
نهج جديد لتطوير قدرات الذكاء الاصطناعي في تشخيص الأمراض
الخميس، 14 نوفمبر 2024
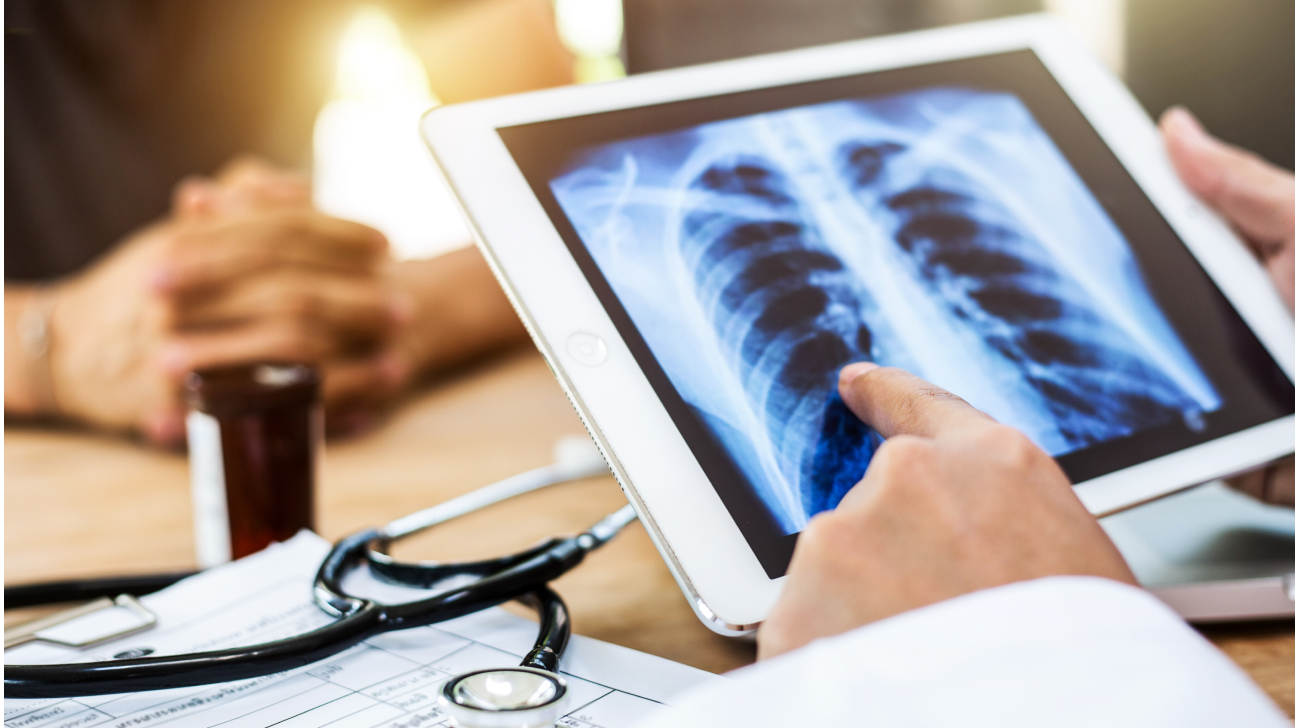
تعمل مي شعبان، وهي طالبة دكتوراة في قسم تعلم الآلة بجامعة محمد بن زايد للذكاء الاصطناعي، على تطوير أدوات ذكاء اصطناعي تساعد الأطباء في تشخيص الأمراض بدقة وسرعة. وهي تقول إن هدفها هو “تسريع عملية التشخيص بحيث تدعم نماذج الذكاء الاصطناعي الأطباء في اتخاذ القرارات المتعلقة بالمرضى”. فالتشخيص السريع والدقيق يسهم في تحقيق نتائج أفضل للمرضى من خلال تمكينهم من الحصول على الرعاية الصحية بشكل أسرع.
نجحت شعبان، بالتعاون مع زملائها من جامعة محمد بن زايد للذكاء الاصطناعي وجامعة كارلتون في كندا، في تطوير أول نظام من نوعه لتحليل صور الأشعة السينية للصدر وغيرها من بيانات المرضى لمساعدة الأطباء في تشخيص أمراض الرئة وإصاباتها. وعرض الفريق ابتكاره في المؤتمر الدولي السابع والعشرين لحوسبة الصور الطبية والتدخل المدعوم بالحاسوب الذي عقد بمدينة مراكش في المغرب.
تحليل البيانات المتعددة الصيغ
عندما يشخص الأطباء حالة مريض معين، فإنهم يحللون أنواعاً مختلفة من المعلومات، من بينها السجلات الصحية الإلكترونية التي تحتوي على نتائج تحاليل مخبرية وملاحظات خطية، والصور الطبية مثل صور الأشعة السينية. والأطباء المدربون قادرون على فهم ما تعنيه هذه البيانات المتعددة الصيغ. ولكن هذا الأمر يمثل تحدياً كبيراً بالنسبة للآلات. تقول شعبان في هذا الشأن: “سيعتمد الدور المستقبلي للذكاء الاصطناعي في مجال الرعاية الصحية على وجود بيانات متعددة الصيغ وقدرة الأنظمة على معالجة السجلات الصحية الإلكترونية والصور وغيرها من أنواع البيانات. لذلك يجب علينا إيجاد طرق لدمج تحليلاتها”.
أطلقت شعبان وزملاؤها على نظامهم اسم MedPromptX. وهو يستخدم نماذج لغوية كبيرة متعددة الصيغ وطريقة التحديد البصري مع تقديم عدد قليل من الأمثلة لتشخيص الأمراض بناءً على السجلات الصحية الإلكترونية وصور الأشعة السينية.
كما أنشأ الفريق مجموعة بيانات من سجلات مرضى تم جمعها من مجموعتي بيانات كبيرتين هما “MIMIC-IV” و”MIMIC-CXR” جرى تطويرهما في مستشفى في بوسطن. وقد أُطلق على مجموعة البيانات الجديدة اسم “MedPromptX-VQA”، وهي تضم أكثر من ستة آلاف سجل صحي فيه صور أشعة سينية للصدر. وجرى تصنيف كل سجل وفقاً للحالة المرضية لصاحبه، مثل التهاب الرئة أو الوذمة.
توضح شعبان أن السجلات الصحية الإلكترونية تحتوي عادة معلومات قيمة، ولكنها نادراً ما تكون كاملة، ما يسبب مشاكل لأنظمة الذكاء الاصطناعي. على سبيل المثال، تُرفَق عادةً مع نتائج التحاليل المخبرية معلومات توضح النطاق الطبيعي لنتيجة تحليل معين. ولكن هذه البيانات لا تُدرج دائماً في السجلات الصحية الإلكترونية، وبالتالي يصبح من الصعب على أنظمة تعلم الآلة تفسير النتائج.
وتشير شعبان إلى أن هذا الأمر دفعها وزملاءها إلى الاستعانة بالنماذج اللغوية لمساعدتهم على استكمال المعلومات الناقصة، قائلة: “علينا أن نقدم للنماذج معلومات عن النطاقات الطبيعية والنطاقات غير الطبيعية، وهذه المعلومات موجودة في النماذج اللغوية الكبيرة لأنها دُرِّبت على كميات كبيرة من البيانات الطبية ومن المرجح أنها وجدت هذه المعلومات في كتب تعليم الطب”.
تحسين الأداء
يقدم الباحثون لنموذجهم صور الأشعة السينية والسجلات الصحية الإلكترونية المقابلة لها من مجموعة البيانات “MedPromptX-VQA”، ويستخدمون طريقة التحديد البصري لمساعدة النظام على التركيز على الأجزاء ذات الصلة من صور الأشعة السينية. ويجري تحويل السجلات الصحية الإلكترونية مما يسمى بالبيانات المنظمة أو الجدولية إلى نصوص. وبعد ذلك يترجم النموذج أجزاء الصور التي تم اختيارها عبر التحديد البصري، بالإضافة إلى النسخة النصية من السجلات الصحية الإلكترونية، إلى صيغة اسمها “التضمين” يمكن لنموذج تعلم الآلة تفسيرها. وهذه التضمينات توفر معلومات أساسية للنظام حول العلاقات بين صور الأشعة السينية والسجلات الصحية الإلكترونية والتشخيصات. وعندما يُسأل النموذج عن مريض جديد، يستعين بحالات سابقة مماثلة عبر عملية طورتها شعبان وزملاؤها واسمها “اختيار الحالات القريبة” تساعد في التنبؤ بحالة المريض الجديد.
تساعد عملية اختيار الحالات القريبة في تحديد الحالات المماثلة بناء على قيمة معينة، مما يسمح للنموذج بأن يستعين في تنبؤاته فقط بالأمثلة الأقرب إلى الحالة الجديدة. وتوضح شعبان ذلك بقولها: “من خلال اختيار الحالات القريبة، نستبعد الأمثلة الغامضة ونستعين فقط بالأمثلة المشابهة لحالة المريض”، مضيفة: “نحن نعطي النموذج أمثلة يسترشد بها لتقديم أفضل إجابة على السؤال المطروح”. وهكذا تحسن هذه الطريقة دقة التشخيص وتقلل من اعتماد النموذج على مجموعات البيانات المصنفة التي يستغرق إعدادها وقتاً طويلاً.
استخدمت شعبان وفريقها أيضاً طريقة تقديم عدد قليل من الأمثلة التي تساعد النموذج على فهم نوع الإجابات المتوقعة منه. حيث أُعطي النموذج في هذه الحالة أمثلة يتراوح عددها من 4 إلى 12 مثالاً، إلى جانب سؤال جديد، لمساعدته على فهم الإجابة المرغوبة. هذه الطريقة تساعد المستخدمين على تخصيص أداء النظام تبعاً لاحتياجاتهم دون الحاجة إلى إعادة تدريبه أو ضبطه، وهما عمليتان تتطلبان الكثير من الوقت والموارد والخبرة الفنية.
لمعالجة التوجيهات النصية وتقديم إجابة بشأن حالات المرضى، يستخدم الباحثون نموذجاً لغوياً متعدد الصيغ اسمه “Med‑Flamingo” سبق تدريبه على البيانات الطبية ويمكنه معالجة المدخلات النصية والصور.
النتائج
أجرى العلماء مقارنة بين أداء “MedPromptX” وأداء أربعة نماذج أخرى، وهي “BioMedLM” و”Clinical‑T5‑Large” و”Med‑Flamingo” و”OpenFlamingo”، وذلك دون اختبار النماذج الأخرى بطريقة اختيار الحالات القريبة ودون تطبيق طريقة التحديد البصري بسبب وجود اختلافات في كيفية تعاملها مع البيانات. وقد تمكن النموذجان “Med‑Flamingo” و”OpenFlamingo” من معالجة صور الأشعة السينية والنصوص، ولكنهما لما يعالجا بيانات السجلات الصحية الإلكترونية. أما النموذجان “BioMedLM” و”Clinical‑T5″، فقد عالجا النصوص وبيانات السجلات الصحية الإلكترونية. وكان “MedPromptX” النموذج الوحيد الذي زُوِّد بصور أشعة سينية تمت معالجتها بطريقة التحديد البصري وبنصوص السجلات الصحية الإلكترونية وتوجيهات نصية.
حقق النموذج “MedPromptX” أداءً أفضل (باستخدام طريقتي اختيار الحالات القريبة والتحديد البصري) من النماذج الأخرى من حيث الإحكام (77.3%) ومقياس F1 (68.6%) والدقة (68.9%). وجاء النموذج “Clinical‑T5‑Large” في المرتبة الثانية من حيث الأداء، مسجلاً 70.7% و57.6% و59.5%، على نفس المقاييس. ودون استخدام طريقة التحديد البصري، بلغت دقة تشخيص النموذج “MedPromptX” 58.1%، متفوقاً بذلك على النماذج الأخرى. ومرة أخرى حل النموذج “Clinical‑T5‑Large” في المرتبة الثانية مسجلاً 37.1%.
اختبار النموذج على أرض الواقع
صحيح أن النموذج “MedPromptX” يمثل تقدماً في تطوير أنظمة الذكاء الاصطناعي القادرة على مساعدة الأطباء في تشخيص الأمراض، ولكن شعبان تدرك أن التأكيد الحقيقي لقدرات لهذا النموذج لا يتم إلا عبر اختباره على أرض الواقع. ولهذا سيكون من الضروري استخدامه في مرافق طبية مع مجموعة واسعة من بيانات المرضى من أجل التقييم الكامل لأثره ومدى إمكانية الاعتماد عليه. وعلى الرغم من ذلك كله فإن الهدف من تصميم أنظمة مثل “MedPromptX” ليس حلوله محل الأطباء بل مساعدتهم وتزويدهم بمعلومات قيمة تعزز الدقة والكفاءة في تشخيص الأمراض.
- تعلّم الآلة ,
- بحوث الطلاب ,
- الرعاية الصحية ,
- MICCAI ,
- البيانات ,
أخبار ذات صلة

إريك مولين: بناء الأسس العلمية لعصر الذكاء الاصطناعي من قلب أبوظبي
إريك مولين، العميد المؤسس لقسم علوم الحوسبة والرياضيات في جامعة محمد بن زايد للذكاء الاصطناعي، يوضح كيف.....
- البحث العلمي ,
- قسم علوم الحوسبة والرياضيات ,
- الحوسبة ,
- Dean ,
- computing ,
- التعليم ,
- education ,
- الرياضيات ,
- mathematics ,
- عميد ,
- research ,

دراسة حديثة تكشف ثغرة جوهرية في أبرز أدوات التحقق من الصور المولدة بالذكاء الاصطناعي
فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي يطوّر تقنية تستطيع إزالة العلامات المائية المخفية داخل.....
- العلامات المائية المخفية ,
- العلامات المائية ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

إنجاز علمي يعيد تعريف فهم العلاقات السببية ويكشف ما تخفيه البيانات
كشف العلاقة السببية: دراسة حديثة تقدم خوارزمية متطورة لتحليل المتغيرات الكامنة وفهم العلاقات السببية المعقدة دون الاعتماد.....
- تعلّم الآلة ,
- المؤتمرات ,
- البحوث ,
- كشف العلاقة السببية ,
- ICLR ,