
اختبار جديد لأنظمة الذكاء الاصطناعي المساعدة القادرة على التخطيط والملاحظة والتنفيذ
الاثنين، 25 أغسطس 2025

حصد فريق من باحثي جامعة محمد بن زايد للذكاء الاصطناعي جائزة المركز الثاني في مسابقة “AgentX” التي استضافتها جامعة كاليفورنيا في بيركلي، وذلك عن مجموعة بيانات معيارية جديدة تقيس قدرة أنظمة الذكاء الاصطناعي المساعدة على التفكير والتعامل مع الصور، والمقارنة بين عدة صور، ومقاطع الفيديو، مع الاستعانة بأدوات خارجية عند الحاجة.
وقد قُدّمت الجائزة في قمة أنظمة الذكاء الاصطناعي المساعدة التي عُقدت في بيركلي في شهر أغسطس تقديراً للجهود التي بذلها الفريق لإظهار أن أفضل الأنظمة المساعدة المتعددة الوسائط اليوم، أي الأنظمة التي تقرأ وتشاهد وتتصفح وتستعين بالأدوات، ما زالت غير قادرة على التعامل مع المهام في العالم الواقعي الذي يعج بالفوضى.
جاءت مشاركة الفريق في المسابقة في فئة “التخطيط والاستدلال” من خلال ورقة بحثية بعنوان “Agent-X: تقييم قدرة الأنظمة المساعدة على الاستدلال العميق المتعدد الوسائط في المهام المرتكزة على الرؤية“. وكان الفريق بقيادة مهندسي الأبحاث في الجامعة تجمُل أشرف وأمل ثاقب، وضم في عضويته حنان غني، ومهرة المهيري، ويوهاو لي، ونور أحسن، وعمير نواز، وجان لهود، وهشام شولاكال، وفهد شهباز خان، وراو محمد أنور، وسلمان خان، إضافة إلى مبارك شاه من جامعة سنترال فلوريدا، وفيليب تور من جامعة أكسفورد.
ويمكن الاطلاع على التعليمات البرمجية هنا.
مجموعة بيانات معيارية لتقييم الأداء وليس الإجابات فقط
خلافاً لعمليات التقييم المعتادة للأنظمة المساعدة التي تركّز فقط على الإجابة النهائية، تحلل مجموعة البيانات المعيارية “Agent-X” جميع مراحل عملية الاستدلال التي تتبعها الأنظمة المساعدة من خلال دراسة كيفية تحديد المرجعيات البصرية في إطارات الفيديو، واختيارها للأدوات المناسبة، وصياغة المعطيات خطوة بخطوة.
وتضم مجموعة البيانات الجديدة 828 مهمة متنوعة تشمل الصور، والمقارنة بين عدة صور، ومقاطع الفيديو، وتغطي ستة مجالات هي الاستدلال البصري، وتصفّح الإنترنت، والأمن، والقيادة الذاتية، والرياضة، والرياضيات. ويُطلب من الأنظمة المساعدة إنجاز هذه المهام باستخدام 14 أداة تنفيذية تشمل التعرف البصري على النصوص، وعدّ العناصر، والآلات الحاسبة، وأدوات الإنترنت المختلفة.
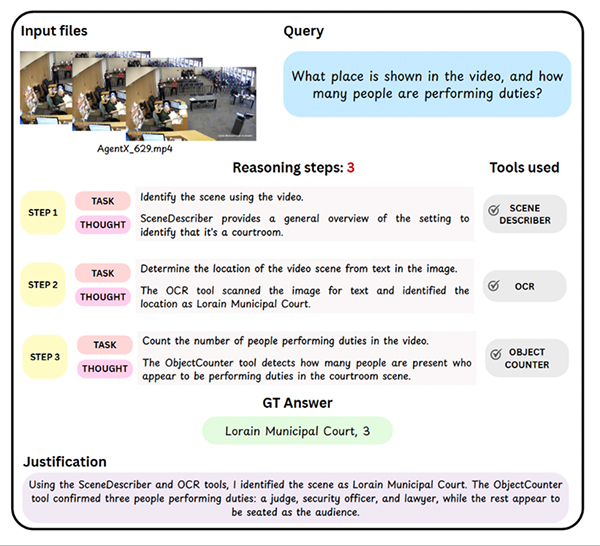
أمثلة على المهام في “Agent-X” تظهر فيها أسئلة متعددة الوسائط تتطلّب استدلالاً خطوة بخطوة، واستخدام الأدوات، وفهماً بصرياً للصور ومقاطع الفيديو
صيغت الأسئلة في مجموعة البيانات المعيارية “Agent-X” بحيث تتجنب بصورة متعمدة أي تلميحات مباشرة للأدوات لتجنّب لغة الأنظمة غير الواقعية. فبدلاً من قول “استخدم أداة التعرف البصري على النصوص” مثلاً، تُصاغ الأسئلة بلغة طبيعية تجعل النظام المساعد يستنتج بنفسه ما إذا كان استخدام أداة ضرورياً، وأي أداة يحتاجها، وما المعطيات التي يجب تقديمها لها، وهي ثلاثة جوانب تفشل فيها الأنظمة عادة في الاستخدام الواقعي.

مقارنة بين المهام في المجموعة المعيارية “Agent-X” والمجموعات المعيارية السابقة. على عكس تلك المجموعات، تتجنب الأسئلة في “Agent-X” الإشارات الصريحة والتعليمات المباشرة، مما يشجع الأنظمة المساعدة على الاستدلال والتصرّف بشكل مستقل
أُنشئت مجموعة البيانات المعيارية “Agent-X” عبر عملية إعداد شبه مؤتمتة، حيث تولّت نماذج كبيرة متعددة الوسائط صياغة المهام الأولية ومسارات الحل، بينما قام مراجعون بشريون بإزالة أي غموض، وضمان ثبات النتائج، وربط كل خطوة بالأدلة الداعمة.
تقييم أداء الأنظمة المساعدة من ثلاثة جوانب:
تقيم المجموعة المعيارية “Agent-X” أداء الأنظمة المساعدة من خلال المعايير الثلاثة التالية:
- المنهجية خطوة بخطوة: هل يستطيع النظام تحديد المرجعيات البصرية، واختيار الأداة المناسبة، وتنسيق المعطيات الصحيحة؟ وتشمل المقاييس: دقة تحديد المرجعيات البصرية، ودقة اختيار الأداة، وصحة استخدام الأداة.
- الاستدلال العميق: هل تسلسل التفكير مترابط ومطابق لمدخلات الأدوات ومخرجاتها ومدعوم بالأدلة؟ وتشمل المقاييس: الالتزام بالحقائق، ودرجة المحافظة على السياق، والدقة الواقعية، والدقة الدلالية.
- النتيجة: هل نجح المساعد في تنفيذ المهمة واستخدام الأدوات بطريقة صحيحة؟ وتشمل المقاييس: دقة الهدف، ودقة الهدف مع توليد الصور، ودقة استخدام الأدوات.
يشرح الباحث الرئيسي تجمّل أشرف أن أفضل مؤشرات الموثوقية على أرض الواقع ليست الإجابة النهائية، بل مجموع مقاييس الالتزام بالحقائق والدقة الدلالية الخاصة بالاستدلال العميق، إلى جانب دقة اختيار الأداة وصحة استخدامها. ويؤكد أن النماذج التي تحافظ على اتساق منطقها مع الأدلة وتستعين بالأدوات الصحيحة بمعطيات صحيحة تكون أقل عرضة للأخطاء الناتجة عن تغيّر البيانات. أما التصنيفات التي تعتمد على النتائج النهائية فقط، فقد تخفي مسارات هشة وغير قابلة للتكرار.
معدل نجاح دون 50% حتى في أفضل النماذج
رغم ادعاءات الصناعة، لم يتجاوز أي نموذج من النماذج الحالية نسبة 50% في دقة الهدف في اختبار “Agent-X”. فالنموذج الذي حل في المرتبة الأولى، وهو “o4-mini”، حقق دقة بلغت 45% فقط، بينما سجّلت معظم النماذج مفتوحة المصدر نتيجة تقل من 30%. وأظهرت النتائج أن النماذج ذات سلاسل التفكير الأقوى (أي التي سجلت نتائج أعلى من حيث الالتزام بالحقائق أو الدقة الدلالية) حققت أداءً أفضل. على سبيل المثال، سجّل النموذج “GPT-4o” درجات مرتفعة في مقاييس الاستدلال العميق، وانعكس ذلك في نتائج أعلى نسبياً في تنفيذ المهام. ولكن الحد الأعلى بقي منخفضاً بسبب استمرار التحديات في تحديد المرجعيات البصرية واستخدام الأدوات والحفاظ على الاتساق طوال العملية.
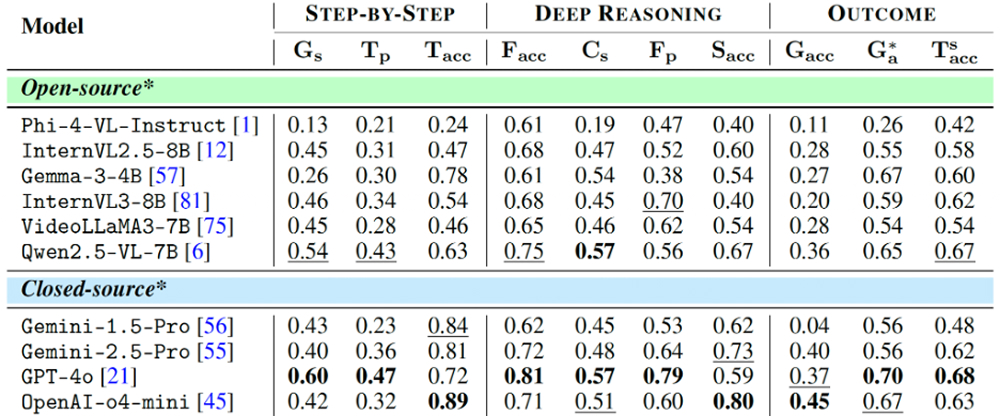
النتائج الإجمالية لاختبار “Agent-X” على مجموعة متنوعة من النماذج مفتوحة ومغلقة المصدر
تعكس هذه النتائج مجموعة من الأخطاء المتكررة، منها تجاهل الاستدلال إطاراً بإطار في مقاطع الفيديو، والاستعانة بأدوات غير مسجّلة، ومخالفة صيغ JSON، وتجاوز عمليات التحقق البصري، مما يؤدي إلى أخطاء واقعية. وأحياناً ينتج النموذج “GPT-4o” مخرجات منسّقة بدقة شكلياً لكنها غير صالحة للتنفيذ، بينما يعاني النموذج “VideoLLaMA” من ضعف في المواءمة الزمنية.
وتشمل الأخطاء الأخرى إخفاقات في الاستدلال المكاني أو في أداء المهام، وهي تنبع غالباً من مشكلات في حلقة التحكم وواجهات الاستخدام أكثر من كونها نتيجة لحجم النموذج. وحتى النماذج الأقوى، مثل “GPT-5″، قد تحسّن مقاييس الاستدلال، لكن تحقيق تقدم ملموس في دقة الهدف يعتمد على الاستعانة بأدوات وفق الصيغ المحددة وتقييد عدد مرات إعادة المحاولة المسموح بها.
كيفية تحقيق تقدّم على أرض الواقع
يؤكد أشرف أن الانتقال من نسبة نجاح 45% إلى مستوى الجاهزية للاستخدام على أرض الواقع يتطلّب تحسين قواعد الربط بين النماذج والأدوات. وهو يدعو إلى اعتماد صيغ JSON محددة، وأدوات تحقق صارمة، وآليات لإعادة المحاولة عند وقوع أخطاء بسيطة، إضافة إلى استخدام قيم ثابتة في العمليات العشوائية لضمان الحصول على النتائج نفسها عند تكرار الاختبار.
كما تُظهر نتائج الاختبار “Agent-X” أن شخصية النظام المساعد تؤثر في الأداء. فالنظام الجريء يفرط في استخدام الأدوات لكن على حساب دقة المعطيات وصحتها. والنظام المتحفظ يميل إلى استخدام الأدوات بشكل أقل من المطلوب. أما النظام المتوازن، فهو يحقق أفضل أداء، خصوصاً عند دمجه مع آليات التحقق وإعادة المحاولة. هذه النتائج تركز على الاعتمادية العملية أكثر من التركيز على ترتيب النماذج من حيث الأداء.
ومن بين جميع أنواع البيانات، كانت المهام التي تتضمن مقاطع فيديو هي الأصعب على الأنظمة المساعدة، لأن تتبع الأجسام ومكانها عبر الإطارات، والتعامل مع حجب الأجسام، والاستعانة بالأدوات في التوقيت الصحيح هي من أصعب التحديات التي تؤدي إلى فشل الأنظمة. وجاءت المقارنة بين صور متعددة في المرتبة الثانية من حيث الصعوبة بسبب ضعف الربط بين الصور وتسرّب الانتباه بين اللقطات.
كيفية بناء مجموعة البيانات “Agent-X” وأهميتها
تم إنشاء مجموعة البيانات “Agent-X” عبر عملية تنسيق شبه مؤتمتة، حيث تولّت نماذج كبيرة متعددة الوسائط صياغة المهام والمشتّتات والمعطيات المقدمة للأدوات وسلاسل الأدلة، بينما قام مراجعون بشريون بتنقيحها لإزالة الغموض، وتحديد المرجعيات البصرية، والتحقق من استخدام الأدوات، وضبط مستوى الصعوبة، وإعادة صياغة المحتوى الحساس ثقافياً. والنتيجة كانت مهام محدّدة وقابلة للتحقق، مع مسارات تفكير دقيقة على مستوى كل خطوة.
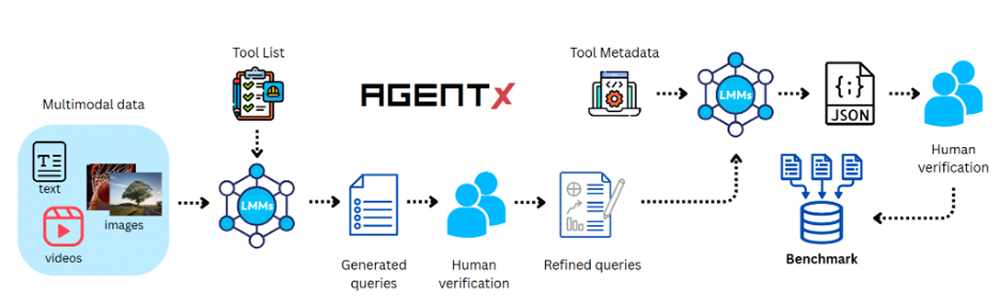
تبدأ عملية بناء مجموعة البيانات “Agent-X” من بيانات وسائط متعددة ومجموعة من الأدوات. يقوم نموذج لغوي كبير بتوليد أسئلة أولية يصحّحها المراجعون لضمان دقتها، ثم تُنشأ عملية استدلال متسلسلة خطوة بخطوة يتم صقلها لتصبح سلسلة استدلال عالية الجودة مدعّمة بالأدوات.
كانت المشاركة البشرية في هذه العملية حاسمة للانتقال من مجموعة بيانات متسقة في مظهرها إلى مجموعة اختبار موثوقة فعلاً. وقد أنشأ الباحثون أداة تحقق صغيرة مكّنت المراجعين من مطابقة كل مدخلات الأدوات ومخرجاتها مع النتيجة النهائية قبل اعتماد العينة.
ولأن بعض الإجابات ذات طبيعة وصفية، استخدم الفريق مزيجاً من أنظمة التقييم الآلية القائمة على نماذج لغوية كبيرة (مثل “GPT-4o” و”Qwen”) والمقيمين البشريين لتقييم الأداء. وتبيّن أن أفضل الأنظمة حافظت على ترتيبها النسبي مع اختلاف أنظمة التقييم والمقيمين البشريين، وظهرت معظم الاختلافات في الحالات الحدية فقط. وكان المقيمون البشريون أكثر صرامة في التعامل مع التبريرات المتخيلة، بينما أظهر النموذج “Qwen” تساهلاً أكبر مع الصياغات البديلة وميلاً إلى عدم معاقبة الأخطاء البسيطة. ولمواجهة احتمال التحايل على المقيم، تجمع المجموعة المعيارية بين تقييمات متعددة عند الحاجة وتتحقق من الأدلة للتأكد من تحديد المرجعيات البصرية بشكل صحيح.
الخطوات التالية: تعدد اللغات، وإطالة الأفق الزمني، والتطبيقات الواقعية
“Agent-X” هي مجموعة بيانات معيارية أحادية اللغة في الوقت الحالي. ويعمل الفريق على تطوير نسخة متعددة اللغات بداية باللغتين بالعربية والإسبانية، مع سيناريوهات محلية ومراجعين من الناطقين الأصليين بكل لغة. ويقيس أشرف النجاح بطريقة عملية من خلال تطوير قدرات التنبؤ بالأعطال أثناء التشغيل، وتحقيق زيادة بمقدار 10 إلى 15 نقطة في معدل النجاح في إتمام المهام، وتقليص الأخطاء في تقديم المعطيات للأدوات بنسبة 50%، وذلك عبر تطبيق معايير صارمة للمدخلات والمخرجات، ومؤشرات زمنية، وتتبع التكلفة الحسابية ومدة الاستجابة، إضافة إلى تحويل التقييم إلى خدمة مستمرة.
وعلى عكس المسابقات التي تكتفي بتقييم الأداء بناء على معيار واحد، تستخدم مجموعة البيانات “Agent-X” مقاييس متعددة تعكس سيناريوهات العمل الواقعية مثل جداول البيانات، وأنظمة المراقبة متعددة الكاميرات، وتحليل الفيديوهات، والنماذج التفاعلية على الإنترنت. وتخلص إلى نتيجة مفادها أن فشل الأنظمة المساعدة لا يرجع إلى ضعف قدرتها على توليد اللغة فحسب، بل إلى غياب قواعد الربط الدقيقة مع العالم الواقعي. وبالتالي فإن استخدام صيغ بيانات دقيقة وآليات تقييم صارمة تركز على الأداء يمكن أن يؤدي إلى إنتاج سلاسل عمل صحيحة ومنظمة قائمة على استدلال منطقي سليم.
أخبار ذات صلة

جامعة محمد بن زايد للذكاء الاصطناعي تعلن عن شراكة بحثية استراتيجية مع "مينيرفا هيومانويدز" لتطوير روبوتات بشرية لتطبيقات قطاع الطاقة
تجسّد هذه الشراكة جسراً يربط بين أبحاث الذكاء الاصطناعي التأسيسية والتطبيقات الصناعية.
اقرأ المزيد
لماذا ما زالت أنظمة الذكاء الاصطناعي اليوم عاجزة عن الاستدلال المكاني ثلاثي الأبعاد
A new benchmark by MBZUAI researchers shows how poorly current multimodal methods handle real-world geometric and perspective-based.....
- الاستدلال المكاني ,
- ثلاثي الأبعاد ,
- الأساس المعياري ,
- النماذج اللغوية-البصرية ,
- البحوث ,
- neurips ,
- المؤتمرات ,
السير مايكل برادي يدعو إلى انتقال الذكاء الاصطناعي الطبي من التشخيص إلى شرح القرارات
في إطار سلسلة المحاضرات المتميزة في جامعة محمد بن زايد للذكاء الاصطناعي، ناقش السير مايكل برادي مستقبل.....
- محاضرة زائر ,
- علم الأورام ,
- الاستدلال السببي ,
- الحرم الجامعي ,
- الطب ,
- الرعاية الصحية ,
- الرؤية الحاسوبية ,