
لماذا ما زالت أنظمة الذكاء الاصطناعي اليوم عاجزة عن الاستدلال المكاني ثلاثي الأبعاد
الجمعة، 05 ديسمبر 2025

إذا طلبتَ من نموذج لغوي بصري أن يعثر على الكوب الأحمر في صورة، فسيؤدي المهمة بكفاءة. أما إذا قلت له: “أمسك الكوب الموجود في الجهة اليسرى وأنت تواجه السبورة البيضاء” فسيعجز عن ذلك. هذه الفجوة بين تسمية الأشياء وفهم مواقعها بالنسبة إلى الذات وبقية الأشياء المحيطة شكّلت موضوع ورقة بحثية جديدة أعدها باحثون من جامعة محمد بن زايد للذكاء الاصطناعي وقُدّمت في المؤتمر السنوي لنظم معالجة المعلومات العصبية 2025.
يقدّم الفريق البحثي، الذي يضم طالبَي الدكتوراة جياشين هوانغ وزيوين لي، والباحث المساعد هانلو تشانغ، مجموعة بيانات معيارية كبيرة تحمل اسم “SURPRISE3D” تُجبر النماذج على ربط اللغة بالهندسة الفعلية للمشاهد الداخلية ثلاثية الأبعاد. وتقترن هذه المجموعة بمهمة جديدة أطلقوا عليها اسم تقسيم الاستدلال المكاني ثلاثي الأبعاد (3D-SRS). وتتلخص النتيجة الرئيسية للدراسة في أنه حتى أقوى النماذج اللغوية البصرية المخصصة للبيئات ثلاثية الأبعاد تتعثر بشدة عندما تُسحب منها أسماء الفئات ويُطلب منها تنفيذ استدلال مكاني حقيقي.
كما قدّمت جياشين هوانغ ورقة بحثية أخرى في المؤتمر السنوي لنظم معالجة المعلومات العصبية بعنوان “MLLM-For3D“ تُعد عملاً مكمّلاً لمجموعة البيانات “SURPRISE3D”. فبينما تقدّم “SURPRISE3D” مجموعة البيانات المعيارية وتعريف المهمة، تستكشف الورقة البحثية “MLLM-For3D” كيفية تكييف النماذج اللغوية الكبيرة متعددة الوسائط ثنائية الأبعاد لأداء مهام تقسيم الاستدلال ثلاثي الأبعاد.
ورغم أن مصطلح “الاستدلال المكاني” قد يبدو تجريدياً، فإنه في الواقع يمثل جوهر ما تحتاجه أنظمة الذكاء الاصطناعي المتجسّد لكي تعمل في العالم الحقيقي، أي فهم عبارات مثل “الكرسي خلف الأريكة”، وتفسير التعليمات المتمركزة حول الذات مثل “على يمينك”، وتحديد أقرب أو أبعد عنصر بين عدة عناصر متشابهة.
تتحدث هوانغ عن موضوع الورقة البحثية قائلة: “أدركنا أن معظم مجموعات البيانات اللغوية البصرية المخصصة للبيئات ثلاثية الأبعاد تكافئ النماذج على حفظ أسماء الأشياء بدلاً من فهم العلاقات المكانية. ولإنشاء ذكاء اصطناعي متجسّد قادر على اتباع التعليمات البشرية الطبيعية، نحتاج إلى مجموعة بيانات تُجبر النماذج على الاستدلال حول الهندسة والمنظور والسياق المكاني، وليس فقط المفردات. فنحن نعيش في عالم مادي ثلاثي الأبعاد، والسؤال الجوهري هو: كيف يتفاعل البشر معه؟ لقد انطلق هذا البحث من رغبتنا في مساعدة أنظمة الذكاء الاصطناعي على تطوير الفهم المكاني الحدسي نفسه الذي يستخدمه البشر يومياً. وهدفنا من مجموعة البيانات المعيارية “SURPRISE3D” هو أن نساعد الآلات على بناء نماذج ذهنية للعالم ثلاثي الأبعاد بحيث تتمكن من الرؤية والاستدلال والتصرف بطريقة أقرب إلى البشر”.
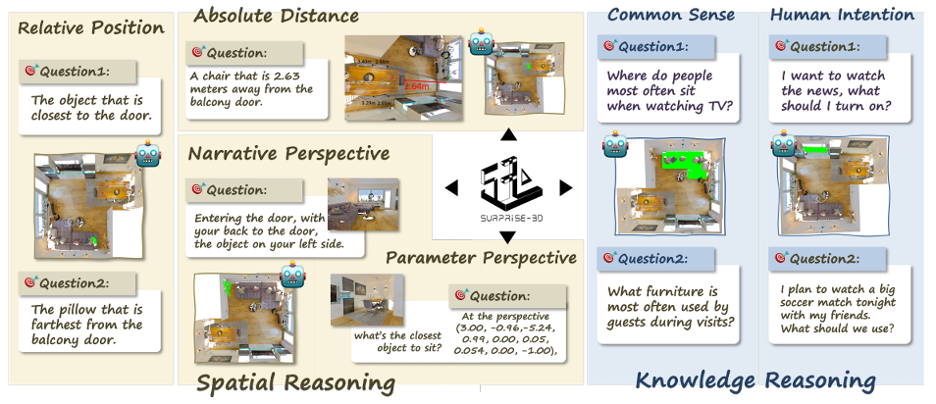
تعكس المجموعة المعيارية “SURPRISE3D” هذا التوجّه في منظومة التقييم منذ البداية. فهي تضم أكثر من 900 مشهد داخلي، وتوفّر ما يزيد على 200 ألف زوج من الاستعلامات اللغوية وأقنعة التقسيم ثلاثية الأبعاد، وتغطي أكثر من 2,800 فئة من العناصر. والأهم من ذلك أن أكثر من 89 ألف استعلام كُتبت يدوياً بواسطة البشر بحيث تتجنّب ذكر اسم الشيء المستهدف صراحةً حتى لا تتمكن النماذج من الاعتماد على الاختصارات السهلة. وبدلاً من ذلك، يتعيّن على النماذج تتبّع العلاقات المكانية، وفهم المنظور، وتقدير المسافة للعثور على الشيء الصحيح، وليس فقط الاعتماد على اسم الفئة. وتضيف المجموعة المعيارية كذلك 110 آلاف استعلام يتمحور حول المعرفة العامة والنوايا البشرية، مثل: “الشيء المستخدم للجلوس” أو “ما قد يمدّ الشخص يده لالتقاطه”. ومع ذلك، يبقى قلبها النابض هو حزمة مهام الاستدلال المكاني.
إزالة الطرق المختصرة ورفع سقف التحدي
ينطلق هذا العمل من نقد بسيط لكنه حاسم، وهو أن معظم مجموعات البيانات اللغوية البصرية المخصصة للبيئات ثلاثية الأبعاد تسمح للنماذج “بالفوز” عبر قراءة أسماء الأشياء فقط. وعندما تُستبدل هذه الأسماء بعبارات عامة مثل “شيء”، ينهار الأداء بشكل حاد، في دليل واضح على اعتماد النماذج على طرق مختصرة بدلاً من الفهم الحقيقي. ولهذا صُمّمت مجموعة البيانات “SURPRISE3D” بحيث تزيل عمداً هذه الطرق المختصرة وتنظم مهام الاستدلال المكاني ضمن أربع فئات رئيسية هي: الموقع النسبي (مثل “إلى يسار الخزانة” أو “خلف الأريكة”)، والمنظور السردي (تعليمات متمركزة حول ذاتٍ موصوفة داخل المشهد)، والمنظور البارامتري (تحديد وضعية الكاميرا رقمياً) والمسافة المطلقة (مثل “الأقرب” أو تحديد مسافة صريحة). ولا يقتصر الهدف هنا على رسم إطار تقريبي لموضع العنصر، بل يتطلب إنتاج قناع تقسيم كامل داخل المشهد ثلاثي الأبعاد، ما يفرض إسناداً دقيقاً للغاية. وإذا كانت الأوصاف تنطبق على عدة عناصر، فيجب أن يشملها القناع كلها. هذا الجمع بين لغة ضمنية، ووعي بالمنظور، وأقنعة دقيقة، يرفع سقف التقييم من “العنصر الصحيح تقريباً” إلى “العنصر الصحيح تماماً”.
ولتحويل هذا الإطار إلى معيار حي للمقارنة، يعرّف الباحثون مهمة تقسيم الاستدلال المكاني ثلاثي الأبعاد على النحو التالي: “عند إعطاء مشهد ثلاثي الأبعاد واستعلام لغوي، يتم تحديد قناع العنصر أو العناصر المشار إليها”. ويجري التقييم باستخدام متوسط التقاطع على الاتحاد ومؤشر “الدقة” عند عتبات التقاطع على الاتحاد، مع تقسيم النتائج حسب نوع الاستدلال لمعرفة مواضع تعثر النماذج. وتشمل النماذج الأساسية التي خضعت للاختبار عدداً من أبرز النماذج اللغوية البصرية المخصصة للبيئات ثلاثية الأبعاد (MLLM-For3D و3D-Vista وReason3D وIntent3D وChatScene) سواء في حالة عدم وجود تدريب مسبق أو بعد الضبط الدقيق على مجموعة البيانات المعيارية “SURPRISE3D”.
كانت النتائج متسقة في حالة عدم وجود تدريب مسبق، مما يؤكد أن الاستدلال المكاني هو المجال الذي تفشل فيه حتى أفضل النماذج الحالية. فقد بلغ معدل الدقة الإجمالية في جميع الطرق وأنواع المهام عند عتبة التقاطع على الاتحاد 0.25 نحو 8.3% فقط، وعند عتبة التقاطع على الاتحاد 0.50 نحو 5.2%. وكان الأداءً أفضل نسبياً، وإن ظل منخفضاً في أسئلة المعرفة العامة والنوايا البشرية، بينما سُجّل أسوأ أداء على الإطلاق في مهام المنظور السردي والمنظور البارامتري. وفي بعض المسارات الفرعية، تراجعت النتائج إلى ما يقارب الصفر بمجرد إزالة أسماء الأشياء. وهذا يفند بشكل قاطع الفكرة القائلة بأن النماذج الحالية المخصصة للبيئات ثلاثية الأبعاد اكتسبت “ذكاءً مكانياً” تلقائياً بفضل التوسّع الحجمي. فهذا الأمر لم يحدث، على الأقل ليس بطريقة تصمد عند إزالة الاختصارات السطحية.
أما الضبط الدقيق على مجموعة البيانات “SURPRISE3D” فقد أدى إلى تحسين الأداء، لكنه لم يحقق اختراقاً حاسماً. وظهرت أكبر المكاسب في الفئات “الأسهل” مثل الموقع النسبي، بينما ظلّ المنظور الذاتي والمسافة المطلقة أكثر الفئات هشاشة، حيث تواجه النماذج صعوبة في محاكاة وجهة نظر المتحدث أو المقارنة الدقيقة بين عدة عناصر ضمن المشهد.
ما الذي يجعل هذه الحالات شديدة الصعوبة؟ تبدو أنماط الإخفاق هنا شبيهة إلى حد كبير بما نراه في الروبوتات التي تقترب جداً من النجاح ولكنها تتعثر في اللحظة الأخيرة. في التعليمات القائمة على المنظور الذاتي، يجب على النموذج أن يربط مفهومي “اليسار” و”اليمين” بمنظور محدد داخل المشهد، وليس بمحور ثابت للغرفة. ولكن معظم بنى النماذج الحالية لا تتضمن آلية صريحة لتمثيل هذا الارتباط. أما في تقدير المسافة المطلقة، فيتعين على النماذج حصر جميع العناصر المرشحة ثم مقارنة المسافات ثلاثية الأبعاد أو التعامل مع صيغ التفضيل مثل “الأقرب إلى السرير”، وهو أمر يتطلب استدلالاً واعياً بالهندسة المكانية، وليس مجرد مطابقة نصية. وفي تحديد الموقع النسبي عند وجود حجب بصري، يجب على النماذج أن تستدل في فضاء حقيقي ثلاثي الأبعاد، وليس من خلال منظور واحد مُصوَّر فقط، كي تتمكن من تحديد “ما يقع خلف الأريكة” عندما يكون العنصر المستهدف محجوباً جزئياً. تتضمن مجموعة البيانات “SURPRISE3D” هذه التحديات الثلاثة في آن واحد، ولا تكافئ سوى الطرق التي تحدد العناصر الصحيحة بدقة تامة، وليس فقط فئة العنصر. والنتيجة هي منظومة تقييم تعاقب الاستدلال الفضفاض، وتكشف بوضوح أين ينتهي “الفهم اللغوي البصري” وأين يبدأ الذكاء المكاني الحقيقي.
تشير هوانغ إلى أن الفريق فوجئ بسرعة انهيار الأداء بمجرد إزالة أسماء العناصر. وتضيف قائلة: “حتى النماذج الكبيرة متعددة الوسائط التي تبدو قوية في الاختبارات التي تجري دون وجود تدريب مسبق فشلت تقريباً بالكامل في مهام الاستدلال المكاني، وأحياناً وصلت الدقة إلى ما يقارب الصفر. وخلال عملنا السابق على الورقة البحثية “MLLM-For3D” أدركنا أن النماذج اللغوية الكبيرة المخصصة للبيئات ثلاثية الأبعاد أو النماذج اللغوية البصرية الحالية تفتقر إلى قانون توسّع واضح، ويرجع ذلك بدرجة كبيرة إلى أن مجموعات البيانات القائمة لا تختبر الاستدلال المكاني. وفي الوقت نفسه وجدنا أن النماذج اللغوية الكبيرة والمتعددة الوسائط اليوم ما زالت تفتقر إلى القدرة الداخلية على الاستدلال المكاني. ولهذا قررنا الاعتماد على استعلامات يكتبها البشر في مجموعة البيانات المعيارية “SURPRISE3D” لترميز الفهم المكاني البشري بصورة صريحة وإزالة الاختصارات التي تستغلها النماذج عادة. وبهذه الطريقة تكشف مجموعة البيانات فجوات الاستدلال الحقيقية التي لا تستطيع النماذج الحالية إخفاءها عبر الحفظ”.
أهمية التغطية والإشراف
يضع المؤلفون مجموعة البيانات “SURPRISE3D” ضمن المشهد المزدحم لمجموعات البيانات المخصصة للبيئات ثلاثية الأبعاد، ويبيّنون لماذا تُعد التغطية الواسعة ومستويات الإشراف الدقيقة عاملين حاسمين. فبالمقارنة مع المجموعات الكلاسيكية مثل “ScanRefer” و”ReferIt3D”، التي تعتمد على فئات مسمّاة وصناديق ثلاثية الأبعاد، تدفع المجموعة “SURPRISE3D” نحو استعلامات خالية من أسماء العناصر ودقة على مستوى الأقنعة. وبالمقارنة مع المجموعات الأحدث مثل “ScanReason” و”Reason3D” و”Intent3D”، توسّع “SURPRISE3D” تصنيف أنماط الاستدلال، وتضيف معالجة منهجية للمنظور البصري كانت المجموعات السابقة تفتقر إليها. ويُظهر جدول المقارنة في الورقة البحثية نمطاً واضحاً، وهو أن معظم مجموعات البيانات تميل إلى الاعتماد على الأسماء الصريحة أو القوالب أو العلاقات السطحية، بينما صُممت المجموعة “SURPRISE3D” خصيصاً لكسر هذه العادات.
إذا كنت تعمل على تصميم نماذج لغوية مدركة للفضاء ثلاثي الأبعاد، فستحتاج إلى افتراضات متمركزة حول المنظور الذاتي، وترميزات واعية بوضعية الجسم، بحيث تُفهم عبارة “على يسارك” ضمن إطار مرجعي محدد لا عبر التخمين. وستحتاج أيضاً إلى آليات تجميع متعددة المناظير أو مدمجة في الفضاء ثلاثي الأبعاد للتعامل مع الحجب البصري وتغيّر زوايا الرؤية. وإلى جانب ذلك، ستحتاج إلى استدلال قائم على مجموعات العناصر، بدلاً من الافتراض بأن نموذج المحوّل يمكنه استنتاج الهندسة المترية من النص وحده. وتشير الورقة البحثية مباشرة إلى هذه الاتجاهات، مقترحة تضمين وضعيات ديناميكية واستدلالاً متعدد المناظير بوصفها حلولاً واعدة لمعالجة أسوأ أنماط الإخفاق التي تكشفها الدراسة.
أما من حيث الحدود، فمجموعة البيانات المعيارية تقتصر حالياً على البيئات الداخلية وترث نطاق “ScanNet++”. كما أن استعلامات المنظور البارامتري، رغم صرامتها، قد تبدو أقل طبيعية من الأوصاف البشرية المتمركزة حول الذات، فضلاً عن أن التصنيف البشري الذي يمنح الاستعلامات المكانية قوتها لا يمكن توسيعه بلا نهاية. ولكن قيمة مجموعة البيانات “SURPRISE3D” تكمن تحديداً في انضباطها المنهجي، حيث تستخدم لغة ضمنية واعية بالمنظور، وتتجنب عمداً ذكر أسماء الأشياء لمنع النماذج من استخدام الاختصارات، وتستخدم أقنعة دقيقة على مستوى التفاصيل، وتعتمد تصنيفاً للاستدلال يتطابق مباشرة مع ما تحتاجه الروبوتات وأنظمة الواقع المعزز فعلياً. وبوصفها أداة قياس للذكاء الاصطناعي المتجسد، فإنها أقرب بكثير إلى متطلبات العالم الحقيقي.
بفضل “SURPRISE3D”، أصبح لدينا أخيراً مجموعة بيانات معيارية تكافئ القدرات المطلوبة. فإذا كان من المفترض أن يتمكن المساعد الذكي من ترتيب مكتب، أو تجهيز طاولة، أو إعطاءك “المفك الموجود على يمينك”، فعليه أن يفهم الفضاء بالطريقة نفسها التي يفهمها البشر، أي عبر تثبيت الاتجاهات ضمن منظور محدد، والمقارنة بين الأشياء المتشابهة، وحلّ الالتباس اعتماداً على السياق، لا بالاعتماد على قاعدة بيانات لأسماء الأشياء. ومجموعة البيانات “SURPRISE3D” تجعل هذه المتطلبات صريحة، وتُبيّن بالأرقام أين يقف الذكاء الاصطناعي اليوم، وإلى أين يجب أن يتجه في المرحلة المقبلة.
لمن يرغب في متابعة هذا المشروع والاطلاع على تفاصيله، يمكن زيارة الروابط التالية:
أخبار ذات صلة

تطوير ذكاء اصطناعي يفهم التحديات المناخية في الخليج
طور فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي إطاراً جديداً يحمل اسم "المساعد الذكي للمناخ.....
- computer vision ,
- research ,
- climate change ,
- conference ,
- ACL ,

إريك مولين: بناء الأسس العلمية لعصر الذكاء الاصطناعي من قلب أبوظبي
إريك مولين، العميد المؤسس لقسم علوم الحوسبة والرياضيات في جامعة محمد بن زايد للذكاء الاصطناعي، يوضح كيف.....
- قسم علوم الحوسبة والرياضيات ,
- الحوسبة ,
- Dean ,
- computing ,
- البحث العلمي ,
- التعليم ,
- education ,
- الرياضيات ,
- mathematics ,
- عميد ,
- research ,

باحثون في جامعة محمد بن زايد للذكاء الاصطناعي يطورون إطاراً جديداً يعزز موثوقية النماذج متعددة الوسائط
باحثون من جامعة محمد بن زايد للذكاء الاصطناعي يكشفون عن إطار عمل جديد سيمكن النماذج متعددة الوسائط.....
- النماذج متعددة الوسائط ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,
- المؤتمرات ,