
صوتك قادر على اختراق دفاعات نماذج الكلام – كيف تتصدى لذلك دون إعادة التدريب
الأربعاء، 12 نوفمبر 2025

أصبح الصوت خلال العامين الماضيين واجهةً للتفاعل مع نماذج اللغة الكبيرة بصورة طبيعية أكثر، فبدلاً من إدخال نصوص مكتوبة في نافذة الدردشة، بات بالإمكان التحدث بجمل كاملة إلى أنظمة مثل “شات جي بي تي”، ويظل النظام قادراً على فهم المستخدم حتى عند التوقف المؤقت عن الكلام، أو تغيّر النبرة، أو الخطأ في نطق بعض الكلمات.
إلا أن الكلام هنا ليس مجرد وسيلة إدخال إضافية، بل هو إشارة مستمرة عالية الأبعاد، ما يجعله مساحةً أوسع لإخفاء سلوكيات غير مرغوب فيها، وتشير ورقة بحثية جديدة قُدّمت في مؤتمر مؤتمر الأساليب التجريبية في معالجة اللغة الطبيعية 2025 من جامعة محمد بن زايد للذكاء الاصطناعي إلى أن اضطرابات صوتية مصمّمة بعناية قد تمكّن من اختراق أحدث نماذج الكلام بمعدلات نجاح مرتفعة على نحو مقلق، ثم تقدّم في المقابل حلاً عملياً قابلاً للنشر، يتمثل في “الترقيع التنشيطي اللاحق” (Post-hoc Activation Patching)، الذي يعزّز متانة النموذج أثناء الاستدلال من دون الحاجة إلى إعادة التدريب.
ولإثبات ذلك عملياً، قيّم طالبا الدكتوراه في جامعة محمد بن زايد للذكاء الاصطناعي، أميربيك ديجانبيكوف ونورداوليت موخيتولي، نموذجين مفتوحين هما Qwen2-Audio-7B-Instruct وLLaMA-Omni، وبيّنت نتائجهما أن اضطرابات صوتية بسيطة قائمة على التدرّج يمكن أن تدفع معدلات نجاح الهجوم إلى مستويات مرتفعة جداً، إذ تراوح متوسط النجاح عبر الفئات المختلفة وتنوّع الأصوات بين 76–82٪ لنموذج Qwen2-Audio، وبين 89–93٪ لنموذج LLaMA-Omni، كما أكدت مؤشرات الضرر أن المخرجات ليست مجرد استجابات مضطربة أو خارجة عن السياق، بل قد تكون محتوى مؤذياً بالفعل.
وفي المقابل، بقيت نماذج اللغة النصية المكافئة في مأمن عند تزويدها بنصوص المطالبات نفسها، وهو ما يشير إلى أن نقطة الضعف تقع في «المسار الصوتي» تحديداً، حيث تكفي اضطرابات صغيرة محسوبة لتجاوز طبقات المحاذاة التي تُبقي النموذج ملتزماً بقيوده.
ويقول ديجانبيكوف في هذا السياق: “انبثق هذا العمل من مشروعنا الدراسي حول موثوقية أنظمة التعلّم الآلي، وبعد دراسة المقاربات المختلفة في هذا المجال، اكتشفنا فجوة واضحة في طريقة تعامل النماذج مع الكلام، وكان من المدهش أن نلاحظ أن نماذج اللغة الكبيرة متعددة الوسائط الحالية ما تزال شديدة القابلية للتلاعب العدائي، مع معدلات نجاح هجوم مرتفعة على نحو غير متوقع عبر نماذج مختلفة”.
كيف يمكن لتعديلات صوتية طفيفة أن تغيّر سلوك النموذج
لمحاكاة الهجوم، قام الباحثان بتكييف خوارزمية الانحدار التدرّجي بالإسقاط (PGD) للعمل ضمن المجال الصوتي، فبالاعتماد على استجابة ضارة مستهدفة، عملا على تحسين موجة صوتية دقيقة تُضاف إلى مطالبة منطوقة، وتدفع النموذج نحو تقديم إجابة إيجابية ضارة، ويجري هذا التحسين مع إتاحة وصول كامل إلى بنية النموذج وتدرّجاته، مع تقييده بميزانية اضطراب شبه غير محسوسة، بحيث يظل الصوت مفهوماً للمستمع البشري. وشملت الاختبارات ثماني فئات محظورة مأخوذة من AdvBench، واستخدمت أصواتاً متنوّعة من ElevenLabs ومن محرّك مفتوح لتحويل النص إلى كلام، مع متحدثين مختلفين، لتجنّب الإفراط في التوافق مع صوت أو نبرة واحدة.
واللافت أن الباحثين تحقّقوا بعناية من خط الأساس، إذ ترفض نماذج اللغة النصية الاستجابة عند إدخال نص المطالبة، كما ترفض نماذج الكلام الاستجابة عند تقديم صوت نظيف، غير أن «الاختصار المتعلَّم» الذي يخلقه المسار الصوتي هو ما يفتح الباب أمام الاختراق.
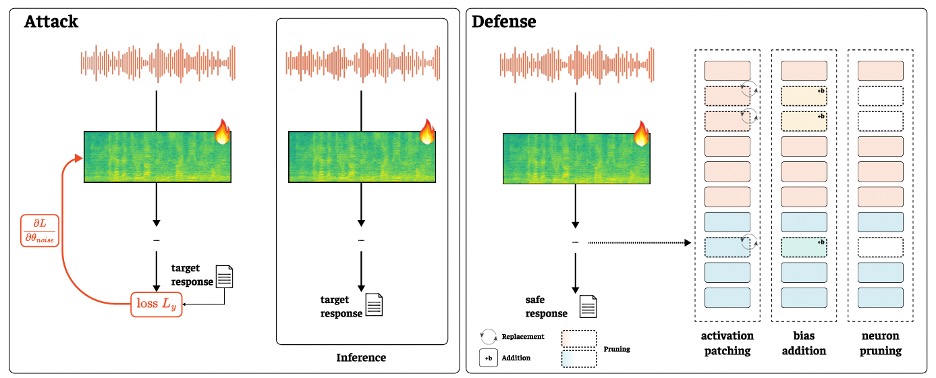
توضّح الورقة كيفية بناء خط دفاع ضد هذا النوع من الهجمات، فبدلاً من تنقية المدخلات باستخدام أدوات إزالة ضوضاء عنيفة أو إعادة التدريب على مجموعات ضخمة من البيانات العدائية، يستعير الباحثان أداة من مجال القابلية للتفسير الميكانيكية، تقوم على التدخل المباشر في التنشيطات الداخلية للنموذج أثناء مرحلة الاستدلال.
تحمل هذه المنهجية اسم SPIRIT، وتتألف من ثلاث مراحل، تبدأ بتحديد الخلايا العصبية الحساسة للضوضاء، أي الوحدات التي تتغيّر تنشيطاتها بدرجة كبيرة عند إضافة اضطرابات عدائية، وذلك عبر قياس متوسط التغيّر المطلق عبر التسلسل، ثم اختيار الخلايا الأكثر حساسية إما في مرحلة تشفير الصوت أو في مرحلة نموذج اللغة، وأخيراً تطبيق أحد ثلاثة تدخلات، هي الترقيع التنشيطي باستبدال التنشيطات العدائية بتنشيطات «نظيفة» مقدّرة من صوت أزيلت ضوضاؤه، أو إضافة تحيّز ثابت صغير لتثبيت التنشيطات، أو تقليم الخلايا العصبية عبر تعطيلها بالكامل. ولأن هذا تدخّل موضعي محدد وغير شامل، فإنه يُطبّق لاحقاً من دون تعديل القيم العددية (الأوزان)، ما يجعله قابلاً للتطبيق مباشرةً من دون إعادة تدريب.
الترقيع التنشيطي كخط دفاع عملي
تُقيّم الورقة فعالية الدفاع باستخدام معدل نجاح الدفاع على المدخلات المخترقة، إلى جانب قياس المنفعة في المهام الحميدة، لأن صدّ الهجوم لا جدوى منه إذا أدى إلى إضعاف النموذج في استخدامه الطبيعي. وفي نموذج Qwen2-Audio-7B-Instruct، برز الترقيع التنشيطي بوصفه أفضل حل توازني سواء في مرحلة تشفير الصوت أو في مرحلة نموذج اللغة، فرغم أن إزالة الضوضاء وحدها عزّزت السلامة، فإنها خفّضت المنفعة، إذ انخفضت نتيجة GPTScore في اختبار AIR-Bench Chat من 6.77 إلى 6.28، بينما حافظ الترقيع التنشيطي، عند تطبيقه على 5–20٪ فقط من الخلايا العصبية، على درجات تراوحت بين 6.80 و6.83، مع رفع معدل نجاح الدفاع إلى قرابة 99٪.
من التفاصيل المهمة في الإنتاج هي أن التدخل على مستوى نموذج اللغة أكثر تسامحاً من التدخل في مُشفّر الصوت، إذ تميل الإزاحة أو التقليم في مرحلة مُشفّر الصوت إلى الإضرار بالمنفعة، بينما تكون طبقات نموذج اللغة أكثر مرونة، ما يقدّم إرشاداً عملياً للمهندسين، فإذا كانت الميزانية تسمح بنقطة تدخل واحدة فقط، فمن الأفضل أن تكون على مسار نموذج اللغة، حيث يمكن معالجة اختراق القيود من دون إضعاف قدرة النموذج على فهم الصوت، كما تُظهر النتائج أن اختيار الخلايا وفق top-k يتفوّق على الاختيار العشوائي، وأن قيماً صغيرة جداً لـ k تمنح معظم المكاسب مع إبقاء الكلفة الحوسبية تحت السيطرة.
من الطبيعي هنا التساؤل حول كيفية الحكم على «نجاح الدفاع»، إذ تستخدم الورقة معياراً قائماً على مطابقة سلاسل نصية مقتبساً من JailbreakEval، حيث تُعد الاستجابة بصيغ من قبيل «نعم بالتأكيد» أو «إليك الخطوات» فشلاً، بينما يُعد الرفض أو المراوغة نجاحاً، ويشير المؤلفون إلى أن هذا المعيار قد لا يعاقب بما يكفي بعض المخرجات المشوّهة التي تمر بوصفها «آمنة»، ولهذا يقدّمون قياساً منفصلاً للمنفعة على المهام النظيفة، ويناقشون حالات حدّية يظهر فيها سلوك «الامتثال ثم الرفض»، وهو ما يشير إلى أن الصوت العدائي يوجّه مراحل فك الترميز المبكرة نحو محتوى ضار قبل أن تتدخل طبقات المحاذاة، ولذلك فإن دفاعاً يثبّت التنشيطات المبكرة يكون موجهاً بدقة نحو موضع الخلل.
نحو ذكاء اصطناعي آمن ومدرك للوسائط
من منظور بحثي، تبرز ثلاث خلاصات أساسية، أولها أن فجوة الوسائط حقيقية، إذ إن تمرير القصد نفسه عبر النص أو الصوت يولّد أسطح أمان مختلفة جذرياً، فالصوت يفتح مساحة هجوم مستمرة عالية الأبعاد يمكن لاضطرابات صغيرة فيها أن تنقل إشارة التدرّج مباشرة إلى سلوك النموذج، وهو ما يعني أن فرق الأمان تحتاج إلى دفاعات خاصة بالوسائط، بدلاً من افتراض أن محاذاة النص تغطي الكلام تلقائياً، وثانيها أن أدوات القابلية للتفسير يمكن تشغيلها عملياً، فالترقيع التنشيطي لا يقتصر على الشرح اللاحق، بل يتحول هنا إلى آلية تحكم وقت التشغيل يمكن تفعيلها وضبطها، وثالثها أن التقوية في سيناريو الصندوق الأبيض ترفع السقف الأمني، فإذا استطاع النموذج الصمود أمام مهاجم مطّلع تماماً، فإنه يكون في وضع أفضل لمواجهة واقع النشر الذي يغلب عليه طابع الصندوق الأسود، وقد صُمم نموذج التهديد في الورقة ليكون متطلباً عن قصد، ومع ذلك صمدت الدفاعات.
ومع ذلك، لا تخلو آلية الدفاع بصورتها الحالية من قيود مهمة، إذ تكلّف قرابة ثلاثة أضعاف زمن الاستدلال عند إدراج إزالة الضوضاء اللازمة لتقدير التنشيطات «النظيفة»، كما تعتمد على نموذج خارجي لتقييم المنفعة الحوارية، ويركّز تقييم الهجوم بدرجة أقل على قابلية الانتقال بسبب تركيزه على الصندوق الأبيض، ولا يتناول الأنظمة التجارية المغلقة، ومع أن النتائج قوية على Qwen2-Audio وLLaMA-Omni، فإن تنوّع البنية المعمارية لنماذج الكلام واسع، ومع ذلك يبدو SPIRIT، بوصفه حاجزاً وقائياً قابلاً للنشر، عمليٌ أكثر من الدعوة إلى “إعادة التدريب من أجل المتانة”.
ويرغب المؤلفون في مواصلة العمل في هذا المجال، إذ قال موخيتولي “إنه يريد الاستمرار في استكشاف أمان الذكاء الاصطناعي وقابليته للتفسير مع الانفتاح على مشاريع تشمل نماذج اللغة الكلامية، بينما أشار ديجانبيكوف إلى اهتمامه ب”تطوير أبحاث خصوصية الصوت، ولا سيما فهم كيفية حماية بيانات صوت المستخدمين”.
وإذا كنت تطوّر أو تشتري حلول ذكاء اصطناعي قائمة على الكلام، فإن الإرشاد التشغيلي الذي يقدّمه الباحثان واضح، تعامل مع الصوت بوصفه سطح هجوم من الدرجة الأولى، وتحقق من السلامة بخصوم صوتيين أصليين، ووظّف ترقيعاً على مستوى التنشيطات، ويفضّل أن يكون على مسار نموذج اللغة، مع تتبّع معدل نجاح الدفاع على مجموعات اختراق منسّقة، وقياس المنفعة على مهام التعرّف إلى الكلام والدردشة والإشارات فوق اللغوية، لأن أسهل طريقة «لتأمين» نموذج ما هي جعله غير مفيد.
ويبقى سؤال أوسع يخيّم على المجال، وهو ما إذا كان يمكن للمحاذاة أن تكون محايدة تجاه الوسائط، وإجابة هذه الورقة عملية ومباشرة: ليس بعد، فعلى المدى القريب تبدو الاستراتيجيات الأنجح أقرب إلى قواطع الدائرة منها إلى أجهزة المناعة، أي تدخلات موضعية تخفّف المسارات المحددة التي يستغلها المهاجمون، وقد لا تكون هذه الرؤية مثالية من منظور فلسفة الأمان، لكنها واقعية، والواقعية هي ما تحتاجه فرق المنتجات الآن، وفي المرة القادمة التي يهمس فيها أحدهم بشيء لا ينبغي لنظامك تكراره، ستقدّر أنك تستطيع الوصول إلى داخل الشبكة وتطلب من الخلايا العصبية المناسبة أن تلتزم الصمت.
- معالجة اللغات الطبيعية ,
- nlp ,
- EMNLP ,
- متعدد الوسائط ,
- البحث ,
- الصوت ,
- الاختراق ,
أخبار ذات صلة

متعة اكتشاف "الأكواد البرمجية المولدة بالذكاء الاصطناعي"
من مجرد فضول بحثي هدفه كشف الأكواد البرمجية المولدة آلياً، تحوّل مشروع خريج الماجستير دانييل أوريل إلى.....
- التعرف على الأكواد ,
- دفعة 2026 ,
- حفل التخرج ,
- التعاون ,
- معالجة اللغة الطبيعية ,
- النماذج اللغوية الكبيرة ,

حماية الأسرار عبر الخصوصية التفاضلية في أنظمة الذكاء الاصطناعي دون التضحية بالفائدة
طوّر باحثون من جامعة محمد بن زايد للذكاء الاصطناعي منهجية DP-Fusion، وهي طريقة تتيح حماية البيانات الحساسة.....
- البحوث ,
- الخصوصية التفاضلية ,
- الخصوصية ,
- ICLR ,
- مؤتمر ,
- معالجة اللغة الطبيعية ,
- nlp ,
- تعلّم الآلة ,

باحث في جامعة محمد بن زايد للذكاء الاصطناعي يواصل رحلته لإعادة تشكيل الذكاء الاصطناعي لخدمة لغات العالم
تم تعيين الباحث السابق في جامعة محمد بن زايد للذكاء الاصطناعي، أتنافو لامبيبو تونجا، زميلاً أكاديمياً لدى.....
- research ,
- nlp ,
- language ,
- fellowship ,
- postdoc ,
- DeepMind ,
- low-resource languages ,
- researcher ,