
مجموعة بيانات جديدة لتحسين أداء النماذج اللغوية الكبيرة متعددة الوسائط
الاثنين، 16 ديسمبر 2024

أحد الاستخدامات المهمة للنماذج اللغوية الكبيرة متعددة الوسائط التي تعالج الصور والنصوص معاً هو قدرتها على فهم وإنشاء التعليمات البرمجية لصفحات الإنترنت. وبينما تمتلك النماذج اللغوية الكبيرة المعروفة اليوم هذه القدرات بمستواها الأساسي، فهي بحاجة إلى تحسين لكي تحقق فوائد كبيرة من حيث الإنتاجية في مهام مثل تصميم وتطوير صفحات الإنترنت.
قام مؤخراً فريق من الباحثين من جامعة محمد بن زايد للذكاء الاصطناعي ومؤسسات أخرى بتطوير مجموعات بيانات يمكن استخدامها لقياس وتحسين أداء النماذج اللغوية الكبيرة متعددة الوسائط في تحليل صفحات الإنترنت وإنشاء التعليمات البرمجية بلغة HTML. ويتكون المشروع المسمى Web2Code من مجموعة بيانات جديدة لتحسين النماذج اللغوية الكبيرة ومجموعتي بيانات جديدتين لقياس أداء النماذج اللغوية الكبيرة.
استخدم الباحثون في دراستهم طريقة تسمى تحسين التعليمات لتعزيز أداء النماذج اللغوية الكبيرة متعددة الوسائط في إنشاء التعليمات البرمجية بلغة HTML والإجابة على أسئلة حول صور لصفحات على الإنترنت. ووجدوا أن تحسين هذه القدرات التخصصية لم يؤثر على أداء النماذج في المهام العامة.
وأوضح زهيكيانغ شين، الأستاذ المساعد في قسم تعلم الآلة بجامعة محمد بن زايد للذكاء الاصطناعي وأحد المشاركين في إعداد الدراسة، أن الفريق عمل على تطوير Web2Code بعد اختبار النماذج اللغوية الكبيرة مفتوحة المصدر وملاحظة أنها تفتقر إلى الفعالية في هذه المهام. وقد عُرِضت نتائج هذه الدراسة البحثية في المؤتمر السنوي الثامن والثلاثين لنظم معالجة المعلومات العصبية الذي عُقِد في فانكوفر.
مجموعة بيانات جديدة لتحسين التعليمات
تُدرّب النماذج اللغوية الكبيرة متعددة الوسائط على مجموعات ضخمة من البيانات بأشكال مختلفة، مثل الصور ومقاطع الفيديو والنصوص، وفي مجموعة واسعة من المواضيع. وفي الواقع، يُقال إن أكبر النماذج اللغوية الكبيرة وأشهرها، مثل GPT من شركة “أوبن أيه آي” وLLaMA من شركة “ميتا”، دُرِّبت على كامل شبكة الإنترنت المتاحة للجمهور، ما يمنح هذه النماذج قدرات عامة في معالجة الصور والنصوص وإنشائها.
بعد التدريب، يمكن تحسين النماذج مفتوحة المصدر لأداء مهام محددة من خلال طريقة تسمى تحسين التعليمات، حيث يُعطى النموذج مجموعة من الأسئلة أو التعليمات والإجابات المقابلة لها ويقوم بمعالجتها والربط بين الأسئلة والإجابات المطلوبة.
يوضح شين أنه بينما تتسم بيانات التدريب باتساع نطاقها، فإن البيانات المحددة المختارة لعملية التحسين مهمة جداً، حيث يقول: “يجب أن تكون جودة البيانات المستخدمة في مرحلة تحسين التعليمات أعلى من جودة البيانات المستخدمة في التدريب الأولي”.
يضم المشروع Web2Code مجموعة بيانات لتحسين التعليمات تتألف من أربعة مكونات، يرتبط اثنان منها بإنشاء التعليمات البرمجية بلغة HTML، بينما يتصل الاثنان الآخران بفهم صفحات الإنترنت. وهذه المكونات تقوم على مجموعات البيانات السابقة وتتضمن بيانات جديدة أنشأها شين وزملاؤه.
بالنسبة للمكون الأول، المسمى DWCG، استخدم الباحثون النموذج GPT-3.5 من شركة “أوبن أيه آي” لإنشاء 60 ألف صفحة إنترنت بلغة HTML وأداة تسمى Selenium WebDriver لإنشاء صور لهذه الصفحات. وتم تحويل هذه الأزواج من صفحات الإنترنت وصورها إلى تنسيق يمكن استخدامه لتحسين التعليمات.
بالنسبة للمكون الثاني، المسمى DWCGR، عدّل الباحثون مجموعتين قائمتين من بيانات إنشاء صفحات الإنترنت تسميان WebSight وPix2Code وحولوهما إلى تنسيق لتحسين التعليمات.
المكون الثالث، المسمى DWU، هو عبارة عن مجموعة بيانات جديدة مكونة من أسئلة وإجابات أنشأها شين وزملاؤه وتتكون من حوالي 250 ألف نقطة بيانات مصممة لتحسين قدرة النموذج على تفسير الأسئلة حول المعلومات التي تقدمها صفحات الإنترنت والإجابة عليها.
أما المكون الرابع، المسمى DWUR، فقد بناه الباحثون عن طريق استخدام النموذج GPT-4 من شركة “أوبن أيه آي” لتحسين مجموعة بيانات فهم صفحات الإنترنت المسماة WebSRC من خلال حذف الأجزاء المكررة في كل من مجموعة البيانات الأصلية وأسئلة تحسين التعليمات.
يقول شين في هذا الصدد: “في مجموعات البيانات القائمة، وجدنا أن بعض أوصاف النصوص كانت متدنية الجودة فقمنا بتحسينها. كما أنشأنا بأنفسنا بيانات جديدة أضفناها إلى مجموعة البيانات”.
مجموعات بيانات مرجعية جديدة
طوّر شين وزملاؤه مجموعتي بيانات مرجعيتين، الأولى لاختبار أداء النماذج اللغوية الكبيرة متعددة الوسائط في فهم صفحات الإنترنت، والثانية لاختبار أداء تلك النماذج في إنشاء تعليمات برمجية لصفحات الإنترنت.
تتكون مجموعة البيانات الأولى من حوالي ستة آلاف زوج من الأسئلة والإجابات التي أُنشِئت عبر تحليل لصور صفحات الإنترنت بواسطة GPT-4 Vision API. وقد أُخذت الصور من مجموعات أخرى، بما في ذلك WebSight، بينما أُخذت صور أخرى من الإنترنت. وهي منظمة على شكل إجابات “نعم” أو “لا”.

أمثلة على الأسئلة من مجموعة البيانات المرجعية لاختبار الأداء في فهم صفحات الإنترنت ضمن مجموعة Web2Code.
تستخدم مجموعة البيانات المرجعية الخاصة بإنشاء تعليمات برمجية لصفحات الإنترنت نفس الصور التي تستخدمها مجموعة البيانات المرجعية الخاصة بفهم صفحات الإنترنت، وهي مصممة لقياس قدرات النماذج على إنشاء التعليمات البرمجية لصفحات الإنترنت بالاعتماد على الصور. وباستخدام Selenium WebDriver، يحول الباحثون التعليمات البرمجية التي أنشأها النموذج إلى صورة، ما يسمح بنوع من المقارنة البصرية الدقيقة بين التعليمات البرمجية الناتجة والصور الأصلية. وتعتمد معايير تقييم التعليمات البرمجية لصفحات الإنترنت على أربع فئات: البنية البصرية والمحاذاة، واللون والتصميم الجمالي، وتناسق النص والمحتوى، وواجهة المستخدم وإمكانية التفاعل.
تحسين التعليمات وتقييم الأداء
قام الباحثون بتحسين أربعة نماذج لغوية كبيرة متعددة الوسائط مفتوحة المصدر باستخدام مجموعة بيانات تحسين التعليمات، ثم قيّموا النماذج، وهي LLaMA 3 وCrystalChat وCrystalCoder وVicuna، على مجموعتي بيانات مرجعيتين.
وأثناء عملية التحسين، طبقوا المكونات الأربعة لمجموعة بيانات تحسين التعليمات (وهي DWCG، DWCGR، DWU، DWUR) بشكل تدريجي حتى يتمكنوا من ملاحظة تأثير كل مكوِّن على الأداء.
في الغالب، تحسن أداء النموذج على معياري إنشاء تعليمات برمجية لصفحات الإنترنت وفهم صفحات الإنترنت مع تطبيق المزيد من مكونات مجموعة بيانات تحسين التعليمات. ولكن أداء الإصدار الأساسي للنموذج LLaMA 3 كان أفضل في معيار فهم صفحات الإنترنت من الإصدار الذي خضع لتحسين التعليمات باستخدام DWCG. ومن بين النماذج اللغوية الكبيرة متعددة الوسائط الأربعة التي جرى اختبارها، حقق نموذج LLaMA 3 من شركة “ميتا” أفضل أداء على المعيارين.
كما اختبر شين وزملاؤه إصدارات النماذج التي خضعت لتحسين التعليمات على مجموعات بيانات عامة. وقال شين إنهم فوجئوا بأن تحسين التعليمات حسّن أداء النماذج اللغوية الكبيرة في مهام محددة دون التأثير على أدائها العام، مضيفاً أنه: “ما زال من الممكن استخدام نموذجنا كنموذج لغوي كبير عام، حيث يمكن أن نسأله أي سؤال وسيجيب على جميع الأسئلة”.
تأثيرات المشروع Web2Code
أكد شين أن هذا المشروع يمثل تعاوناً مهماً بين علماء من تخصصات مختلفة، حيث شارك فيه باحثون في مجالات معالجة اللغة الطبيعية والرؤية الحاسوبية وتعلم الآلة.
وأشار الباحثون إلى الفوائد العملية لتحسين قدرة النماذج اللغوية الكبيرة متعددة الوسائط على إنشاء تعليمات برمجية بلغة HTML من الصور. وبينوا كيف استطاع نموذج CrystalChat الذي خضع لتحسين التعليمات إنشاء صفحة إنترنت من رسم خط بسيط. وهذا قد يكون مفيداً لمصممي ومطوري مواقع الإنترنت المهتمين بالتكرار السريع لتصاميم مواقع الإنترنت، أو لتمكين الأشخاص غير المدربين من بناء مواقعهم الإلكترونية من الصفر.
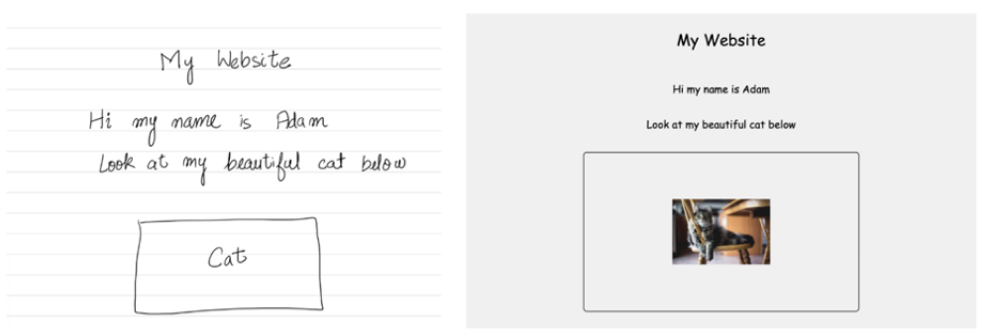
يوضح الباحثون كيف تمكن النموذج اللغوي الكبير CrystalChat من إنشاء تعليمات برمجية بلغة HTML لصفحة إنترنت بعد تحسين التعليمات باستخدام المجموعة الجديدة من البيانات المسماة Web2Code.
كما يشير شين إلى تطبيقات أخرى قائلاً: “بالنسبة للأشخاص الذين لا يستطيعون رؤية صفحة الإنترنت أو قد يواجهون صعوبة في قراءتها، بإمكان نموذجنا مساعدتهم في قراءة الصفحة وفهم محتواها”.
تتوفر مجموعات البيانات على الموقع الإلكتروني الخاص بالمشروع.
أخبار ذات صلة

إريك مولين: بناء الأسس العلمية لعصر الذكاء الاصطناعي من قلب أبوظبي
إريك مولين، العميد المؤسس لقسم علوم الحوسبة والرياضيات في جامعة محمد بن زايد للذكاء الاصطناعي، يوضح كيف.....
- البحث العلمي ,
- قسم علوم الحوسبة والرياضيات ,
- الحوسبة ,
- Dean ,
- computing ,
- التعليم ,
- education ,
- الرياضيات ,
- mathematics ,
- عميد ,
- research ,

دراسة حديثة تكشف ثغرة جوهرية في أبرز أدوات التحقق من الصور المولدة بالذكاء الاصطناعي
فريق بحثي من جامعة محمد بن زايد للذكاء الاصطناعي يطوّر تقنية تستطيع إزالة العلامات المائية المخفية داخل.....
- العلامات المائية المخفية ,
- العلامات المائية ,
- مؤتمر الرؤية الحاسوبية والتعرف على الأنماط ,
- CVPR ,
- الرؤية الحاسوبية ,

إنجاز علمي يعيد تعريف فهم العلاقات السببية ويكشف ما تخفيه البيانات
كشف العلاقة السببية: دراسة حديثة تقدم خوارزمية متطورة لتحليل المتغيرات الكامنة وفهم العلاقات السببية المعقدة دون الاعتماد.....
- تعلّم الآلة ,
- المؤتمرات ,
- البحوث ,
- كشف العلاقة السببية ,
- ICLR ,