
تعزيز كفاءة تقنية الرؤية الحاسوبية باستخدام نماذج فضاء الحالة
الأربعاء، 11 يونيو 2025

على مدى أكثر من عقد من الزمن، هيمن على مجال الرؤية الحاسوبية نهجان قائمان على التعلم العميق؛ ففي عام 2012، طوّر باحثون في جامعة تورنتو شبكة عصبية ترشيحية تُعرف باسم “AlexNet” تفوقت بشكل كبير على الأنظمة الأخرى في مسابقة تصنيف الصور الشهيرة “ImageNet” – وبعد سنوات، ابتكر باحثون في شركة “جوجل” محول الرؤية الذي تم دمجه في العديد من أنظمة الرؤية الحاسوبية.
تتميز الشبكات العصبية الترشيحية بقدرتها العالية على تمييز العناصر في الصور مثل حواف الأجسام وبنيتها؛ أما محولات الرؤية – فتقسّم الصور إلى أجزاء صغيرة وتستخدم آلية تُعرف باسم “الانتباه الذاتي” لحساب العلاقات بين هذه الأجزاء، مما يمكّن النموذج من تحديد التوابع طويلة المدى في الصور. لكن تكلفة هذه القدرة مرتفعة لأنها تتضاعف بشكل تربيعي.
طوّر الباحثون مؤخراً نهجاً جديداً يُعرف باسم نموذج فضاء الحالة ويُعد واعداً من حيث قدرته على تقديم أداء أفضل من النهجين السابقين. وهو يماثل محولات الرؤية من حيث القدرة على تحديد التوابع طويلة المدى، لكن التكلفة تتضاعف بشكل خطي، مما يعني إمكانية تحسين الكفاءة بشكل كبير.
ولكن أحد القيود في نماذج فضاء الحالة هو أن عدد المعاملات فيها يتناسب طرداً مع عدد قنوات الإدخال، كما يوضح عبدالرحمن محمد شاكر، الحاصل حديثاً على درجة الدكتوراة في الرؤية الحاسوبية من جامعة محمد بن زايد للذكاء الاصطناعي. وفي بعض الحالات، تؤدي زيادة حجم هذه النماذج بهدف تحسين أدائها في مهام التعرّف البصري إلى نتائج عكسية، حيث يتراجع أداؤها بسبب صعوبة تحسين أداء النماذج الكبيرة.
لمعالجة هذه القيود، طوّر شاكر وزملاؤه من جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى مجموعة جديدة من نماذج فضاء الحالة أُطلق عليها اسم “GroupMamba” وصُمِّمت خصيصاً لتجاوز هذه التحديات. وفي اختبارات أُجريت باستخدام مجموعات بيانات معيارية، حققت هذه النماذج أداءً مماثلاً لنماذج فضاء الحالة الأخرى، ولكن بكفاءة أعلى بكثير.
يتحدث شاكر عن عمل فريقه قائلاً: “من خلال تحسين أداء نماذج فضاء الحالة، نأمل في الجمع بين قدرات النمذجة الشاملة التي تتميز بها المحولات البصرية وكفاءة الشبكات العصبية الترشيحية”.
شارك في إعداد الدراسة البحثية كل من سيد طلال وسيم، وسلمان خان، ويورغن غال، وفهد خان. ومن المقرر أن يعرض الفريق النماذج الجديدة في مؤتمر الرؤية الحاسوبية والتعرف على الأنماط الذي سيُعقد في مدينة ناشفيل بولاية تينيسي الأمريكية.
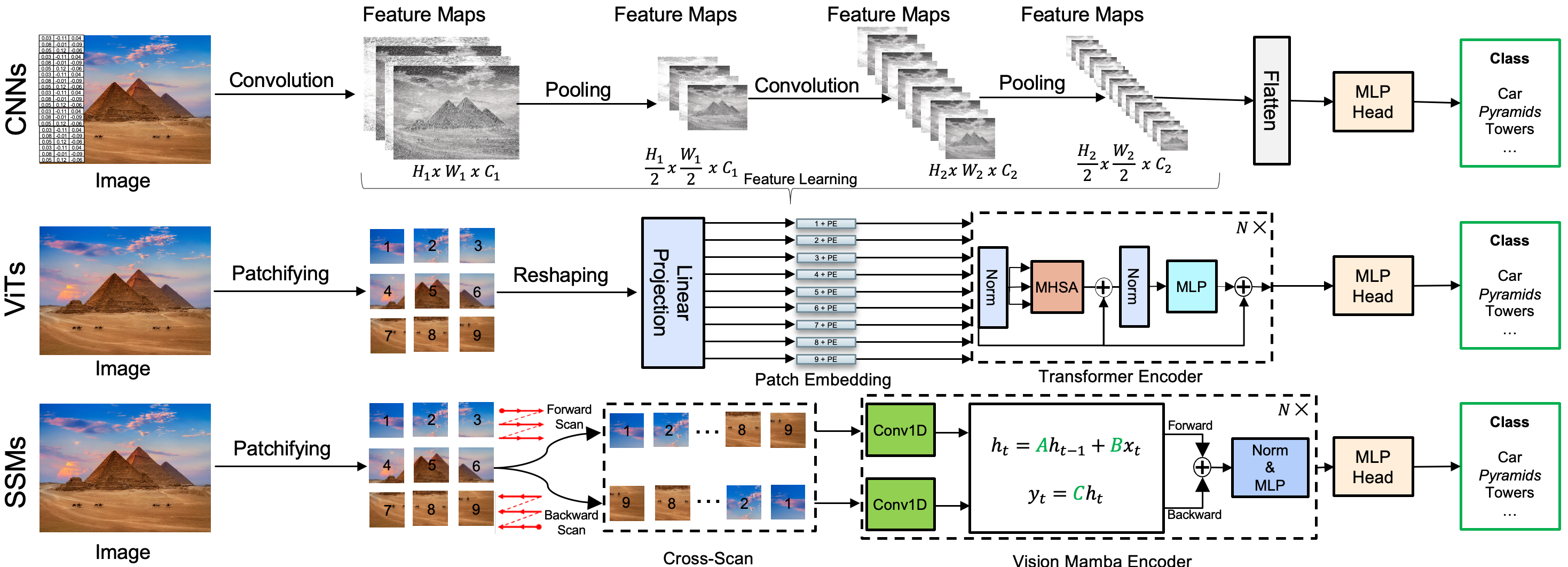
يبين الشكل تطور نماذج التعرّف البصري القائمة على التعلّم العميق، بدءاً من الشبكات العصبية الترشيحية، مروراً بالمحولات البصرية، وصولاً إلى نماذج فضاء الحالة.
تعزيز استقرار نماذج فضاء الحالة
يصف شاكر النموذج “GroupMamba” بأنه “نظام أساسي يمكن استخدامه في مهام مختلفة في مجال الرؤية الحاسوبية، مثل تصنيف الصور وتحديد الأجسام وتحليل الفئات والتمييز بين العناصر المختلفة”.
يقوم هذا النموذج على نموذج فضاء حالة آخر يُدعى “Mamba” طوّره باحثون في جامعتي كارنيجي ميلون وبرينستون. وقد أضاف إليه شاكر وزملاؤه طبقة جديدة لمعالجة تحديات الاستقرار والكفاءة الحسابية التي واجهتها أنواع أخرى من نماذج فضاء الحالة.
يقسّم النموذج “GroupMamba” عناصر الصور المدخلة إلى أربع فئات، ثم يمسحها في أربعة اتجاهات، مما يساعده على تحليل الأجزاء الصغيرة والصورة الكلية بكفاءة. ثم تُنقل نتائج المسح الأربعة إلى وحدات مسح بصري أحادي انتقائي تُحلّل الصورة من الاتجاهات الأربعة: من اليسار إلى اليمين، ومن اليمين إلى اليسار، ومن الأعلى إلى الأسفل، ومن الأسفل إلى الأعلى.
يقول شاكر موضحاً مزايا النموذج الجديد: “الفكرة الأساسية من تقسيم عناصر الصورة إلى أربع فئات ومسحها في اتجاهات مختلفة ثم دمج نتائج المسح هي تحليل الصورة بطريقة أكثر شمولية وكفاءة. فهذا يُقلل من التعقيد الحسابي، لا سيما عدد المعاملات، مقارنة بطبقة “Mamba” البصرية التقليدية”.
بعد ذلك أضاف الباحثون وحدة تعديل قنوات تُساعد النموذج في تنسيق المعلومات وتبادلها بين وحدات المسح البصري الأحادي الانتقائي الأربع بعد انتهاء المسح الفردي في كل منها، مما يُحسّن الربط بين عناصر الصورة.
كما صمم الباحثون طريقة تدريب تهدف إلى تحقيق الاستقرار أثناء تدريب النماذج الكبيرة. في هذه الطريقة يُستخدم نموذج سابق يُسمى بالمُعلم لتوجيه عملية تدريب النموذج الجديد، مما يساعد في منع تدهور أداء النموذج الجديد عند زيادة حجمه.
مقارنة أداء “GroupMamba” مع النماذج الأخرى
اختبر شاكر وزملاؤه نماذج “GroupMamba” التي طوّروها باستخدام مجموعات بيانات معيارية، وقارنوا بين أدائها وأداء نماذج أخرى تعتمد على الشبكات العصبية الترشيحية، والمحولات البصرية، ونماذج فضاء الحالة. أظهرت النتائج بشكل عام أن نماذجهم “تحقق قدراً أكبر من التوازن بين الدقة وعدد المعاملات” مقارنة بالنماذج الأخرى.
فقد حقق أحد أصغر نماذجهم، وهو “GroupMamba-T” (المعتمد على المسح باتجاه واحد)، أداءً مماثلاً لنموذج فضاء حالة آخر بالحجم نفسه هو “Vmamba-T V2” على مجموعة البيانات “ImageNet-1k”، لكنه عالج الصور بسرعة تقارب ضعف سرعة النموذج الآخر. كما تفوّق من حيث الدقة على نماذج مماثلة في الحجم تعتمد على الشبكات العصبية الترشيحية والمحولات البصرية.
وسجل الإصدار “GroupMamba-S” دقة بلغت 83.9% على مجموعة البيانات، متفوقاً بفارق طفيف على النموذج “LocalVMamba-S”، مع عدد معاملات أقل بنسبة 34%.
كما حقق الإصدار “GroupMamba-B” دقة بلغت 84.5% باستخدام 57 مليون معامل، متفوقاً على النموذج “VMamba-B” بنسبة 0.6%، مع عدد معاملات أقل بنسبة 36%.
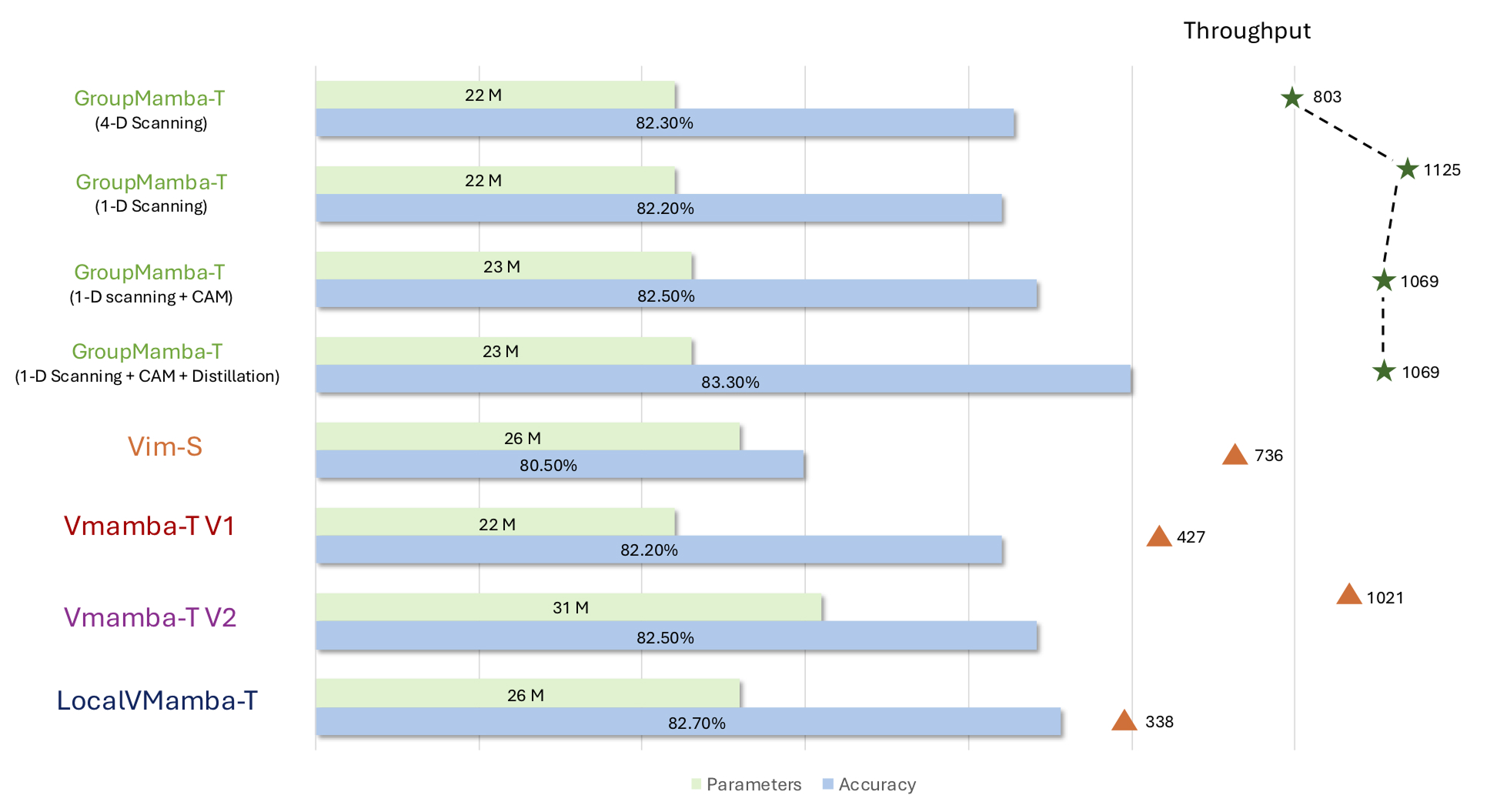
مقارنة بين إصدارات النموذج “GroupMamba” ونماذج فضاء الحالة الأخرى من حيث الدقة من المستوى الأول (باللون الأزرق) على مجموعة البيانات “ImageNet-1k” وحجم النماذج من حيث عدد المعاملات (باللون الأخضر). تشير قيمة الإنتاجية إلى عدد الصور التي تعالجها النماذج في الثانية باستخدام وحدة معالجة رسوميات واحدة من نوع “Nvidia A100”. وبلغ حجم الدفعة 128 صورة في جميع الطرق المستخدمة.
مستقبل نماذج فضاء الحالة
نظراً لقدرة نماذج فضاء الحالة على معالجة التوابع طويلة المدى بكفاءة عالية، يقول شاكر إن هناك إمكانات واعدة لاستخدامها في مجالات مثل التصوير الطبي وصور الأقمار الاصطناعية التي تُستخدم فيها بيانات ذات دقة عالية جداً (مثل الصور بدقة 4K و8K). ويضيف قائلاً: “غالباً ما تتجاوز هذه الصور قدرات المعالجة في المحولات البصرية التقليدية، لأن مستوى التعقيد في آلية الانتباه الذاتي يتضاعف بشكل تربيعي مع زيادة حجم البيانات المُدخلة. أما نماذج فضاء الحالة فيتضاعف مستوى التعقيد فيها بشكل خطي وتتسم بكفاءة أفضل في استخدام الذاكرة، مما يجعلها مناسبة لتحليل البيانات المكانية الضخمة دون أن التأثير على الدقة أو السياق”.
ويشير شاكر إلى إمكانية استخدام نماذج فضاء الحالة في مهام معالجة اللغات الطبيعية التي تتطلب تحليل كميات ضخمة من النصوص، تماماً كما استُخدمت المحولات في تطوير أنظمة الرؤية الحاسوبية والنماذج اللغوية الكبيرة، حيث يقول: “إذا أردنا معالجة كتاب كامل وليس مجرد مستند قصير، وكنا بحاجة إلى سياق أوسع، فإن نماذج فضاء الحالة قد تكون حلاً مناسباً بسبب قدرتها على التعامل بكفاءة مع مقاطع نصية طويلة جداً”.
يعتزم شاكر متابعة عمله على تطوير أساليب جديدة لتصميم أنظمة رؤية حاسوبية أكثر كفاءة في العام الدراسي القادم، حيث سيواصل أبحاثه ما بعد الدكتوراة في جامعة محمد بن زايد للذكاء الاصطناعي.
- المؤتمرات ,
- الرؤية الحاسوبية ,
- البحوث ,
- مجموعات البيانات ,
- الدكتوراه ,
- التعلم العميق ,
- التحسين ,
- CVPR ,
- نماذج فضاء الحالة ,
- مقياس الأداء ,
أخبار ذات صلة

تطوير ذكاء اصطناعي يفهم التحديات المناخية في الخليج
طور فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي إطاراً جديداً يحمل اسم "المساعد الذكي للمناخ.....
- ACL ,
- conference ,
- climate change ,
- computer vision ,
- research ,

باحثون في جامعة محمد بن زايد للذكاء الاصطناعي يطورون إطاراً جديداً يعزز موثوقية النماذج متعددة الوسائط
باحثون من جامعة محمد بن زايد للذكاء الاصطناعي يكشفون عن إطار عمل جديد سيمكن النماذج متعددة الوسائط.....
- المؤتمرات ,
- النماذج متعددة الوسائط ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

نموذجان أفضل من واحد لفهم الفيديوهات
نجح فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي في تطوير نهج مبتكر لفهم مقاطع الفيديو،.....
- الفيديو ,
- النماذج متعددة الوسائط الكبيرة ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- البحوث ,
- المؤتمرات ,