
مجموعة معيارية جديدة لقياس مدى فهم النماذج اللغوية للبديهيات الثقافية في العالم العربي
الأربعاء، 30 يوليو 2025

يشير فهم البديهيات إلى قدرة أنظمة الذكاء الاصطناعي، مثل النماذج اللغوية، على استيعاب مفاهيم بديهية بالنسبة للبشر. وقد شكّل هذا الموضوع تحدياً سعى الباحثون طويلاً لفهمه ومعالجته. على سبيل المثال، قبل بضع سنوات كانت أنظمة تحويل النصوص إلى صور تُنتج أحياناً صوراً لأشخاص لديهم أكثر من خمسة أصابع في كل يد. وبينما يُعد إدراك الروابط بين مفاهيم مثل الجوع والطعام، أو التعب والنوم، أمراً بديهياً بالنسبة للبشر، إلا أن الآلات لا تفهم هذه العلاقات بالبساطة نفسها.
غالباً ما نظر العاملون في مجال الذكاء الاصطناعي إلى فهم البديهيات على أنه أمر مشترك في التجربة الإنسانية، ولكن دراسة جديدة أعدّها باحثون من جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى توضح أن قدرات النماذج اللغوية في استيعاب البديهيات تختلف باختلاف الثقافات في العالم العربي.
يقول عبدالرحمن سعدالله، خريج برنامج الماجستير في معالجة اللغات الطبيعية بجامعة محمد بن زايد للذكاء الاصطناعي وأحد المشاركين في إعداد الدراسة: “تتجه أنظمة الذكاء الاصطناعي نحو التخصيص. وإذا أردتُ من النموذج أن يستجيب لي كفرد وكمصري، فهذا يعني أنني أتوقع منه أن يميز الاختلافات الدقيقة في ثقافتي”.
أنشأ سعدالله وزملاؤه مجموعة بيانات جديدة لقياس قدرات النماذج اللغوية في فهم البديهيات في ثقافات العالم العربي المتنوعة، وأُطلقوا عليها اسم “ArabCulture”. هذه المجموعة هي الأكبر من نوعها، وأنشأها ناطقون أصليون بالعربية. واستخدم الباحثون مجموعة البيانات الجديدة لاختبار 31 نموذجاً لغوياً، فوجدوا أن العديد منها لم ينجح في استيعاب المفاهيم الثقافية المختلفة في المنطقة.
قدّم الباحثون نتائج دراستهم في الاجتماع السنوي الثالث والستين لجمعية اللغويات الحاسوبية في فيينا. وقد شارك في إعداد الدراسة كل من جونيور سيدريك تونغا، وخالد المبارك، وسعيد المهيري، وفرح عاطف، وكاترين قويدر، وكريمة قضوي، وسارة شطناوي، وياسر عليش، وفجري كوتو.
بناء مجموعة بيانات جديدة وفريدة باللغة العربية
يوضح الباحثون في دراستهم أن التنوع الثقافي لا يؤثر في التفاعلات الاجتماعية بين الناس فحسب، بل يمتد أيضاً إلى طرق تفكيرهم وفهمهم لما يجري في العالم. ومعظم المجموعات المعيارية المستخدمة لاختبار فهم النماذج اللغوية للسياقات الثقافية لا تعكس هذا التنوع.
لذلك عمل سعدالله وزملاؤه على إنشاء مجموعة بيانات جديدة تركز تحديداً على المفاهيم الثقافية في العالم العربي. واستعانوا لهذا الغرض بأشخاص من 13 دولة عربية تمتد من شمال أفريقيا إلى منطقة الخليج العربي يتمتعون كلهم بفهم عميق لثقافاتهم المحلية.
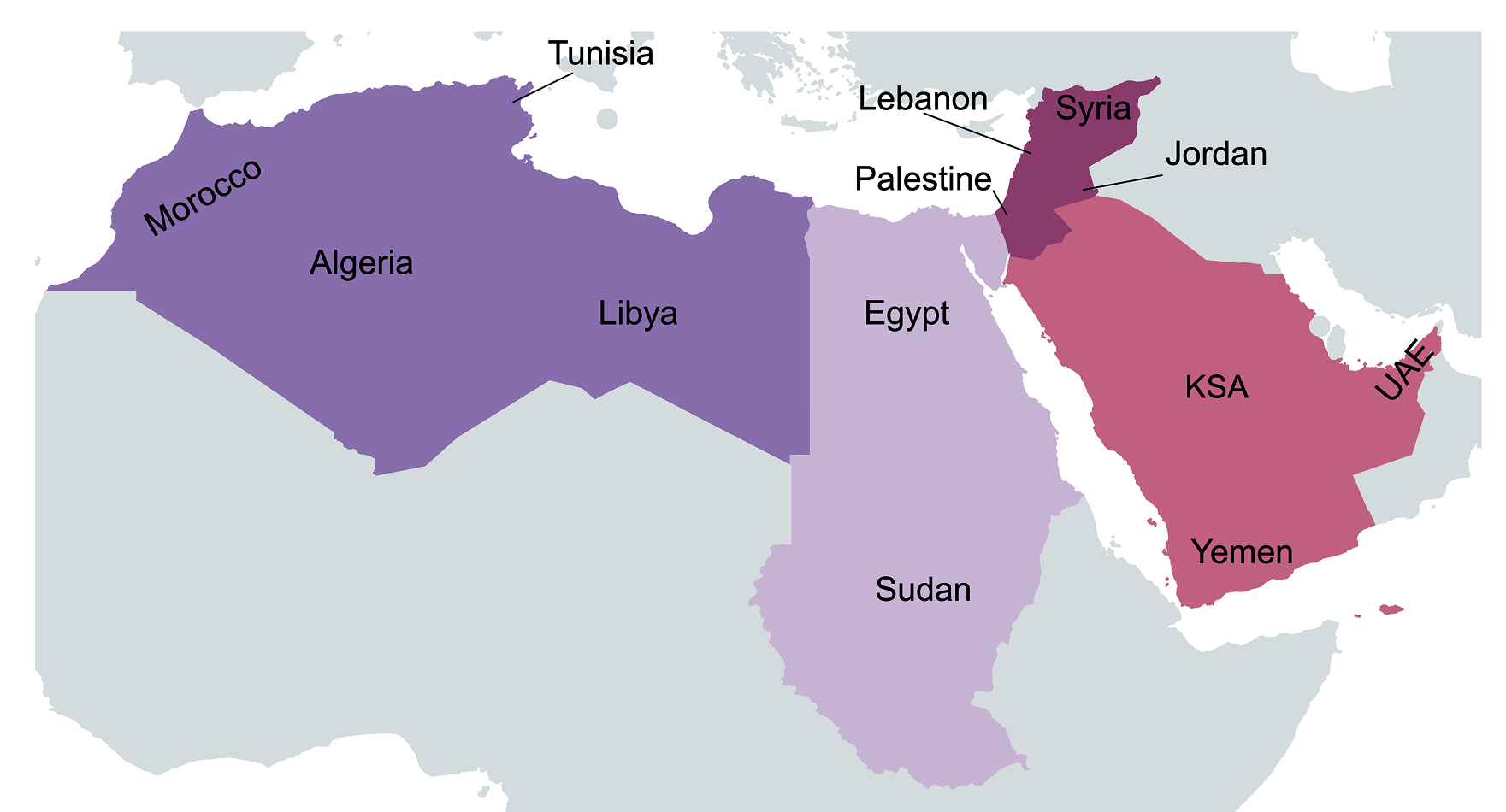
تغطي المجموعة الجديدة، التي أنشأها من الصفر ناطقون أصليون بالعربية، 13 دولة موزعة على أربع مناطق رئيسية (شمال أفريقيا ووادى النيل والمشرق العربي والخليج العربي).
يشير سعدالله إلى أن مجموعة البيانات الجديدة كُتِبت بالعربية الفصحى الحديثة، مضيفاً: “بُنيت هذه المجموعة من الصفر، وجاءت مباشرة من عقول المشاركين”. وهذا لأن بناء مجموعة بيانات من الصفر والحرص على إبقائها خارج الإنترنت يقلل من احتمال تسرّب البيانات، أي احتمال اختبار النموذج اللغوي على بيانات سبق له الاطلاع عليها، مما يجعل نتيجته في الاختبار أفضل من مستوى أدائه الحقيقي.
ويؤكد فجري كوتو، الأستاذ المساعد في معالجة اللغات الطبيعية بجامعة محمد بن زايد للذكاء الاصطناعي وأحد المشاركين في إعداد الدراسة، أن كان من الممكن ترجمة مجموعة بيانات من لغة إلى أخرى ومن ثم توطينها، أي تغيير أسماء الأشخاص والأشياء بما يتناسب مع الثقافة المستهدفة. ولكن هذا يضيع جزءاً مهماً من السياق الثقافي. وهو يضرب مثالاً على ذلك بقوله: “هل يُسمح بالجلوس على الأرض وتناول الطعام باليدين في حفل زفاف؟ قد يكون هذا مقبولاً في بعض الثقافات، وغير مقبول في ثقافات أخرى”.
تضم مجموعة البيانات “ArabCulture” نحو 3500 سؤال. يتكون كل سؤال من جملة يجب إتمامها باستخدام واحد من ثلاثة خيارات تبدو كلها سليمة من الناحيتين المنطقية والنحوية، لكن إجابة واحدة فقط هي الصحيحة لأنها تناسب ذلك السياق الثقافي المحدد. وتغطي هذه المجموعة 12 موضوعاً تتعلق بالحياة اليومية مثل الطعام وحفلات الزفاف والعلاقات الأسرية والزراعة، وتتفرع هذه الموضوعات إلى 54 موضوعاً فرعياً مرتبطاً بالثقافة العربية، بما في ذلك الإفطار والعادات المرتبطة بالدفن.
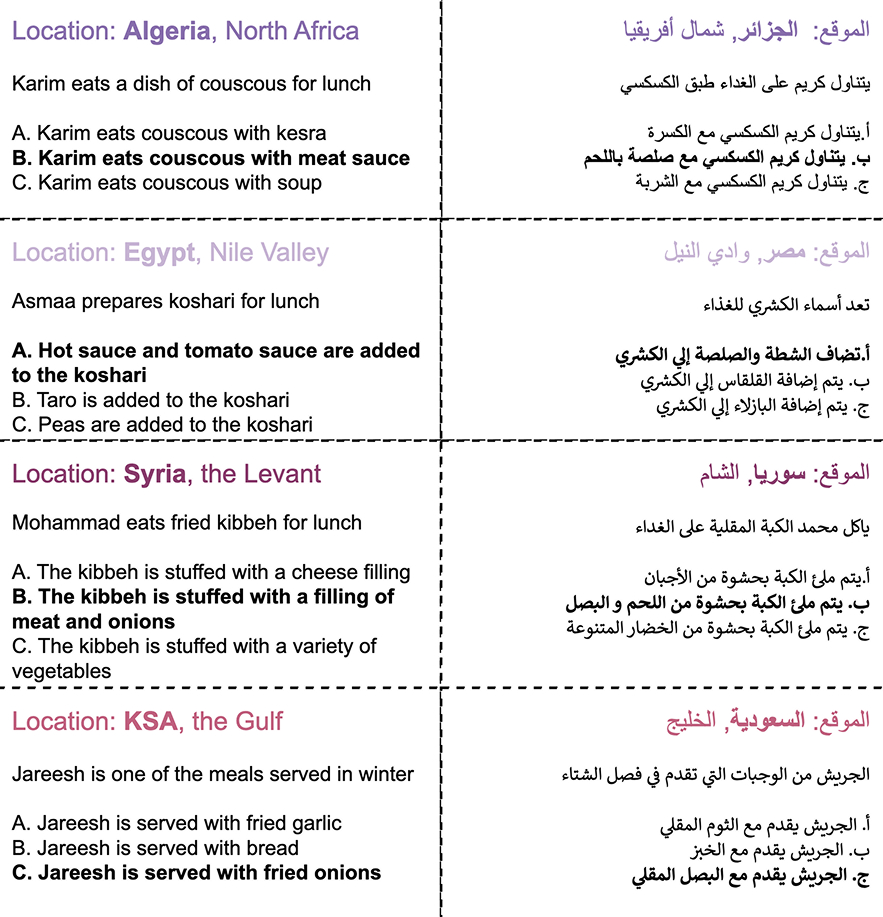
أمثلة لأسئلة متعددة الخيارات في فئة “الغداء” في مجموعة البيانات “ArabCulture”. تُعطى النماذج اللغوية جملة قصيرة، ثم يُطلب منها اختيار الجملة التي يجب أن تليها من بين ثلاثة خيارات. والإجابات الثلاث سليمة من الناحيتين المنطقية والنحوية، لكن واحدة منها فقط هي الصحيحة في ذلك السياق الثقافي المحدد.
ماذا تعرف النماذج اللغوية عن الثقافة العربية؟
اختبر الباحثون نماذج متعددة اللغات وأخرى مخصّصة للعربية فقط، بعضها مفتوحة المصدر وبعضها مغلقة المصدر. ورغم أن جميع الأسئلة كانت باللغة العربية، فقد قارن الباحثون بين أداء النماذج عند استخدام أوامر بالعربية وأخرى بالإنجليزية. كما اختبروها في نوعين من الأسئلة: إكمال الجمل، وأسئلة متعددة الخيارات.
سجّل النموذج المغلق المصدر “GPT-4o” أداءً أفضل من النماذج المفتوحة المصدر. ونظراً لكونه مغلق المصدر، فقد اختُبر فقط في الأسئلة المتعددة الخيارات. وعندما زُوّد هذا النموذج بالمنطقة والدولة التي يتعلق بها السؤال، أجاب بشكل صحيح عن 90% من الأسئلة. وجاء بعده النموذج “Qwen2.5-Instruct” بنسبة 80%، ثم النموذج “LLaMA-3.3-Instruct” بنسبة 79.6%.
وحققت النماذج متعددة اللغات أداءً أفضل من النماذج المخصّصة للغة العربية فقط، وهو أمر مفاجئ قليلاً. ولم يظهر أي ارتباط بين حجم النموذج ومستوى أدائه، مما يعني برأي الباحثين أن هناك عوامل أخرى تؤثر على الأداء، مثل بيانات التدريب المسبق وبنية النموذج.
كما تفوّقت بعض النماذج على غيرها في مجالات محددة. على سبيل المثال، حقق النموذج “GPT-4o” أفضل النتائج في موضوعات الزراعة والعلاقات الأسرية. بينما كان النموذج “AceGPT” الأفضل في المجالات المرتبطة بالموت والعبارات الاصطلاحية. وسجل النموذج “Qwen” نتائج متقدمة في موضوعات الزراعة والألعاب التقليدية.
وتأثر الأداء أيضاً بالمنطقة الجغرافية، حيث أجابت جميع النماذج على الأسئلة المتعلقة بالأردن بدقة عالية بلغت 90%، بينما تراجع الأداء في الأسئلة المتعلقة بالثقافتين اللبنانية والتونسية.
وأخيراً، سجلت النماذج أداءً أفضل عندما أُعطيت أوامر باللغة الإنجليزية، وهو أمر لوحظ سابقاً في دراسات أخرى. لكن سعدالله أوضح أنه كان مهتماً بملاحظة هذا الأمر في هذا السياق تحديداً.
بناء نماذج أكثر توافقاً مع الثقافة
يؤكد الباحثون أن نتائج دراستهم تُبرز الحاجة إلى تطوير النماذج اللغوية بحيث تصبح أكثر قدرة على فهم السياقات الثقافية العربية.
لكن كيف يمكن تحقيق ذلك؟
يقول سيدريك تونغا، الباحث المساعد في جامعة محمد بن زايد للذكاء الاصطناعي والمشارك في إعداد الدراسة، إنه يمكن تحسين الأداء عبر استخدام نموذج كبير لتزويد نموذج أصغر بالسياق الثقافي. وهناك أدلة تؤيد هذا التوجّه، حيث تحسن أداء النموذجين “Qwen” و “LLaMA” عند تزويدهما بمزيد من المعلومات عن الثقافات التي تناولتها الاختبارات.
أما كوتو فيقترح نهجاً آخر، وهو استخدام مجموعة بيانات مفضلة لإعطاء النموذج تعليمات إضافية تُحسّن من توافقه الثقافي في مرحلة ما بعد التدريب.
وأياً كان النهج المُتبع، يشدّد تونغا على ضرورة إعطاء الأولوية لتطوير أنظمة ذكاء اصطناعي متوافقة مع تنوع اللغات والثقافات في العالم، مضيفاً: “بما أن الجميع سيستخدمون الذكاء الاصطناعي، فيجب أن يكون قادراً على فهم ثقافاتهم كلها”.
وبينما كُتِبت مجموعة البيانات “ArabCulture” بالعربية الفصحى الحديثة، وهي اللغة المستخدمة في الإعلام والمؤسسات الحكومية والمراسلات الرسمية، يرى سعدالله وجوب بناء مجموعة (أو عدة مجموعات) بيانات أخرى تعكس تنوع اللهجات المحكية في العالم العربي، بحيث تُستخدم لتقييم النماذج اللغوية بدقة أعلى في المستقبل.
أخبار ذات صلة

كيف "تفكر" النماذج اللغوية الكبيرة؟
خريجة الماجستير تزينكسي وانغ تستكشف الميكانيزمات الداخلية التي تتحكم في طريقة معالجة النماذج اللغوية الكبيرة للغة وأساليب.....
- الماجستير ,
- النماذج اللغوية الكبيرة ,
- التفكير ,
- حفل التخرج ,
- دفعة 2026 ,
- هيكليات داخلية ,
- بنى عصبية ,
- بنى عاطفية ,
- بنى منطقية ,

متعة اكتشاف "الأكواد البرمجية المولدة بالذكاء الاصطناعي"
من مجرد فضول بحثي هدفه كشف الأكواد البرمجية المولدة آلياً، تحوّل مشروع خريج الماجستير دانييل أوريل إلى.....
- معالجة اللغة الطبيعية ,
- التعاون ,
- حفل التخرج ,
- دفعة 2026 ,
- التعرف على الأكواد ,
- النماذج اللغوية الكبيرة ,

حماية الأسرار عبر الخصوصية التفاضلية في أنظمة الذكاء الاصطناعي دون التضحية بالفائدة
طوّر باحثون من جامعة محمد بن زايد للذكاء الاصطناعي منهجية DP-Fusion، وهي طريقة تتيح حماية البيانات الحساسة.....
- تعلّم الآلة ,
- nlp ,
- البحوث ,
- معالجة اللغة الطبيعية ,
- مؤتمر ,
- ICLR ,
- الخصوصية ,
- الخصوصية التفاضلية ,