
Two heads are faster than one
Thursday, June 04, 2026

Watch a person try to remember where they left their keys, and you can almost see the search happen. The eyes look around the kitchen, then return to the counter, then shift toward the coat rack. Remembering is not a single act of perception. It is a loop, with a fast scanner doing the looking and something slower behind the eyes deciding what to look at next.
A new paper presented by MBZUAI at CVPR 2026 introduces a system called SpecTemp, making the case that this is a good blueprint for video understanding too.
The current generation of large multimodal models, the ones that can watch a clip and answer questions about it, do not work this way. They take a video, slice it into many frames, and push the entire stack of resulting visual tokens through one large transformer that does both the looking and the thinking. The result is impressive, but it is also expensive, and the authors of SpecTemp argue that most of the expense is going to waste.
To prove this, they crack open one of the standard video models and look at how its language tokens (the ones doing the actual reasoning) attend to its visual tokens (the ones representing what the model saw). What they find is a distribution that is almost lopsided: roughly 90% of the visual tokens receive attention scores below one one-thousandth. The model is, in effect, paying real attention to a small fraction of what it is processing. The rest is computational ballast.
Researchers working on large language models have known for some time that not every token is doing equal work, and they have built an entire subfield called speculative decoding around the idea. The trick is to use a small, fast model to guess at the next several tokens, then use a large, slow model only to verify the guesses. Most of the time the small model is right, the verification is quick, and the big model never has to do the laborious step-by-step generation that defines its normal mode. When the small model is wrong, the big one steps in. The expensive intelligence is summoned only when needed.
SpecTemp takes this pattern and points it not at the generation of words but at the perception of video. In the authors’ setup, a large model with seven billion parameters is responsible for reasoning. It looks at a small set of uniformly sampled frames from a video, considers a question, and decides whether it has enough visual evidence to answer. If it does not, it identifies a stretch of the video that seems worth examining more closely and hands off to a smaller model with three billion parameters. The smaller model takes that stretch, samples it densely at one frame per second, and picks out the two or three frames it judges most informative. Those frames go back to the large model, which either generates an answer or asks for another round of investigation. The loop runs up to three times.
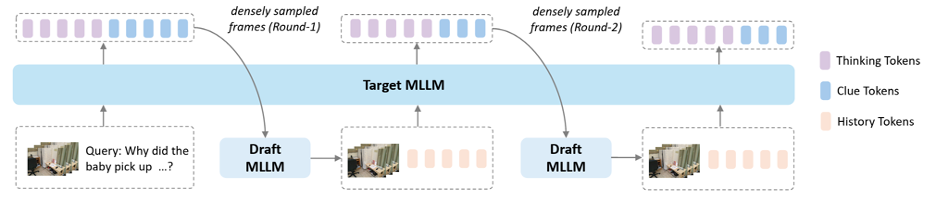
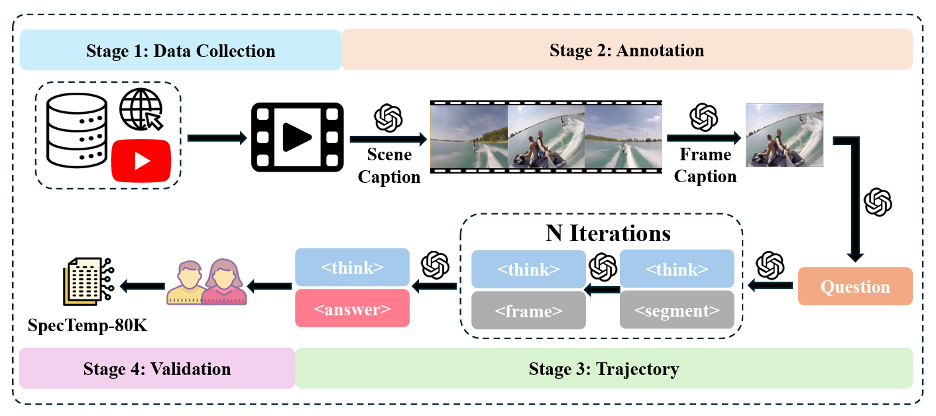
The result, on a battery of eight benchmarks spanning short clips to hour-long videos, is roughly a 20% reduction in inference latency with no loss in accuracy and, on several long-form tasks, modest improvements. The system is competitive with much larger baselines that process 64 frames in a single pass, while looking at fewer frames overall and reaching its answer through a more deliberate workflow. The training process is correspondingly elaborate, involving a custom dataset of 80,000 videos with paired annotations at two levels of detail, supervised fine-tuning of both models, and a reinforcement learning stage that teaches them to collaborate.
The dominant paradigm in video understanding has been to extend the context window, push more frames through the same model, and let scale handle the rest. SpecTemp’s authors are pushing in the other direction; they are arguing that perception and reasoning are different jobs, that they have different computational profiles, and that the way to get both right is to let a small specialist do the rapid scanning while a larger generalist does the slower work of figuring out what the scanning means.
The authors draw the analogy to a piece of recent neuroscience suggesting that human sensory processing operates along two parallel pathways, a fast one for rapid scene exploration and a slower one for integration and judgment. If most of the visual tokens in a video reasoning task are contributing almost nothing to the answer, then the rational response is to stop pushing them through the expensive model.
Training the system requires two models instead of one, and the reinforcement learning stage in particular is described as resource-intensive. The framework has been tested on videos up to about an hour. Performance on multi-hour content, where the number of possible temporal segments balloons, remains an open question.
So will the dual-model pattern generalize? Speculative decoding has become, in the language model world, something close to standard infrastructure. If the same idea proves to hold for perception, then the future of large multimodal systems may look less like a single enormous model that does everything and more like a small team of cooperating models with different jobs. A scout and a strategist, or a research assistant and an investigator, or a pair of brain pathways doing different kinds of work in parallel.
The picture the paper leaves is of a video model that has finally learned to look the way a person looks. Quickly at first, to take in the scene. Then more carefully, returning to the places where the answer might be hiding. The model is not smarter for working this way, exactly. It is just less wasteful about where it spends its attention. In a field where attention is literally the bottleneck, that turns out to matter.
- research ,
- conference ,
- video ,
- CVPR ,
- large multimodal model ,
Related

The watermark as combination lock
A new system developed by MBZUAI embeds unique, key-driven watermarks into AI-generated videos, making synthetic content more.....
- research ,
- computer vision ,
- security ,
- conference ,
- CVPR ,
- watermarks ,
From the world we see to the scans doctors read
MBZUAI researchers have developed a new approach that helps AI interpret complex medical scans without sacrificing the.....
- medical images ,
- medical ,
- CVPR ,
- conference ,
- computer vision ,

The watermark that wasn't there
A new technique from MBZUAI researchers removes AI image watermarks in seconds – exposing potential weaknesses in.....
- watermark ,
- watermarking ,
- CVPR ,
- computer vision ,