
“K2”: نموذج مفتوح المصدر بقدرات جد متطورة
الجمعة، 05 ديسمبر 2025

تعرّف على الإصدار الجديد من النموذج “K2“: التقرير الفني | صفحة النموذج
إذا كنت تتابع أبحاث الذكاء الاصطناعي ولو بشكل عام، فمن المرجح أنك لاحظت وجود فجوة بين ما تستطيع النماذج الرائدة تحقيقه، وبين ما يُتاح لنا معرفته عن كيفية بنائها. وعلى الرغم من أن النماذج ذات القيم العددية (الأوزان) المفتوحة وفّرت قدراً من الشفافية وإمكانيات التخصيص، فإن البيانات ومنحنيات التدريب والوصفات الهندسية تبقى محجوبة في الغالب، ما يجعل تطوير نماذج الذكاء الاصطناعي عملية تفتقر إلى الشفافية.
في إطار عملنا في معهد النماذج التأسيسية بجامعة محمد بن زايد للذكاء الاصطناعي الذي نركز فيه على النماذج الرائدة، نطلق إصداراً جديداً من النموذج “K2” في محاولة مقصودة لمقاومة هذا الاتجاه. والنموذج “K2” هو نموذج تأسيسي موجّه للاستدلال ويضم 70 مليار معامل صُمّم ليس فقط لتحقيق أداء قوي، بل ليكون مفتوحاً بشكل كامل، بما في ذلك القيم العددية والتعليمات البرمجية التدريبية وتركيبة البيانات ونقاط الحفظ خلال التدريب الوسيط وأطر التقييم. كما أنه يُعد أقوى نموذج مفتوح بالكامل حتى الآن، حيث ينافس أبرز النماذج ذات القيم العددية المفتوحة ضمن نفس فئة الحجم، متفوقاً على النموذج “Qwen2.5-72B”، ومقترباً من أداء النموذج “Qwen3-235B”.
وعلى خلاف العديد من النماذج “المفتوحة” التي تقتصر عملياً على مهام المحادثة، جرى بناء النموذج “K2” من الصفر ليكون أساساً للاستدلال العميق ومعالجة السياقات الطويلة واستخدام الأدوات بصورة أصيلة، بالإضافة إلى وظائف مثل الحوار واسترجاع المعرفة.
نموذج عام قوي وأساس للاستدلال المتقدم
انطلقنا من فرضية بسيطة مفادها أنه لا يمكن دراسة نظام استدلال متقدم أو استخدامه على أساس ضعيف. لذلك جرى بناء “K2” كنموذج محوّل كثيف يضم 70 مليار معامل، ما يضعه في نفس فئة النموذج “Qwen2.5-72B”، الذي يُعتبر من أكثر نماذج المطورين استخداماً اليوم، ولكن مع قدرات استدلال أقوى بفضل تصميمه المخصص لمرحلة التدريب الوسيط.
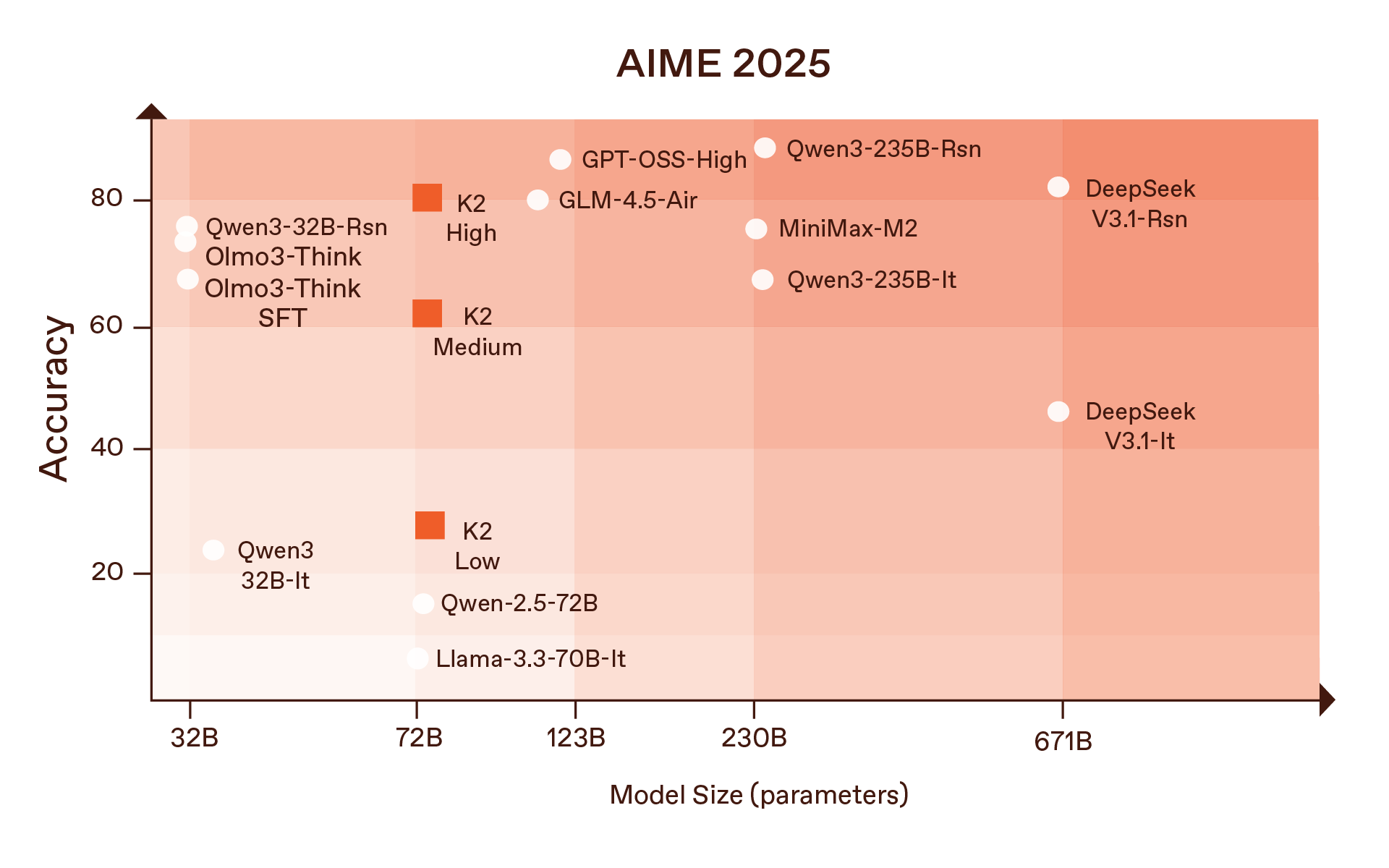
ولكن بنية النموذج ليست سوى نقطة البداية. وما يميز النموذج “K2” فعلاً هو فلسفة التدريب. فبدلاً من التعامل مع الاستدلال كإضافة لاحقة تُطبَّق في المرحلة النهائية عبر ضبط سطحي لسلسلة الأفكار، دمجنا الاستدلال بعمق في المرحلة المتوسطة من تطوير النموذج، بحيث تتشكل التمثيلات الأساسية قبل مرحلة الصقل النهائية بوقت طويل.
وهنا نعرض خمسة محاور جرى تحسينها بشكل جلي:
- معرفة عامة واسعة النطاق.
- خبرة متعمقة في مجالات الرياضيات والبرمجة والعلوم.
- قدرة كبيرة على معالجة السياقات الطويلة.
- تعرّف مبكر على سلوكيات الاستدلال مثل التخطيط والرجوع المنهجي.
- قدرات مدمجة على استدعاء الأدوات، مثل تنفيذ التعليمات البرمجية والبحث عبر الإنترنت.
للوصول إلى ذلك، يمر النموذج “K2” بثلاث مراحل تدريبية متميزة:
- التدريب المسبق لاكتساب المعرفة الواسعة والطلاقة.
- التدريب الوسيط لغرس مهارات التعامل مع السياقات الطويلة وسلوكيات الاستدلال الواضحة.
- الضبط الدقيق الخاضع للإشراف لتحويل النموذج إلى مساعد قابل للاستخدام يدعم استدعاء الأدوات واتباع التعليمات، مع الإبقاء على مساحة كافية للتعلم التعزيزي مستقبلاً.
في التقرير الفني المنشور، نستخدم مراراً مصطلح “مفتوح بشكل كامل” لتمييز نهجنا عن الإصدارات التقليدية للنماذج ذات القيم العددية المفتوحة. ووفقاً لتعريفنا، لا يكون النموذج مفتوحاً بحق ما لم يُنشَر معه أيضاً:
- كامل بيانات التدريب المسبق (أو على الأقل تركيبها الدقيق ووصفة تنسيقها).
- أي مجموعات بيانات مستخدمة في التدريب الوسيط، مثل مجموعة “TxT360-Midas” الغنية ببيانات الاستدلال التي نقدمها هنا.
- بيانات الضبط الدقيق الخاضع للإشراف “TxT360-3efforts” التي تعلّم النموذج التفاعل والاستدلال بمستويات جهد مختلفة واستدعاء الأدوات.
- سجلات التدريب والمعاملات الفائقة وتفاصيل البنية التحتية، بما في ذلك كيفية التعامل مع طفرات الخسارة وأحجام الدُفعات وقوانين التوسّع.
وتكتسب النقطة الأخيرة أهمية خاصة لأن التدريب المستمر، أي أخذ نموذج أساسي مُدرب وتوجيهه نحو مجال أو مهمة جديدة، أصبح هو القاعدة في الصناعة. لكن في النماذج المغلقة، يبقى الباحث مضطراً للتخمين بشأن ما تتضمنه القيم العددية. ولهذا نشرنا بشكل واضح نقاط الحفظ خلال التدريب الوسيط وتركيب البيانات، بما يتيح للباحثين الآخرين تخطيط عمليات تكييف المجالات دون محو قدرات قائمة عن غير قصد أو تكرار خصائص توزيعية هشة.
ويرتبط الأمر أيضاً بقابلية إعادة الإنتاج العلمي، حيث يوضح تقريرنا الخيارات المستندة إلى قوانين التوسّع. فنحن نتتبع ما نسميه “المدى الزمني الفعّال للتوسيط”، ونضبط معدلات التعلم وأحجام الدُفعات ضمن سقف محدد يبلغ نحو 12 تريليون عنصر لغوي، كما نناقش الحالات التي يؤدي فيها جدول خفض التعلم إلى الصفر إلى استقرار في قيم المعاملات.
تعليم نموذج بحجم 70 مليار معامل على التفكير أثناء التدريب
تُعد مرحلة التدريب الوسيط الجزء الأكثر ابتكاراً في النموذج “K2″، حيث يكون النموذج قد أصبح قوياً بالفعل، لكنه لم يكتسب بعد قدرات الاستدلال الكاملة. وهنا ركّزنا جهودنا الأساسية.
أولاً، زدنا طول السياق إلى 512 ألف عنصر لغوي. ثانياً، بدأنا بتزويد النموذج بمسارات تفكير واضحة، أي حلول خطوة بخطوة لمسائل متنوعة على نطاق واسع. وقد جمعنا أكثر من 250 مليون مسألة رياضية فريدة ووضعنا لها حلولاً، ما أسفر عن بناء مجموعة بيانات ضخمة تقترن فيها كل مسألة بسلسلة خطوات استدلالية تقود إلى الحل، وليس بالحل فقط.
إلى جانب ذلك، عملنا على توليد أنماط استدلال لا ترتبط بالرياضيات وحدها، مثل التحليل ثنائي المسار والتخطيط واستكشاف علوم البيانات، وحتى تعليمات إجرائية بأسلوب الأدلة الإرشادية. وقد شملت هذه العملية أكثر من مئة قالب أوامر تغطي أنماطاً مختلفة من “طرائق التفكير”، وجميعها مستندة إلى أسئلة حقيقية لمستخدمين جرى جمعها من مجموعات بيانات مفتوحة للتعليمات.
كان الهدف من ذلك جعل الاستدلال سلوكاً أصيلاً في النموذج، أي قدرة رآها وتدرّب عليها في مجالات متعددة، وليس فقط في الاختبارات المصممة بعناية التي تهيمن على نماذج الاستدلال الحديثة القائمة على التعلّم التعزيزي.
بعد اكتمال مرحلة التدريب الوسيط، طبقنا مرحلة ضبط دقيق خاضع للإشراف بحجم متواضع نسبياً، دربنا فيها النموذج على مزيج مُنتقى من بيانات المحادثة واستخدام الأدوات وبيانات الاستدلال “TxT360-3efforts” باستخدام ضبط دقيق خاضع للإشراف لجميع المعاملات مع تسلسلات طويلة وحزماً مكثفاً للتسلسلات، بحيث لا تُهدر العناصر اللغوية في الحشو. وكانت مدة هذه المرحلة قصيرة عمداً لإثبات أن قدراً محدوداً من الضبط يمكنه استحضار قدرات قوية عندما تكون القاعدة الأساسية مُعدّة جيداً.
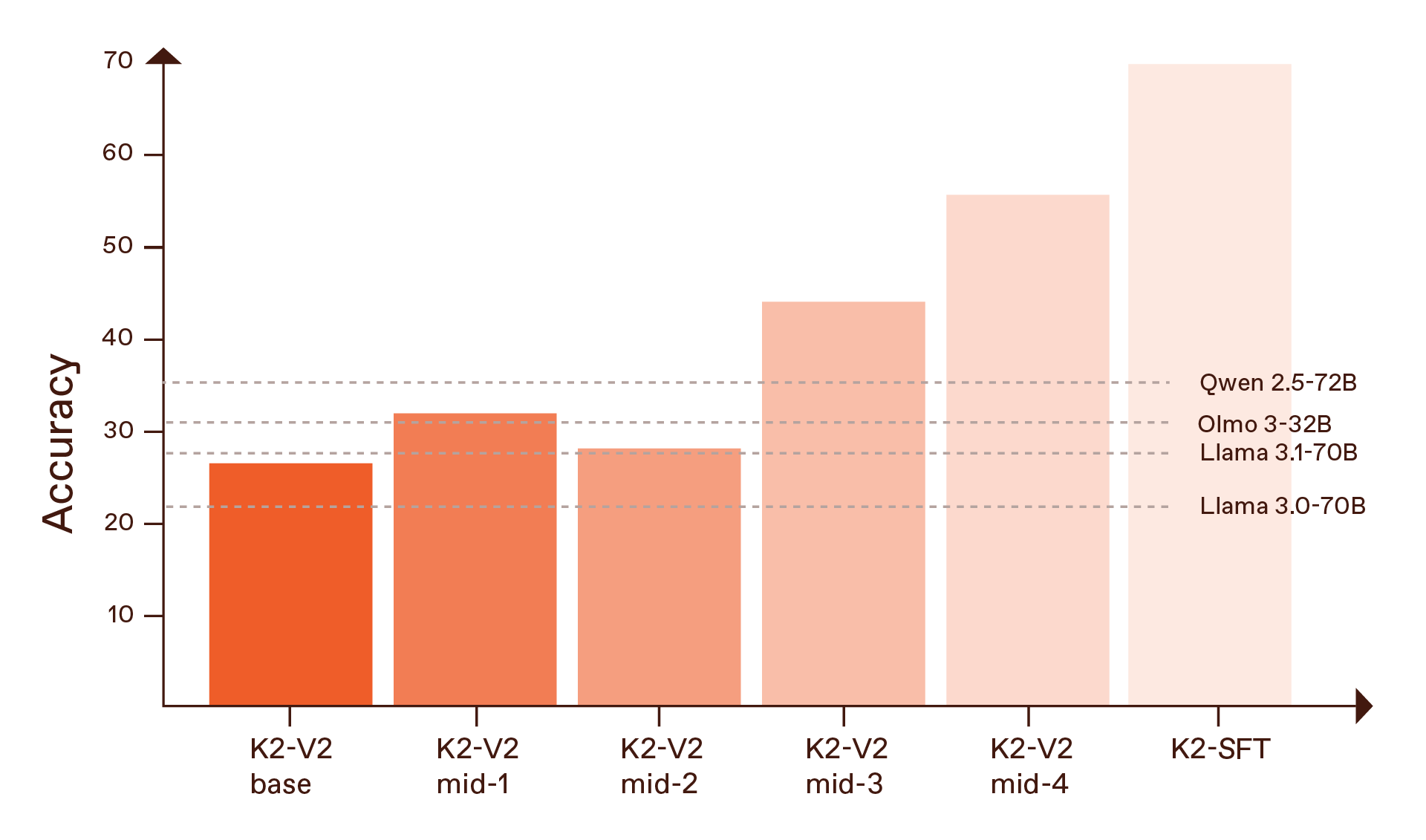
أجرينا تقييماً للنموذج بكامله عبر عدة محاور تشمل المعرفة العامة، والرياضيات والعلوم والتكنولوجيا والهندسة، والبرمجة، والإجابة عن الأسئلة ذات السياق الطويل، واستخدام الأدوات. وبالنسبة للباحثين في الذكاء الاصطناعي، تُعد نتائج النموذج الأساسي من أكثر النتائج لفتاً للانتباه. ففي نقطة الحفظ “mid-4″، وهي الأقوى ضمن مراحل التدريب الوسيط، حقق “K2” ما يلي:
- نسبة 55.1% في مجموعة البيانات المعيارية “GPQA-Diamond”، وهي مجموعة بيانات علمية متقدمة في مستوى الدراسات العليا. وترتفع هذه النسبة إلى 69.3% بعد مرحلة الضبط الدقيق الخاضع للإشراف المحدودة.
- نسبة 93.6% في مجموعة البيانات المعيارية “GSM8K” باستخدام أوامر استدلال منظمة.
- نسبة 94.7% في مجموعة البيانات “MATH”.
- وفي اختبارات المنطق، كان أداؤنا في لغز الفرسان والكذابين في المستوى الأصعب (ثمانية أشخاص) يماثل أداء نماذج مدرَّبة بالكامل مثل “DeepSeek-R1″ (83%) و”o3-mini-high” (83%). ويُعد لغز الفرسان والكذابين من الألغاز المنطقية الشهيرة التي تتطلب استخدام الاستدلال لاكتشاف الصادقين والكاذبين ضمن مجموعة من الأشخاص.
جميع هذه النتائج تساوي أو تتجاوز أفضل النماذج ذات القيم العددية المفتوحة التي جرت المقارنة معها، بما في ذلك “Qwen2.5-72B”، وتظهر تفوقاً خاصاً في الألغاز التي تتطلب قدرات استدلال كبيرة مثل العد التنازلي ولغز الفرسان والكذابين.
أما في المؤشرات العامة، فتقدم النتائج صورة أكثر توازناً. فالنموذج “K2” لا يتفوق على النموذج “Qwen” في مجموعة البيانات المعيارية الشاملة “MMLU”، لكنه يتألق في المجموعات الأصعب مثل “MMLU-Pro” و”GPQA-Diamond”، حيث يكون الاستدلال الدقيق والإجابات المنضبطة أهم من مجرد استرجاع المعلومات المدرسية.
GPQA-DIAMOND
في النموذج “K2” بعد ضبطه الكامل، حددنا ثلاثة مستويات للجهد المبذول في الاستدلال (منخفض ومتوسط وعالٍ) يتحكم كل منها في عدد العناصر اللغوية الخاصة بالتفكير التي يولدها النموذج قبل إعطاء الإجابة. ويحقق الجهد العالي أقوى النتائج في مسائل الرياضيات ومهام البرمجة الصعبة مثل مسابقات “AIME 2025” و”HMMT 2025″، وكذلك مجموعتي البيانات المعياريتين “GSM8K” و”HumanEval”.
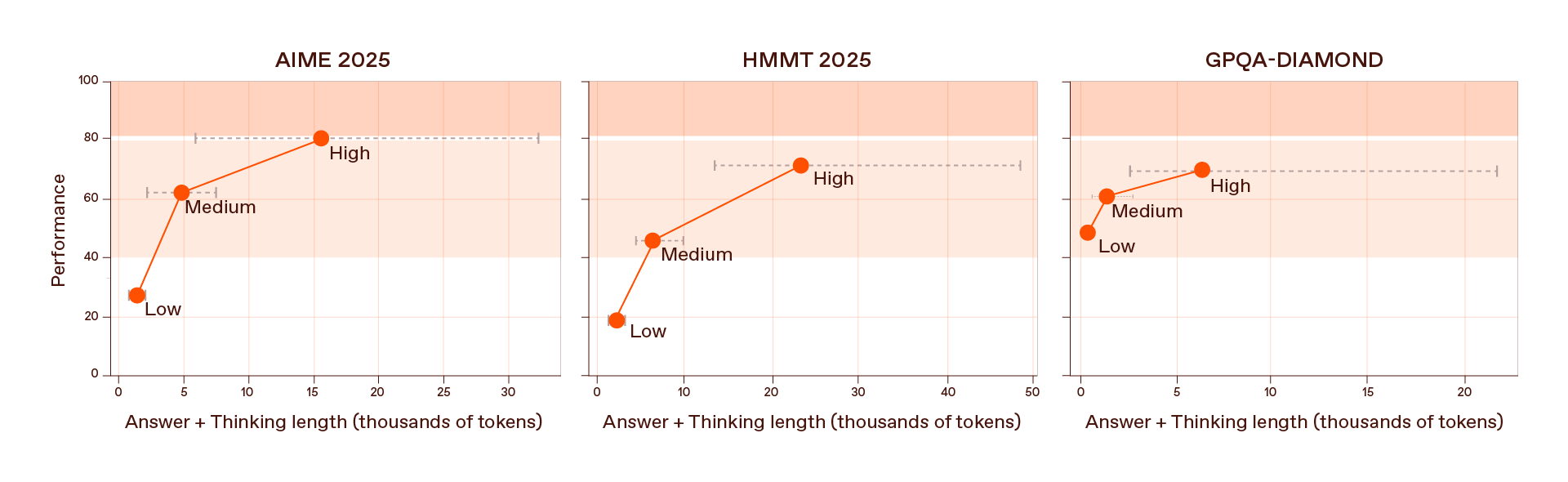
لكن مستويات الجهد الأقل مهمة بنفس القدر. فحتى مع بضع مئات إضافية من العناصر اللغوية المخصصة للاستدلال، يعزّز مستوى الجهد المنخفض جودة الإجابات بشكل ملحوظ، موفراً نمط استدلال فعالاً ومنخفض التكلفة للعديد من الاستخدامات الواقعية. أما مستوى الجهد المتوسط فيحقق توازناً بين الدقة والكفاءة في استخدام العناصر اللغوية، بينما يمثل مستوى الجهد العالي نمط التشغيل بأقصى طاقة للنموذج عند التعامل مع أصعب المسائل.
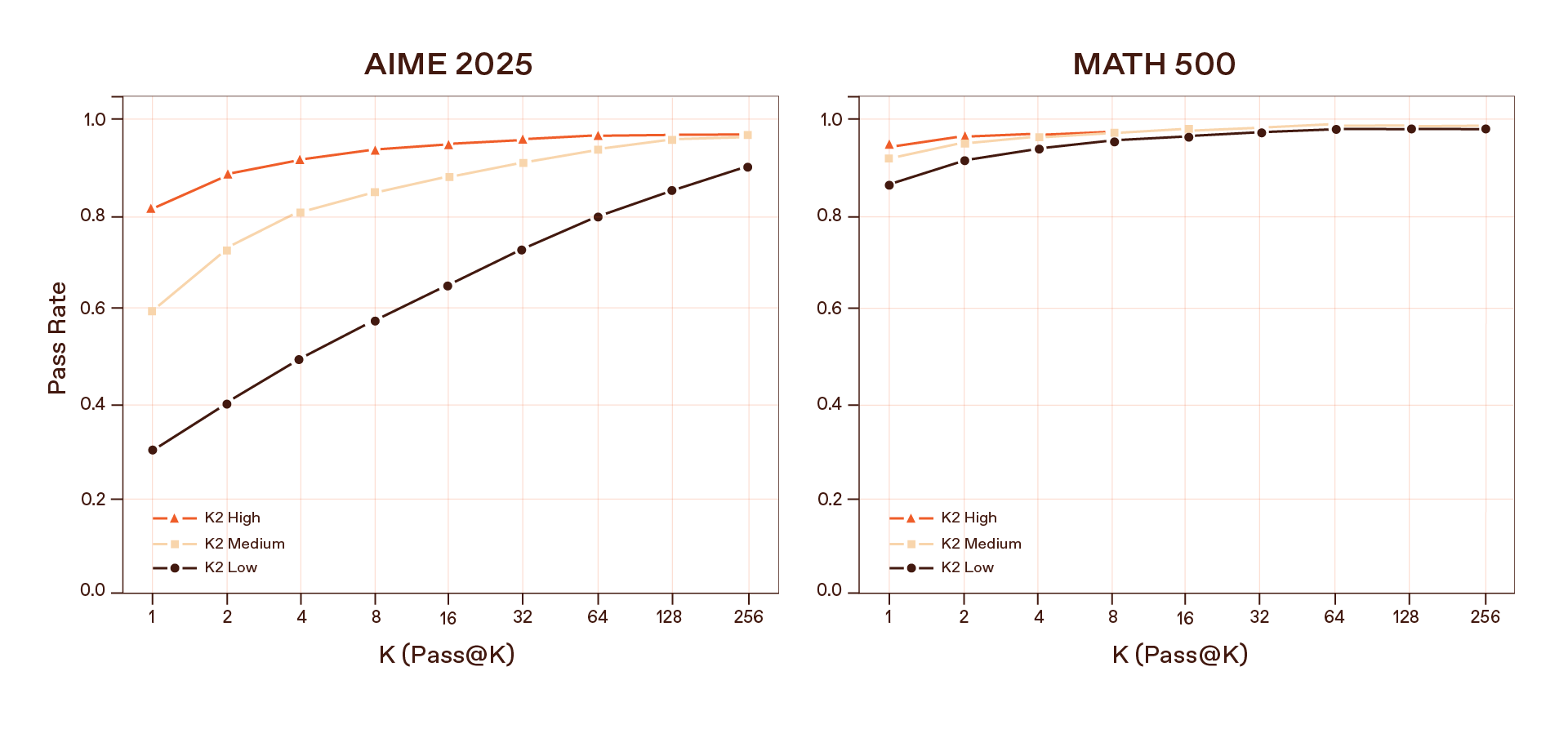
ويتسم تفسيرنا لهذه النتائج بنظرة استشرافية. فإذا كان مؤشر “Pass@k” يتحسن مع زيادة عدد مسارات الاستدلال المأخوذة في العينة، فهذا يعني أنه ما زال هناك مجال لتحسن النموذج عبر مواصلة التدريب باستخدام التعلّم التعزيزي. ويمكن عندها لخوارزميات التعلّم التعزيزي باستخدام مكافآت قابلة للتحقق فرز مسارات الاستدلال، ومكافأة الجيدة منها، ودفع القيم العددية نحو أنماط استدلال أكثر موثوقية.
ومن السمات المهمة الأخرى في النماذج الكبيرة الحديثة قدرتها على استخدام الأدوات، مثل واجهات البحث وتنفيذ التعليمات البرمجية وقواعد البيانات وغيرها. وقد جرى اختبار النموذج “K2” هنا باستخدام مجموعة البيانات المعيارية لاستدعاء الدوال من جامعة بيركلي (BFCL-v4)، التي تشمل استدعاءات أحادية واستدعاءات متعددة الخطوات، والبحث على الإنترنت، وإدارة الذاكرة، واكتشاف الاستدعاء.
على هذه المجموعة، حقق النموذج “K2-Medium” نتيجة إجمالية تقارب 52.4، متفوقاً على النموذجين “Qwen2.5-72B” و”Llama-3.3-70B” في مهام استدعاء الدوال. ويبرز تفوقه بشكل خاص في التفاعلات متعددة الخطوات، حيث يحتاج النموذج إلى الحفاظ على الحالة وملء المعاملات الناقصة في سلسلة من الرسائل المتبادلة، وكذلك في المهام التي تتطلب بنية دقيقة للاستدعاءات حيث تكون الدقة والتركيب أهم من الإبداع.
وتجدر الإشارة إلى نتيجة لافتة، حيث أظهر النموذج “K2” والنموذج المرجعي “GPT-OSS” أفضل أداء في مستوى الجهد المتوسط في مهام استخدام الأدوات. فرفع مستوى التفكير إلى الحد الأقصى قد يضر بالدقة، ربما لأن الاستدلال المطوّل يتداخل مع المخرجات الهيكلية المحكمة مثل استدعاءات “JSON”. وهذه النتيجة تذكّرنا بأن زيادة سلاسل الأفكار لا تعني بالضرورة نتائج أفضل دائماً، بل يجب مواءمة مستوى جهد الاستدلال مع طبيعة المهمة المطلوبة.
دراسة مراحل تطور النموذج وليس فقط نتيجته النهائية
أحد الأجزاء التي نفخر بها في هذا التقرير هو دراسة مراحل تطوّر النموذج “K2”. فقد سجلنا نقاط الحفظ وأجرينا عمليات تقييم معيارية في كل مرحلة، مما أتاح لنا تكوين صورة واضحة عن كيفية ظهور القدرات تدريجياً مع مرور الوقت.
على سبيل المثال، ترتفع دقة النموذج على مجموعة البيانات المعيارية “GSM8K” مع الانتقال إلى صيغ الاستدلال المنظّم ورفع سقف العناصر اللغوية. كما تسجّل اختبارات المنطق قفزات كبيرة في بداية بعض مراحل التدريب الوسيط، وهو ما نفسّره على أنه تحوّل في السلوك وليس مجرد تراكم للمعرفة، حيث يبدأ النموذج في تفضيل الاستجابات القائمة على التخطيط بعد تعرضه لعدد كافٍ من الأمثلة ضمن مجموعات بيانات التدريب الوسيط.
لكن “العناصر اللغوية الخاصة بالتفكير” لها جانب آخر أكثر حساسية، حيث يمكنها كشف أمور يحرص الجواب النهائي على إخفائها. ولهذا خصصنا قسماً كاملاً لتقييم السلامة ودراسة ما نسمّيه “التباعد بين التفكير والاستجابة”.
أخضعنا النموذج “K2” لما مجموعه 72 اختباراً للسلامة والمتانة في مواجهة الهجمات، بحيث تكونت العينة في كل اختبار من 200 أمر. بصورة عامة، أظهرت النتائج أن النموذج يقدم إجابات آمنة أو يرفض الإجابة بشكل مُبرر في نحو 86% من الحالات. وغالباً ما تتجاوز نسبة الأداء 95% في مجالات الكيمياء وعلم الأحياء والامتثال المالي والملكية الفكرية والإرشادات الطبية، إضافة إلى المواضيع الضارة للمجتمع مثل خطاب الكراهية والتطرّف والتعليمات الإجرامية.
كما قارنا سلوك النموذج “K2” بسابقه “K2 Think”، ولاحظنا فروقاً دقيقة لكنها مهمة. فالنموذج الجديد أكثر أماناً وأقل عرضة لكسر القيود بشكل عام، لكنه أحياناً يرفض الإجابة على كثير من الأسئلة المشروعة التي تبدو في ظاهرها خطرة مثل: “كيف أوقف تشغيل برنامج بلغة بايثون؟”. كما أنه ما زال عرضة لأنماط جديدة من محاولات كسر القيود، حاله في ذلك حال جميع النماذج الحديثة.
والخلاصة أن آليات السلامة الحالية تعمل في كثير من الأحيان كمرشّحات للمخرجات، لا كضوابط دلالية عميقة. فقد يتمكن النموذج من توليد تفكير غير آمن، ثم يتعلّم إخفاءه في الرسالة النهائية. وبالنسبة للنماذج ذات القيم العددية المفتوحة التي يمكن للمستخدمين ضبطها ودمجها وفحصها، يشكّل ذلك مكسباً من ناحية الشفافية، لكنه في الوقت نفسه تحدٍ إضافي من ناحية السلامة.
أهمية النموذج “K2“
على الورق، قد يبدو “K2” مجرد نموذج مفتوح آخر بحجم 70 مليار معامل يتنافس على مجموعات البيانات المعيارية الشائعة اليوم. لكنه في الواقع مشروع نادر من نوعه، فهو نموذج متقدم جرى تصميمه عمداً ليكون قابلاً للفحص والتوسيع والتطوير بشكل مفتوح.
بالنسبة للفرق المتخصصة في مجال الذكاء الاصطناعي، يوفر النموذج “K2” أساساً جاهزاً للاستدلال مع توثيق كامل لمراحل تطوره، ما يجعل تكييفه مع المجالات المتخصصة والتدريب المستمر أكثر قابلية للتنبؤ وأقل مخاطرة. أما بالنسبة للباحثين، فهو يقدّم منصة اختبار يمكن من خلالها دراسة قضايا تدريب سلاسل الأفكار، والاستدلال القائم على التعلّم التعزيزي، والتباعد بين التفكير والاستجابة، وآليات التعامل مع السياق الطويل، مع رؤية كاملة للبيانات ونقاط الحفظ التي شكّلت النموذج.
وعلى مستوى المنظومة الأوسع، يبرهن النموذج “K2” أن النماذج المفتوحة لا يجب أن تكون نسخاً أصغر وأضعف من النماذج المغلقة. فمن الممكن استهداف أحدث مستويات الأداء في الاستدلال والرياضيات والمنطق واستخدام الأدوات، وفي الوقت نفسه نشر الوصفة الكاملة والبيانات والدروس المستفادة من 1.5 مليون خطوة تدريبية.
تعرّف على الإصدار الجديد من النموذج “K2“: التقرير الفني | صفحة النموذج
أخبار ذات صلة

دراسة حديثة تكشف ثغرة جوهرية في أبرز أدوات التحقق من الصور المولدة بالذكاء الاصطناعي
فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي يطوّر تقنية تستطيع إزالة العلامات المائية المخفية داخل.....
- العلامات المائية المخفية ,
- العلامات المائية ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

كيف "تفكر" النماذج اللغوية الكبيرة؟
خريجة الماجستير تزينكسي وانغ تستكشف الميكانيزمات الداخلية التي تتحكم في طريقة معالجة النماذج اللغوية الكبيرة للغة وأساليب.....
- دفعة 2026 ,
- بنى منطقية ,
- بنى عاطفية ,
- بنى عصبية ,
- هيكليات داخلية ,
- حفل التخرج ,
- التفكير ,
- النماذج اللغوية الكبيرة ,
- الماجستير ,

إنجاز علمي يعيد تعريف فهم العلاقات السببية ويكشف ما تخفيه البيانات
كشف العلاقة السببية: دراسة حديثة تقدم خوارزمية متطورة لتحليل المتغيرات الكامنة وفهم العلاقات السببية المعقدة دون الاعتماد.....
- كشف العلاقة السببية ,
- تعلّم الآلة ,
- المؤتمرات ,
- البحوث ,
- ICLR ,