
نموذج صغير متعدد الوسائط للفهم الفوري لمقاطع الفيديو على الأجهزة الطرفية
الاثنين، 23 يونيو 2025

عندما يتفاعل الناس مع النماذج متعددة الوسائط، فغالباً ما يكون ذلك عبر أنظمة ضخمة موجودة على أجهزة بعيدة. ورغم قوة هذه الأنظمة وسهولة استخدامها، إلا أنها تخضع لبعض القيود، حيث يحتاج المستخدم عملياً إلى اتصال دائم بالإنترنت للوصول إليها. كما قد يتردد البعض في تقديم معلومات شخصية أو حساسة لتلك النماذج.
يكمن أحد الحلول في تطوير نماذج يمكن تحميلها على ما يُعرف بالأجهزة الطرفية، مثل الهواتف المحمولة. لكن قدرات هذه الأجهزة أقل بكثير من قدرات الأنظمة الضخمة التي تشغّل النماذج الحالية. ولكي تتوافق النماذج مع الأجهزة الطرفية، يجب أن تكون أصغر حجماً وأكثر كفاءة.
في هذا السياق، خطا فريق من الباحثين في جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى خطوة مهمة نحو تذليل هذه العقبة من خلال تطوير نموذج متعدد الوسائط صغير وفعّال اسمه “Mobile-VideoGPT”.
وقد اختبر الباحثون أداء النموذج الجديد في عدد من المقاييس الخاصة بفهم الفيديو، ووجدوا أنه أسرع وأكثر كفاءة من النماذج الأخرى، مع كونه أصغر حجماً بشكل ملحوظ. ويصف الفريق هذا النموذج بأنه أول نظام فعّال لفهم الفيديو مُصمم للمعالجة الفورية.
يتحدث عبدالرحمن محمد شاكر، الحاصل حديثاً على درجة الدكتوراة في الرؤية الحاسوبية من جامعة محمد بن زايد للذكاء الاصطناعي والباحث ما بعد الدكتوراة في الجامعة والمؤلف الرئيسي للدراسة البحثية، عن سبب تطوير هذا النموذج قائلاً: “كان هدفنا تصميم نموذج فعّال لفهم الفيديو بصورة فورية دون التضحية بالأداء”.
شارك في إعداد الدراسة البحثية كل من محمد معاذ، وتشنهوي غو، وحميد رضا توفيقي، وسلمان خان، وفهد خان. ونشر الباحثون النموذج وتعليماته البرمجية بحيث تكون متاحة للجميع.
كيفية عمل النموذج “Mobile-VideoGPT”
تتمتع النماذج متعددة الوسائط الحالية، مثل سلسلة نماذج “GPT” من شركة “أوبن إيه آي” والنموذج “Gemini” من شركة “جوجل”، بالقدرة على تحليل محتوى مقاطع الفيديو وشرحه. لكن هذه النماذج مغلقة المصدر، مما يحد من إمكانية استخدامها على الأجهزة الطرفية. كما أنها تتطلب بنية تحتية حسابية ضخمة وكميات هائلة من الطاقة.
صحيح أن الباحثين طوروا نماذج متعددة الوسائط صغيرة ومتوسطة الحجم مثل “LLaVa-One-Vision” و”LLaVa-Mini”، لكن هذه النماذج لم تُصمم خصيصاً لتنفيذ المعالجة الفورية على الأجهزة الطرفية، وهو ما دفع شاكر وفريقه إلى تطوير النموذج الجديد.
يختار النموذج “Mobile-VideoGPT” الإطارات الأساسية المهمة من مقاطع الفيديو، ويستخدم طريقة تُعرف باسم الإسقاط الفعال للعناصر اللغوية تسهم في تعزيز كفاءة النموذج مع الحفاظ على مستوى أداء عالٍ.
يشير الباحثون إلى أن هذه الطريقة مستوحاة من أبحاث سابقة أجراها باحثون في “Meta GenAI” وجامعة ستانفورد وجامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى.
يتألف النموذج “Mobile-VideoGPT” من أربعة مكونات رئيسية، وهي مُشفّر صور مُدرّب مسبقاً على التباين بين اللغة والصورة ويعمل على تحديد السمات المكانية والدلالية في الصور، ومُشفّر فيديو اسمه “VideoMamba” يستخرج المعلومات الزمنية من الفيديو، ووحدة إسقاط فعال للعناصر اللغوية، ونموذج لغوي صغير يقوم على النموذج “Qwen-2.5-0.5B”.

لمحة عن النموذج “Mobile-VideoGPT”
بعد إدخال مقطع الفيديو في النموذج، يتولى مُشفّر الصور المُدرّب مسبقاً على التباين بين اللغة والصورة استخراج السمات المكانية من جميع إطارات الفيديو. ثم تُطبَّق طريقة مقترحة لتقييم الإطارات بناءً على الانتباه لاختيار الإطارات الأساسية المهمة واستبعاد الإطارات غير المهمة. يوضح شاكر هدف هذه المرحلة قائلاً: “الفكرة الأساسية في هذه الطريقة، التي لم تُطبَّق سابقاً في هذا النوع من النماذج، هي استبعاد الإطارات غير المهمة”.
يتميز مُشفّر الفيديو “VideoMamba” بكفاءته العالية، حيث يحتوي على 73 مليون معامل فقط، ويقوم بمعالجة الإطارات الأساسية لتحديد العناصر الزمنية للفيديو. بعد ذلك، يتم إسقاط هذه العناصر في فضاء بصري لغوي موحّد باستخدام وحدة الإسقاط الفعال للعناصر اللغوية. وأخيراً، يستخدم النموذج اللغوي الصغير هذه العناصر المُسقطة في الفضاء المشترك لتوليد الإجابات على أوامر المستخدمين.
يقول شاكر وزملاؤه إنه “في الحالة العادية تُرسل جميع الإطارات إلى مُشفّر الفيديو مباشرة”، لكن اختيار الإطارات الأساسية يجعل النموذج أكثر كفاءة من الناحية الحسابية دون التأثير على الأداء.
كما كان لنهج التدريب الذي اعتمده الباحثون أثر كبير على الأداء، إذ أبقوا مُشفّري الصور والفيديو ثابتين ودربوا فقط وحدة الإسقاط الفعال للعناصر اللغوية. إضافة إلى ذلك، طُبقت طريقة التكيف منخفض الرتبة على النموذج اللغوي الصغير لتحسين الأداء بكفاءة عالية من حيث عدد المعاملات. وطوّر الباحثون إصدارين من النموذج “Mobile-VideoGPT”، أحدهما يضم 0.6 مليار معامل، والآخر يضم 1.6 مليار معامل.
النتائج والخطوات التالية
قارن الفريق النموذج “Mobile-VideoGPT” مع نماذج أخرى باستخدام ستة مقاييس لتقييم فهم الفيديو، من بينها “ActivityNet-QA” و”EgoSchema” و”MVBench”. وقد سجل النموذج تحسناً بمعدل ست نقاط مقارنة بنموذج آخر مماثل في الحجم يُدعى “LLaVA-OneVision-0.5B”. كما كان أداؤه أفضل من النماذج الأخرى بنسبة 20% إلى 30% في المهام المتعلقة بالحركة.
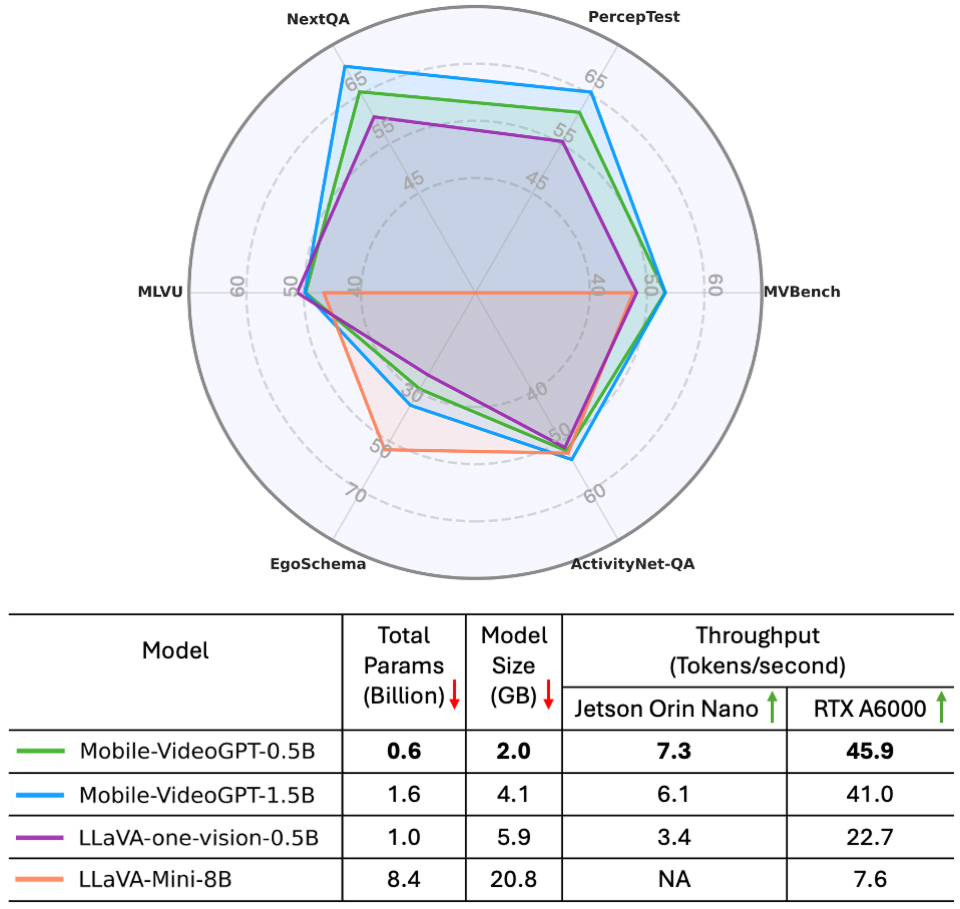
مقارنة بين أداء النموذج “Mobile-VideoGPT” وأداء النماذج المتقدمة على ستة مقاييس لفهم الفيديو، حيث جرى اختبار النماذج على جهاز طرفي. وحقق النموذج “Mobile-VideoGPT-0.5B” سرعة تفوق سرعة النموذج “LLaVA-One-Vision-0.5B” بأكثر من الضعف.
كما طلب الباحثون من النموذج “Mobile-VideoGPT” تفسير الأحداث التي تجري في مقاطع فيديو بعضها مُنشأة باستخدام الذكاء الاصطناعي وبعضها مصورة فعلياً، فاستطاع توليد أوصاف وافية تتضمن تفاصيل دقيقة مثل نوع الملابس ولغة الجسد والمكان الذي تجري فيه الأحداث.

تمكّن النموذج “Mobile-VideoGPT” من توليد أوصاف وافية لمقطع فيديو مُنشأ باستخدام الذكاء الاصطناعي خارج نطاق البيانات التي دُرِّب عليها.
بشكل عام، وجد شاكر وزملاؤه أنهم تمكنوا من تقليص عدد المعاملات في النموذج بشكل كبير مع الحفاظ على مستوى الأداء. يقول شاكر: “نموذجنا أصغر حجماً، وأفضل أداءً، ويعمل بسرعة تعادل ضعف سرعة النماذج الأخرى”. كما كانت سرعة المعالجة في النموذج “Mobile-VideoGPT” ضعف سرعة النموذج التالي له في الترتيب، وهو “LLaVA-OneVision-0.5B”.
وفي الختام، يشير شاكر إلى أن هناك حاجة لمزيد من العمل لاختبار أداء النموذج “Mobile-VideoGPT” في البيئات محدودة الموارد مثل الهواتف الذكية، مؤكداً أن فريقه خطا خطوة مهمة نحو تطوير نموذج صغير متعدد الوسائط يجمع بين السرعة والكفاءة العالية.
أخبار ذات صلة

أخبار الخريجين: كيف تعلّم عبد الرحمن شاكر إعادة تعريف الأثر في الذكاء الاصطناعي
يوضح خريج جامعة محمد بن زايد للذكاء الاصطناعي كيف تحوّل تركيزه من النشر العلمي إلى إحداث أثر.....
- ما بعد الدكتوراه ,
- البحث ,
- التأثير ,
- الدكتوراه ,
- أخبار الخريجين ,
- الخريجون ,

جامعة محمد بن زايد للذكاء الاصطناعي تعلن عن شراكة بحثية استراتيجية مع "مينيرفا هيومانويدز" لتطوير روبوتات بشرية لتطبيقات قطاع الطاقة
تجسّد هذه الشراكة جسراً يربط بين أبحاث الذكاء الاصطناعي التأسيسية والتطبيقات الصناعية.
اقرأ المزيد
الذكاء الاصطناعي وكيف تخيله الفن السابع على مر العقود
لطالما استخدم صانعو الأفلام الذكاء الاصطناعي للتعبير عن آمال البشر ومخاوفهم، وطرح أسئلة جوهرية عن معنى الإنسانية.
- الذكاء الاصطناعي ,
- الخيال العلمي ,
- الخيال ,
- السينما ,
- الفن السابع ,