان الهدف هو بناء نظام قادر على التلخيص، والترجمة، وفهم المدخلات المختلطة، والاستجابة ضمن سياق ثقافي مناسب، فإن التقييم التوليدي يصبح أكثر أهمية من ترتيب النموذج في لوحات الصدارة.
كما تُقدم الورقة طرحاً مهماً حول ترابط اللغة والثقافة متضمنة تقييماً ثقافياً مخصصاً باستخدام معايير تركز على اللغة الهندية في مجالات مثل الطب التقليدي، والتمويل، والزراعة، والمسائل القانونية. وفي هذه الجوانب أيضاً، تصدرت نماذج Nanda فئاتها من حيث الحجم. ولا يعني ذلك امتلاكها للثقافة بالمعنى الإنساني العميق، لكنه يشير إلى أن تكييف اللغة بشكل صحيح يمكن أن يحسن من قدرة النموذج على التعامل مع المعرفة السياقية التي يعتمد عليها الناس في حياتهم اليومية.
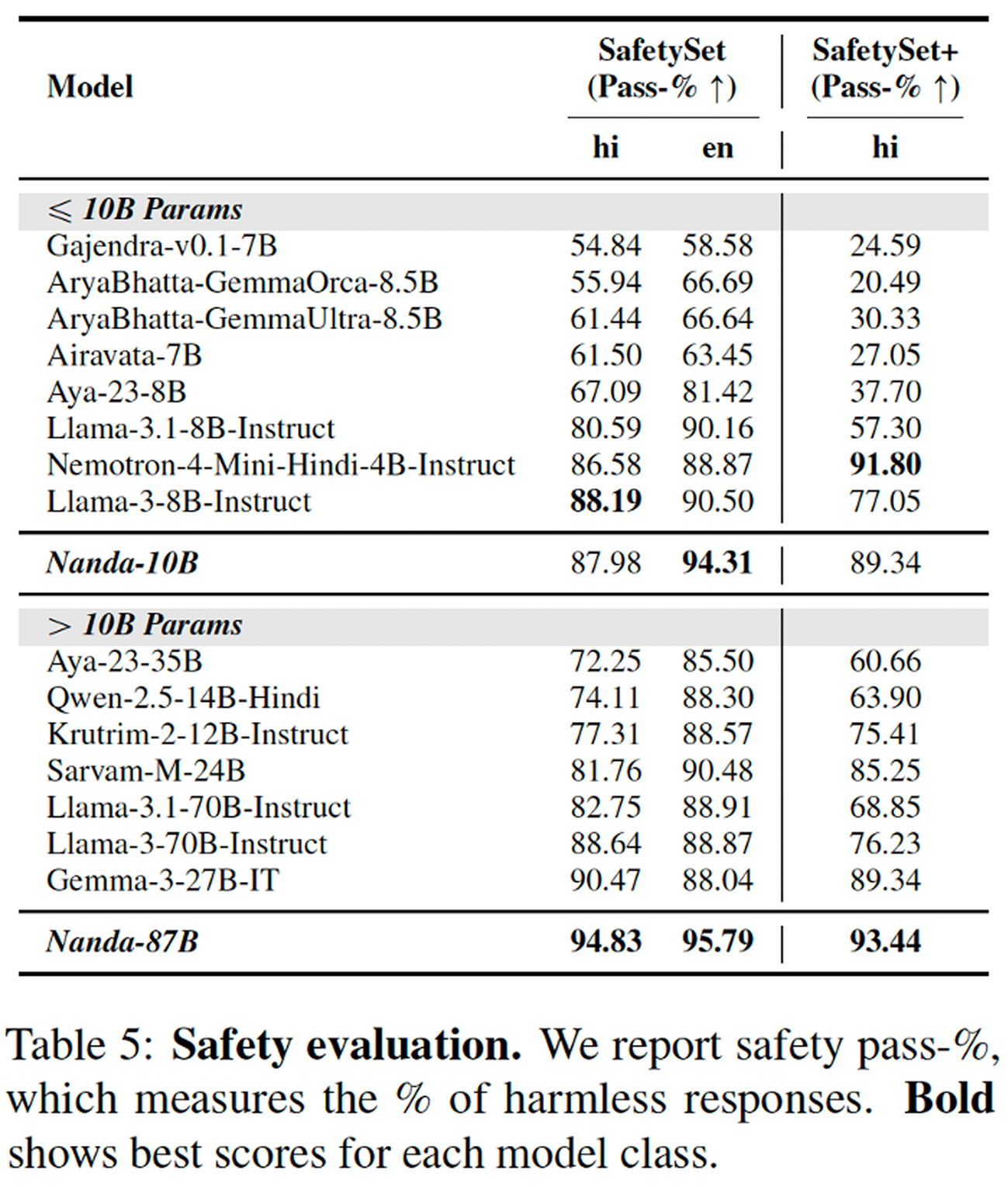
وتشكل السلامة جانباً بارزاً آخر في هذا العمل. إذ تشير الورقة إلى أن كلا النموذجين حقق نتائج متقدمة على تقييمات السلامة باللغة الهندية، بما في ذلك مجموعة من المدخلات الحساسة ثقافياً صُممت يدوياً بواسطة متحدثين أصليين. وتكمن أهمية ذلك في أن العمل على اللغات منخفضة الموارد في مجال الذكاء الاصطناعي يركز غالباً على الكفاءة أولاً، ثم على المواءمة لاحقاً، بينما توضح هذه الدراسة أن الاثنين يجب أن يُبنيا معاً منذ البداية.
تقليدياً، كان النهج المتبع لدعم اللغات الأقل تمثيلاً يبدأ بنموذج متمركز حول الإنجليزية، ثم تُسد الفجوات عبر الترجمة أو الضبط بالتعليمات أو التوسّع متعدد اللغات بشكل محدود. وتشير نتائج Nanda إلى أن هذا النهج غير كافٍ. فإذا كانت اللغة تختلف في أنظمة الكتابة، وأنماط الاستخدام اليومية، والأطر الثقافية، فيجب أن تنعكس هذه الاختلافات في تصميم المحلل النصي، ومزيج التدريب، وبيانات التعليمات، وآليات السلامة منذ البداية.
وتقر الورقة بوجود تحديات قائمة، لا سيما محدودية توفر مجموعات بيانات هندية أصيلة واسعة النطاق، إضافة إلى اعتماد بعض التقييمات على مقاييس آلية قد تغفل الفروق الدقيقة في الملاءمة أو السياق الثقافي.
ومع ذلك، تظل الرسالة الأساسية للدراسة واضحة: بناء نماذج أفضل للغات الأقل تمثيلاً ليس مسألة إنصاف فحسب، ولا يقتصر على الترجمة، بل هو تحدٍ تقني وبياني وثقافي في آن واحد. وتعاملت عائلة Nanda مع اللغة الهندية من هذا المنظور الشامل. وفي مجال لا يزال يخلط أحياناً بين تعدد اللغات وفهمها الحقيقي، يمثل هذا العمل خطوة مهمة إلى الأمام.
- معالجة اللغات الطبيعية ,
- nlp ,
- اللغة ,
- الثقافة ,
- IFM ,
- معهد النماذج التأسيسية ,
- Nanda ,
- الهندية ,
أخبار ذات صلة

جائزة "غوغل للأبحاث الأكاديمية" تكرّم مشروعاً بحثياً عن تطوير نموذج لفهم أنماط التعبير عن الشعور بالوحدة في السياقات الرقمية
دراسة بحثية جديدة، بإشراف كلٍّ من البروفيسور ثامار سولوريو والبروفيسور مونوجيت تشودري، وبمشاركة الباحث ما بعد الدكتوراه.....
- البحوث ,
- nlp ,
- معالجة اللغة الطبيعية ,
- جائزة ,
- غوغل ,
- جائزة غوغل للأبحاث الأكاديمية ,
- العزلة ,
- الصحة النفسية ,

جامعة محمد بن زايد للذكاء الاصطناعي تصدر تقريرها حول الذكاء الاصطناعي للجنوب العالمي في الهند
يحدّد التقرير 12 سؤالاً بحثياً جوهرياً الهدف منها توجيه جهود العشرية القادم البحثية في اتجاه تطوير ذكاء.....
- الشمولية ,
- AI4GS ,
- الجنوب العالمي ,
- تقرير ,
- التأثير الاجتماعي ,
- عادل ,
- قمة ,

مبادرة بحثية في جامعة محمد بن زايد للذكاء الاصطناعي تحصل على تمويل بقيمة مليون دولار أمريكي من مؤسسة غوغل
مؤسسة غوغل توفر دعماً بقيمة مليون دولار أمريكي للبروفيسورة ثامار سولوريو لقيادة مبادرة بحثية تحويلية هدفها تطوير.....
- Google ,
- natural language processing ,
- nlp ,
- النماذج اللغوية الكبيرة ,
- llms ,
- معالجة اللغة الطبيعية ,
- اللغة العربية ,
- Arabic ,
- funding ,
- التمويل ,
- غوغل ,