
الإصدار الثاني من نموذج “كي 2 ثينك”: نظام استدلال سيادي متكامل من الجيل الجديد
الثلاثاء، 27 يناير 2026

بواسطة: معهد النماذج التأسيسية في جامعة محمد بن زايد للذكاء الاصطناعي ، فريق كي 2 ثينك
روابط سريعة: مجموعة البيانات – النموذج – الشيفرة – كي 2 ثينك – التقرير الفني للإصدار الثاني من كي 2 ثينك
يجسّد معهد النماذج التأسيسية في جامعة محمد بن زايد للذكاء الاصطناعي رسالته التأسيسية عبر التزامٍ راسخ بتطوير نماذج تأسيسية مفتوحة المصدر، وها هو اليوم يطلق أول نموذج استدلال سيادي متكامل، من خلال إصدارٍ جديد من كي 2 ثينك.
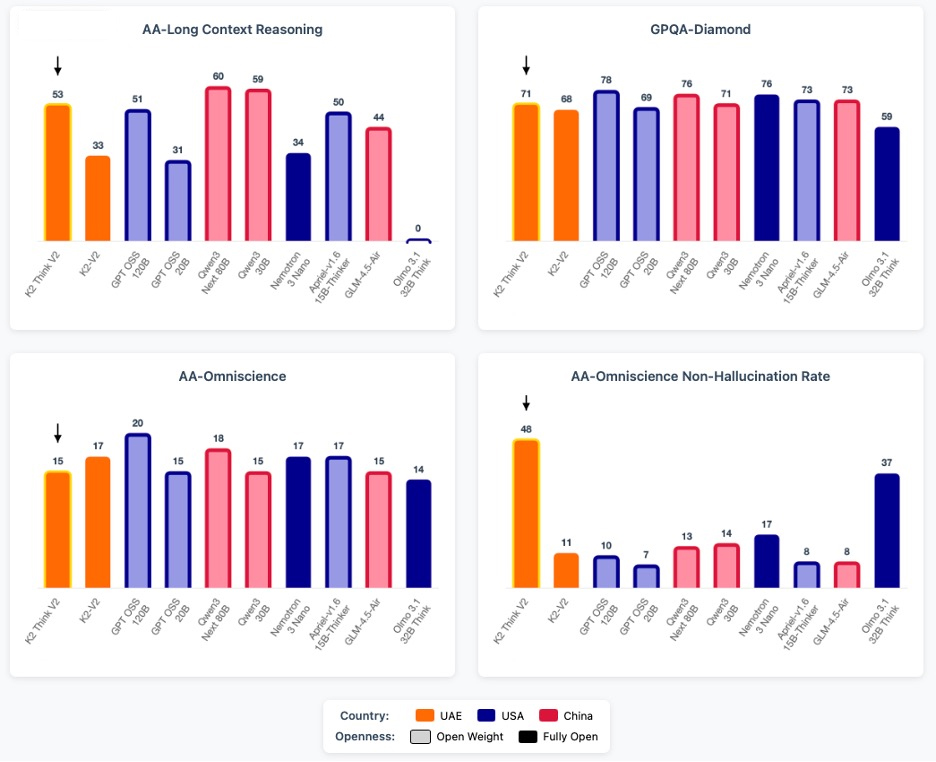
مقارنة مختارة لعدد من المقاييس المرجعية بين نماذج مفتوحة صغيرة إلى متوسطة الحجم، ملوّنة حسب بلد المنشأ. تشير الأشرطة المظللة بخفة إلى النماذج التي تتاح قيمها العددية (أوزانها) فقط، فيما تشير الأشرطة المظللة بالكامل إلى النماذج المفتوحة المصدر بالكامل. ومن خلال هذه المجموعة، نرى أن كي 2 ثينك ينافس بقوة نماذج مماثلة في الحجم، ويتفوق كذلك معدل الإجابات الخالية من الهلوسة وقدرات الاستدلال ضمن سياقات طويلة.
أصبح كي 2 ثينك الآن نموذج استدلال عام مفتوح المصدر يضم 70 مليار مُعامِل، مبنيٌّ على K2 V2 Instruct، وهو أكثر نماذج التعليمات المفتوحة المصدر بالكامل قدرةً. ويقدم كي 2 ثينك أداءً أفضل عبر العديد من مقاييس الاستدلال المعقدة، بما في ذلك AIME2025 وHMMT وGPQA-Diamond وIFBench . ومع هذا الإصدار الجديد، بات نموذج الاستدلال الرئيس لدينا سيادياً بنسبة 100% ومفتوحاً بالكامل من مرحلة ما قبل التدريب إلى مرحلة ما بعد التدريب، اعتماداً حصراً على بيانات منقحة ومُعَدّة من قِبل المعهد. وتسهم هذه الجهود مفتوحة المصدر، إلى جانب تحسين الأداء، في تقليص الفجوة بين الذكاء الاصطناعي القابل لإعادة الإنتاج والمملوك للمجتمع، وبين النماذج الاحتكارية.
وقد جرى إعداد الإصدار الثاني من كي 2 ثينك خصيصاً لمرحلة ما بعد التدريب باستخدام التعلّم المعزَّز بالمكافآت القابلة للتحقّق (RLVR) عبر مرحلة الضبط الدقيق الخاضع للإشراف (SFT) المبتكرة التي تجمع بين اتباع التعليمات وقدرات الاستدلال من خلال مستويات محددة من التفكير. وفي كي 2 ثينك، نستفيد من أعلى مستوى تفكير لاستغلال قدرات السياق الطويل في الإصدار الثاني من كي 2 ثينك لإجراء استدلال “سلسلة أفكار طويلة” (long chain-of-thought)، مع تنفيذ تدريب التعلّم المعزّز بمكافآت قابلة للتحقق على مرحلتين.
نظرة متعمقة على تطوير الإصدار الثاني من كي 2 ثينك
بعد الإطلاق التمهيدي لـ كي 2 ثينك في سبتمبر 2025، وإطلاق الإصدار الثاني من كي 2 ثينك في ديسمبر 2025، أجرينا عدة تحسينات على مجموعة بياناتنا الحالية Guru، شملت التوسّع إلى نطاقات معرفية إضافية، واعتماد ترشيح قائم على مستوى الصعوبة استناداً إلى الإصدار الثاني من كي 2 ثينك، مع ضمان خلوّ البيانات من أي تداخل مع مقاييس التقييم الرئيسة.
كما وسّعنا الجزء الخاص بتخصصات العلوم والتكنولوجيا والهندسة والرياضيات في مجموعة بيانات Guru عبر إدراج أسئلة علمية من مجموعة بيانات Nemotron المخصصة لمرحلة ما بعد التدريب، والتي لم تُستخدم في مرحلة ضبط التعليمات لنموذج K2-V2. ونواصل تبنّي استراتيجية نموذج كي 2 ثينك الأصلي، والتي تتمثل في الاقتراب من الحدود المتقدمة في المجالات الرئيسة، وهي الرياضيات والبرمجة والعلوم والتكنولوجيا والهندسة. وقد جرى اختيار البيانات بصورة أساسية من هذه المجالات، مع تنفيذ إزالة تكرار دقيقة مقارنةً بالبيانات المستخدمة في K2-V2 Instruct، وضمان خلوّها الكامل من أي تداخل مع مقاييس التقييم اللاحقة. كما أتحنا هذه النسخة المنقّحة والموسّعة بشكل طفيف من مجموعة بيانات Guru بوصفها إصداراً وسيطاً (v1.5) على منصة Hugging Face.
وقد درّبنا نموذج “كي 2 ثينك” بحجم 70 مليار معامل باستخدام الوصفة الأساسية نفسها المعتمدة في إصدارنا الأول بحجم 32 مليار معامل، مع تطبيق خوارزمية GRPO على مرحلتين. وتتوافر جميع الشيفرات المستخدمة في عملية التدريب بالكامل عبر: https://github.com/LLM360/Reasoning360 وتتضمن هذه الوصفة تعديلات طفيفة على الخوارزمية القياسية، شملت إزالة خسارتي KL والانتروبيا (entropy)، إضافةً إلى اعتماد آلية قصّ غير متماثل لنسبة السياسة (policy ratio)، مع ضبط قيمة clip_high عند 0.28. كما أجرينا تعديلين إضافيين على وصفة تدريب «كي 2 ثينك»، استناداً إلى تحليلنا لنموذج K2-V2 الوارد في تقريره الفني (القسم 7.2).
أولاً، درّبنا النموذج عند درجة حرارة بلغت 1.2، وتبيّن أنها تقع عند الحد الفاصل لاستقرار التوليد، مع إتاحة قدر أكبر من تنوّع مسارات التوليد. ثانياً، اعتمدنا تدريباً قائماً بالكامل على السياسة بحجم دفعة بلغ 256، من دون تقسيم الدفعات إلى وحدات أصغر، وذلك لتجنّب الحاجة إلى تصحيحات خارج السياسة، والتي تشير الأدبيات إلى أنها قد تؤدي إلى حالات عدم استقرار أثناء التدريب باستخدام خوارزمية تحسين السياسة النسبي على مستوى المجموعة (GRPO)
أما في المرحلة الأولى من تدريب التعلّم المعزّز بمكافآت قابلة للتحقق (RLVR)، حدّدنا الحد الأقصى لطول استجابة النموذج عند 32 ألف رمز، واستمر التدريب لنحو 200 خطوة بحجم دفعة بلغ 256. وفي المرحلة الثانية، وسّعنا طول السياق في الاستجابات المُولَّدة إلى 64 ألف رمز، واستمر التدريب 50 خطوة إضافية مع الإبقاء على إعدادات المعاملات الفائقة نفسها.
كي 2 ثينك: نحو نموذج لغوي كبير قوي وسيادي
بالاعتماد على نقطة تحقق K2 V2 Instruct، أصبح كي 2 ثينك اليوم أفضل بكثير مقارنةً بإصداره التمهيدي بحجم 32 مليار معامل. فمن خلال تنسيقٍ مخصص لمجموعة بيانات تدريبية غنية بالمعلومات كما ورد أعلاه، والبناء على قاعدة قوية، استطعنا تحقيق تحسينات جوهرية مقارنةً بإصدار خريف 2025. وقد تحسّن كي 2 ثينك بشكل واسع عبر مقاييس الاستدلال الأساسية في الرياضيات والعلوم والبرمجة، مع مكاسب إضافية نابعة من قدرات K2 V2 القوية أصلاً في اتباع التعليمات.
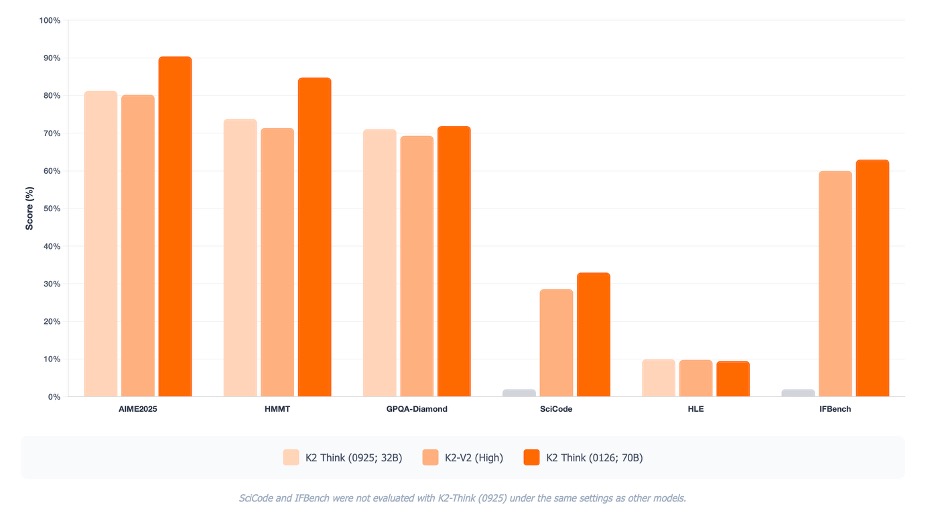
تقييمات مرجعية مختارة بين إصدارات “كي 2 ثينك” ونموذج كي 2 ثينك الإصدار الثاني. نلاحظ أن التدريب الناجح للإصدار الثاني دفع أداءه ليقترب إلى حدّ كبير من مستوى “كي 2 ثينك”الأصلي. كما أن مرحلة ما بعد التدريب القائمة على K2-V2 أسهمت في تحسين أداء الاستدلال بصورة إضافية. ملاحظة: جرى تقييم مجموعتي SciCode وIFBench ضمن الإعدادات نفسها المستخدمة في الإصدار السابق من “كي 2 ثينك”. ولتفادي المقارنات غير متسقة، لم ندرج هذه النتائج في الشكل، مع الإشارة إلى غيابها باللون الرمادي.
استناداً إلى تقييمنا الداخلي لنموذج «كي 2 ثينك»، والمدعوم بتقييم مستقل من جهة خارجية وهي Artificial Analysis، يسرّنا أن نؤكد أنه يُعدّ أقوى نموذج استدلال مفتوح المصدر بالكامل حتى مع جولاتنا الأولية من مرحلة ما بعد التدريب (مع المزيد من التحديثات المرتقبة).
وربما الأهم من ذلك أن هذا الإصدار الجديد من “كي 2 ثينك” بحجم 70 مليار معامل يتمتع بسيادة كاملة في بنيته، إلى جانب كونه مفتوح المصدر بالكامل. وستُطوَّر الإصدارات المستقبلية من “كي 2 ثينك” بالتوازي مع التحسينات التي نُدخلها على نماذجنا الأساسية، مع توقع ظهور قدرات جديدة من خلال استكشاف البنية المعمارية، وتعزيز استخدام الأدوات بأسلوب قائم على الوكلاء، وتطوير وصفات جديدة للتعلّم المعزّز.
إصدار ثان من كي 2 ثينك ذكي وموثوق
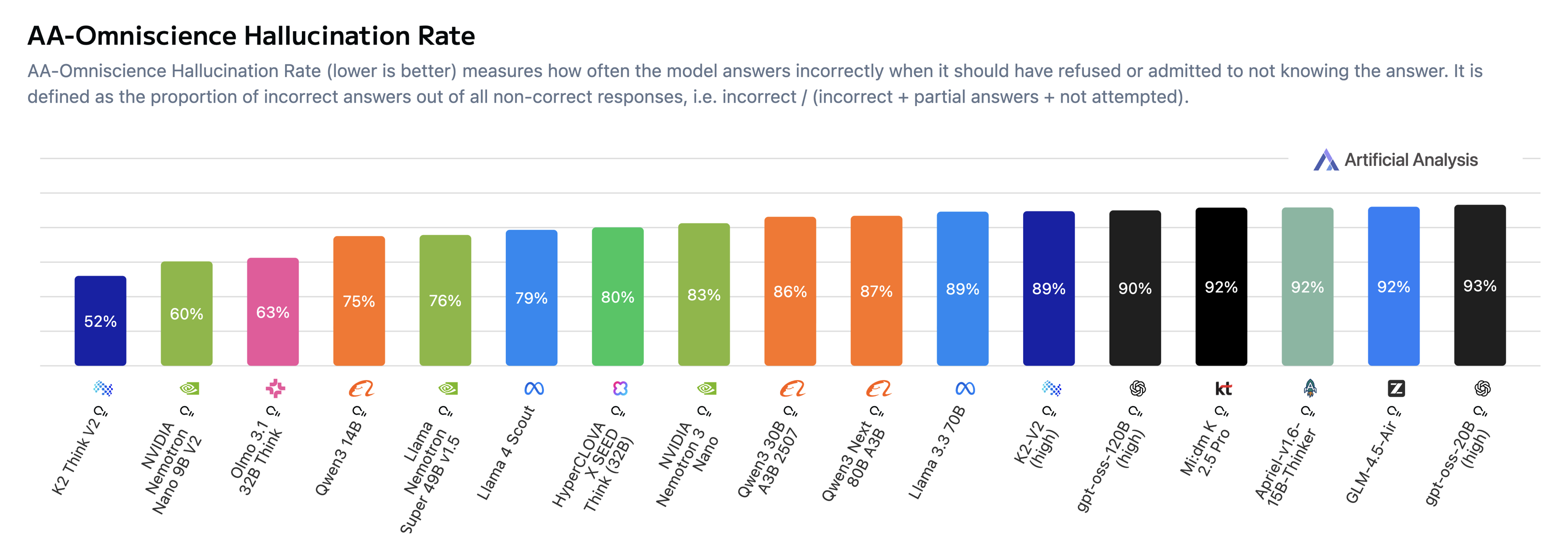
تلقّينا تقييماً مستقلاً من جهة خارجية وهي Artificial Analysis لتقديم تقييم موضوعي للإصدار الثاني من “كي 2 ثينك”. واستناداً إلى تحليلهم متعدد المقاييس، نلاحظ أن مرحلة ما بعد التدريب باستخدام التعلّم المعزّز بمكافآت قابلة للتحقق (RLVR) على نموذج K2-V2 أسفرت عن تحسّن ملحوظ بمقدار 4 نقاط. ويعود هذا التحسّن في المقام الأول إلى انخفاض كبير في معدل الهلوسة (من 89% إلى 52% على مقياس AA-Omniscience (الموضح أدناه، إضافةً إلى تحسّن ملحوظ في الاستدلال ضمن السياقات الطويلة (من 33% إلى 53%)، وذلك استناداً إلى القدرات القوية التي يتمتع بها K2-V2 في التعامل مع السياق الطويل (انظر الشكل المركّب لنتائج مقاييس AA في نهاية هذا القسم). وتحمل هذه المزايا المحددة لنموذج “كي 2 ثينك” دلالات عملية مهمة، إذ يتيح النموذج الاحتفاظ بالتفاصيل الجوهرية المضمّنة ضمن سياقات واسعة النطاق.
تخيّل أنك تحتاج إلى اتخاذ قرار استثماري عبر نقاشات متعددة الجولات أو من خلال مجموعة وثائق؛ عندها يُتوقع من النموذج أن يستدل بفعالية على هذه المعلومات دون اختلاق أرقام مالية. ويقدّم كي 2 ثينك الاتساق والموثوقية المطلوبة في مثل هذه السيناريوهات.
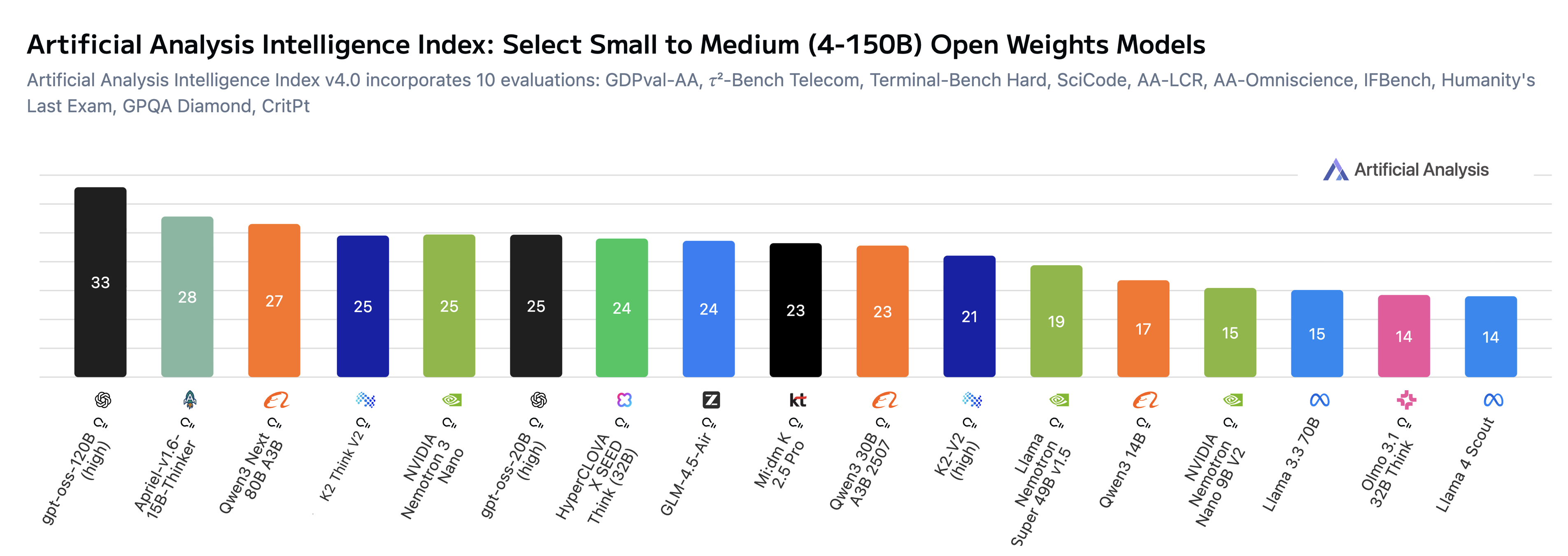
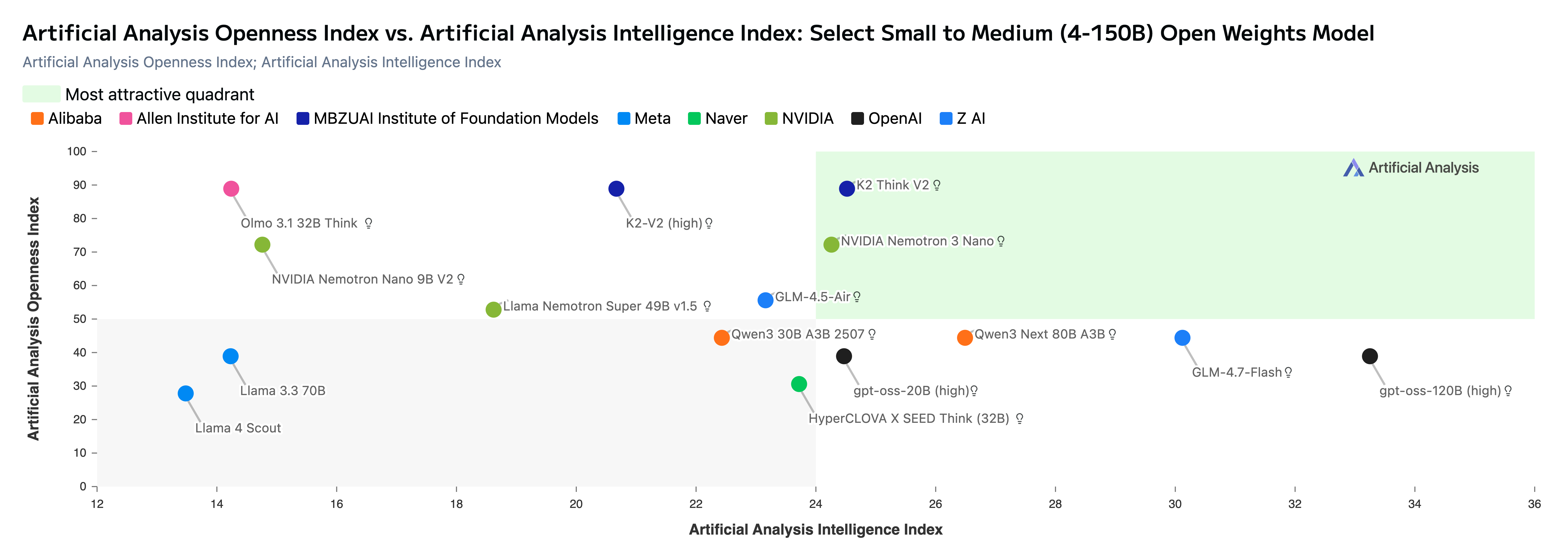
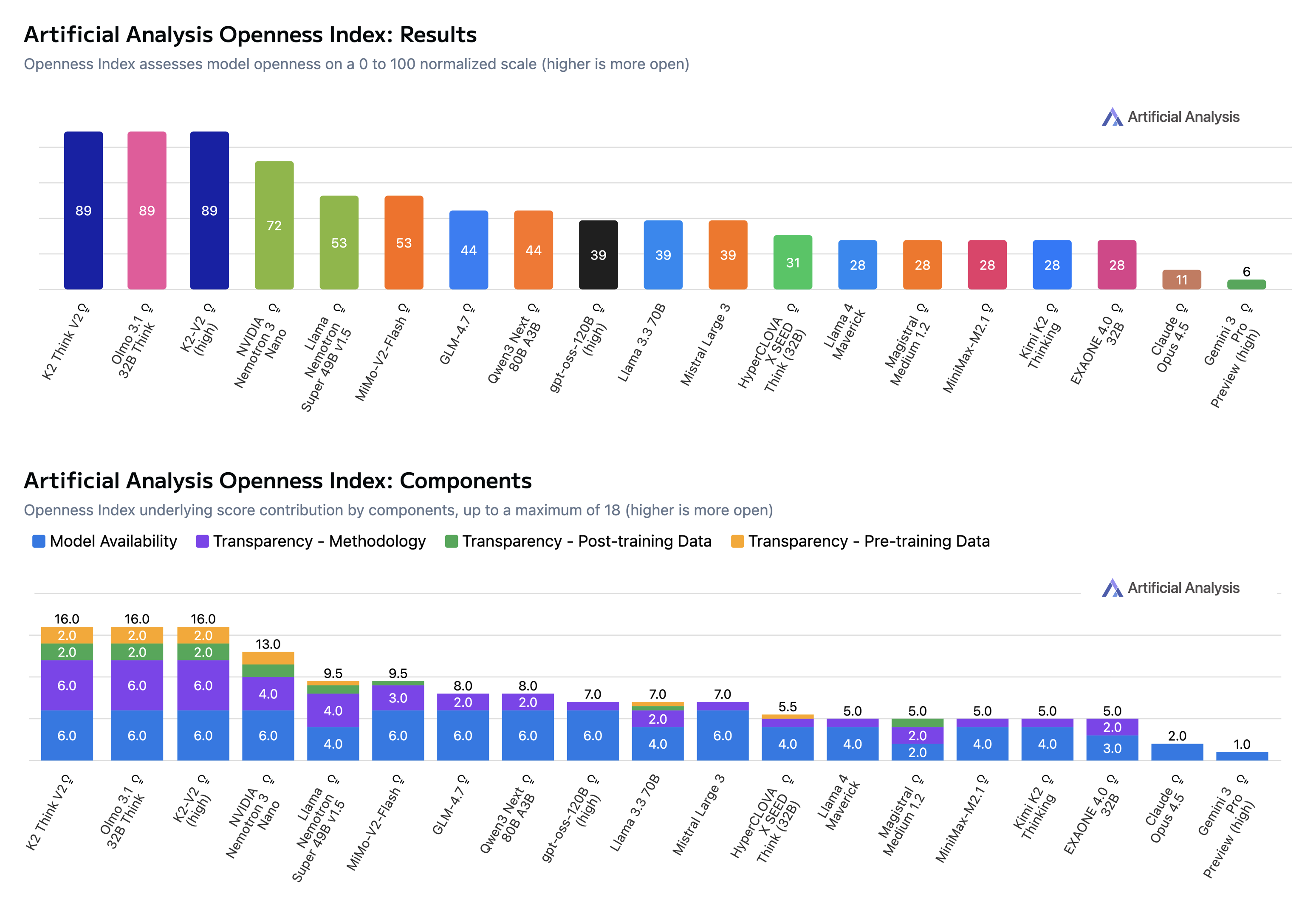
ويُعترف بالتزامنا بالمصدر المفتوح عبر “مؤشر الانفتاح” لدى Artificial Analysis، حيث أصبح كي 2 ثينك الآن متصدراً بالمناصفة مع الإصدار الثاني من كي 2 ثينك وOlmo 3. ومع تحسن “مؤشر الذكاء” في كي 2 ثينك واستمرار الإتاحة المفتوحة بالكامل، أصبح نموذجنا عند «حد باريتو» لنماذج الاستدلال ذات القيم العددية (الأوزان) المفتوحة (انظر الشكل أدناه الذي يعرض نماذج مفتوحة صغيرة إلى متوسطة). وتظهر التقييمات فرصة واعدة لمواصلة تطوير كي 2 ثينك. وفي الوقت الحالي، لم يُضبط نموذجنا بعد للاستفادة من الأدوات في المهام الوكيلية (agentic tasks)، لكنه يُظهر إمكانات عالية. وتمثل هذه النقطة محور تركيز واضح ونحن نسعى إلى تحسين النماذج. ونؤكد التزامنا بدفع كي 2 ثينك ليصبح نظام الاستدلال الأكثر قدرةً والمتاح على نطاق واسع.
روابط سريعة: مجموعة البيانات – النموذج – الشيفرة – كي 2 ثينك – التقرير الفني للإصدار الثاني من كي 2 ثينك
تقييم السلامة
كخطوة تقييم أخيرة قبل الإطلاق، أجرينا تقييماً صارماً لمتانة نموذج «كي 2 ثينك»، وآليات الرفض، ومدى قابليته للتأثر بمحاولات التلاعب العدائي عبر نطاقات سلامة متعددة. وقد أُجري هذا التقييم باستخدام إطار libra-eval الذي يوفّر دعماً مدمجاً لطيف واسع من مقاييس السلامة. وإضافةً إلى مقاييس السلامة العامة، نجري أيضاً اختبارات المحاكاة الهجومية (red-teaming) لتقييم سلوك النموذج في الجوانب المرتبطة بالسياقات الإقليمية والثقافية.
ويمكن الاطلاع على تقرير كامل لهذه التحليلات عبر الرابط هنا. وتعكس هذه الفئات محاور السلامة الأساسية الأكثر صلة بالنشر الواقعي لنموذج «كي 2 ثينك»، إذ تغطي كلاً من أضرار المحتوى الجوهرية والمخاطر المرتبطة بالنشر في مجالات محددة. ونستعرض فيما يلي ملخصاً لأبرز النتائج التي تعكس الأداء المتقدم للنموذج من حيث المتانة وخصائص السلامة.
يحقق “كي 2 ثينك” درجات شبه مثالية على مجموعات البيانات الضارة القياسية، بما يؤكد قوة المواءمة الأساسية التي تم ترسيخها من خلال مرحلة الضبط الدقيق الخاضع للإشراف (SFT) المبتكرة في نموذج K2-V2، والتي جمعت بين ضبط التعليمات وتعزيز قدرات الاستدلال. والأهم أن هذا التحديث من “كي 2 ثينك” عالج المشكلات التي واجهها النموذج السابق فيما يتعلق بما يُعرف بـ “الرفض المفرط”. ويعكس ذلك فهماً دلالياً عميقاً يمكّن النموذج من الإجابة بأمان عن استفسارات حساسة لكنها غير ضارة، أو من رفض الإجابة بثقة عندما يكون ذلك أكثر ملاءمة. وبالمقارنة مع النتائج المرتفعة في بقية مجموعات البيانات، يحقق”كي 2 ثينك” أداءً مرضياً، مع بقاء مجال للتحسين في جوانب السلامة الفيزيائية ومنع تسرب بيانات التعريف الشخصية.
وبفضل قدراته في التعامل مع السياقات الطويلة، يحتفظ النموذج بتعليمات نظام السلامة عبر نوافذ سياق ممتدة. وفي المقابل، يسجّل “كي 2 ثينك”قفزة نوعية في قدرات السلامة التقنية، بتحسّن يتجاوز 66% مقارنةً بالإصدارات السابقة، حيث نجح في رفض 89.5% من طلبات توليد الثغرات البرمجية.
| مجال السلامة | المجالات المكوِّنة الأساسية | معدل السلامة | مستوى المخاطر |
|---|---|---|---|
| سلامة المحتوى والسلامة العامة | العنف، الكراهية، الجريمة، السلامة الطبية | 98.20% | منخفض |
| الصدق والموثوقية | المعلومات المضللة، الخداع | 97.98% | منخفض |
| المواءمة المجتمعية | التمييز، التحيّز، السُمية | 97.25% | منخفض |
| البيانات والبنية التحتية | الخصوصية، المعلومات الشخصية القابلة لتحديد الهوية، السلامة الفيزيائية | 83.00% | حرج |
وبصورة عامة، يرسّخ “كي 2 ثينك” أساساً متيناً في مجال السلامة، مع معالجة فعّالة لما يُعرف بـ “كلفة المواءمة” (alignment tax) التي رافقت الإصدارات السابقة، من دون التأثير في قدرة النموذج على تقديم المساعدة.
الجهود المستقبلية
تتزايد الأدلة على أن إطالة مرحلة ما بعد التدريب باستخدام التعلّم المعزّز تسهم في تحقيق فوائد متواصلة (انظر تقارير Olmo 3.1 و Intellect-3Tech. ونعمل على مواصلة تطوير “كي 2 ثينك” بهدف بناء نماذج عامة متعددة الاستخدامات تتمتع بأعلى مستويات القدرة، ومُحسّنة للاستدلال واستخدام الأدوات والمهام القائمة على الوكلاء. كما نعمل بصورة نشطة على إعداد وتنقيح مصادر بيانات جديدة لدعم هذه القدرات وتعزيزها. ولدينا العديد من التطورات الواعدة قيد التنفيذ لعام 2026، ونتطلع إلى مشاركتها علناً مع استمرارنا في تطوير نماذج مفتوحة المصدر بالكامل عبر مختلف الأحجام. ترقّبوا المزيد.
- llm ,
- معهد النماذج التأسيسية ,
- K2 Think ,
- K2 ,
- نموذج تأسيسي ,
- سيادي ,
- استدلال ,
أخبار ذات صلة

إريك زينغ وآفاق المرحلة التالية للذكاء الاصطناعي ونماذج العالم
أجرى البروفيسور إريك زينغ، رئيس جامعة محمد بن زايد للذكاء الاصطناعي، مقابلة مع صحيفة «واشنطن بوست» تناول.....
- النماذج التأسيسية ,
- Eric Xing ,
- إريك زينغ ,
- foundation models ,
- IFM ,
- PAN ,
- معهد النماذج التأسيسية ,
- genbio ,
- world model ,
- embodied intelligence ,
- president office ,
- الذكاء المتجسد ,
- مكتب الرئيس ,
- نماذج العالم ,

جامعة محمد بن زايد للذكاء الاصطناعي تطلق الإصدار الثاني من نموذج "كي 2 ثينك" كنظام استدلال سيادي متكامل من الجيل الجديد
يعتمد نظام الاستدلال المتقدم الجديد، الذي يضم 70 مليار مُعامِل، على النموذج الأساسي K2-V2، أقوى نموذج تأسيسي.....
اقرأ المزيد
البروفيسور إريك زينغ يستشرف في دافوس اتجاهات تطور تكنولوجيا الذكاء الاصطناعي
في كلمة له خلال فعاليات المنتدى الاقتصادي العالمي في دافوس، البروفيسور إريك زينغ يستعرض اتجاهات تطور الذكاء.....
اقرأ المزيد