
The watermark as combination lock
Wednesday, June 03, 2026

Powerful generative AI models have made it trivial for any person to create synthetic videos that can be passed off as reality. Distinguishing between natural and synthetically generated videos is becoming challenging. This problem can be partially mitigated if responsible entities proactively apply watermarking to all videos generated using their models.
Most invisible watermarks work the way a stamp works. The system presses the same hidden mark into every image or video it produces, and a detector somewhere downstream knows what to look for. Since the mark is constant, the detector is built to find that constant under noise, compression, and the various other distortions that come with internet distribution.
A team at MBZUAI and Michigan State has been making the case that this is the wrong model. In a CVPR 2026 paper introducing a system called SPDMark, the authors argue that video watermarks should be built less like stamps and more like combination locks.
The watermark is not a fixed signal but a recipe. A short binary key selects, layer by layer, which of several learned adjustments to apply to a generative model’s decoder. Change the key, and you change the recipe. The watermark embedded in the resulting video is different in each case, even though the underlying machinery is the same.
Most of the field has spent the last two years trying to make one watermark hold up against the kinds of attacks images and videos endure on the way through a distribution pipeline. The implicit bet has been that if you can find a strong enough signal and a clever enough way to bury it, you can solve the provenance problem. SPDMark’s authors are making a different bet. They are arguing that the watermarking problem has been miscast as a signal hiding problem when it should be cast as a key management problem, and that the right way to design the system is to think about it the way cryptographers think about ciphers, with a shared procedure that takes different keys to different outputs.
The technical mechanism proposed by the team starts with a pretrained video diffusion model, the kind that turns text or an image into a sequence of frames. They leave the encoder and the denoiser frozen, the parts that do most of the heavy lifting. They focus only on the decoder, the final stage that turns latent representations back into pixels. To each of fourteen layers in that decoder they attach a small set of low-rank adapters, which are compact mathematical objects borrowed from the parameter-efficient fine-tuning literature. There are four such adapters per layer in their main configuration. During training, the team learns all of them at once, so that the decoder has a vocabulary of small adjustments it can mix and match.
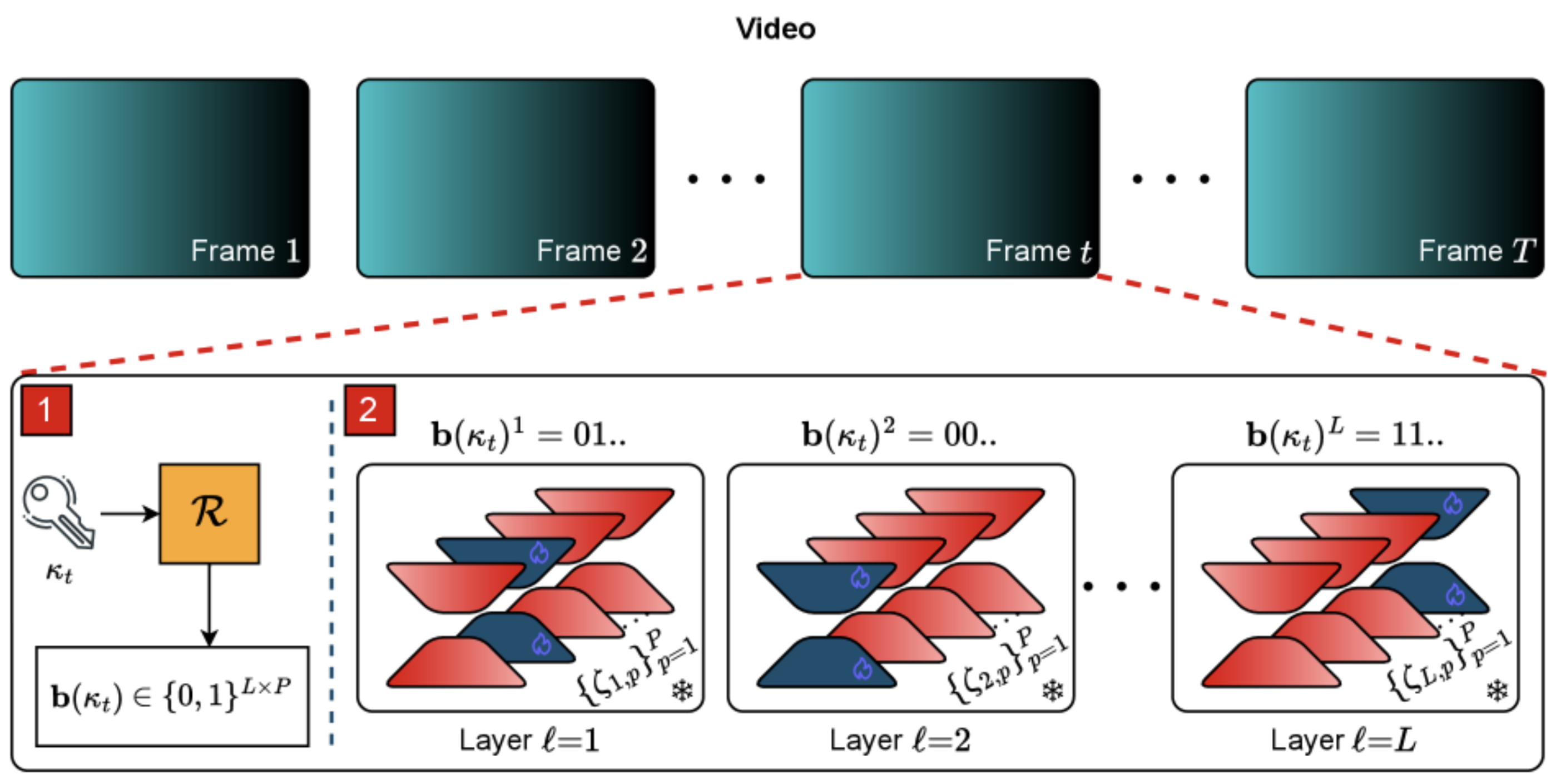
The watermarking key is then a sequence of two-bit instructions, one per layer, that picks which of the four adapters at that layer should be active for a given video. With 14 layers and four choices per layer, the system can encode 28 bits per frame, and across the frames of a video, a great deal more.
Because the key changes from frame to frame in a way derived from a cryptographic hash, the watermark is not just a per-video signature but a per-frame one. If someone drops frames, swaps them, or splices in new ones, the disturbance is visible to the detector in the same way that a misaligned tooth in a bicycle gear is visible to a rider. The authors use a classical algorithm from operations research, the Hungarian method, to figure out which surviving frames map to which positions in the original sequence, and then they run a statistical test to decide whether enough of the matches are real for the video to count as watermarked.
Across two video diffusion architectures and 16 kinds of degradation, including the usual suspects of compression and blur and the more interesting cases of frame reordering and inpainting, the system holds up at roughly 94% bit accuracy on average. It edges out the closest comparison points in the literature on geometric attacks and on temporal ones, while staying within a few percentage points on most others. The video quality metrics show no real degradation from the embedding process, which means viewers cannot see the watermark even when looking for it. Training the whole thing takes about eight GPU hours on a single A6000, which is modest by current standards.
What makes the design appealing from a deployment perspective is that one trained system supports many keys without retraining. A company shipping a video generator could use a different combination at the layer level for every customer, or every region, or every legal jurisdiction, and the underlying model would not change. This is closer to how authentication works in software systems generally. The trained dictionary of adapters is the public infrastructure while the key is the secret. The authors argue, fairly, that this is what watermarking ought to look like at industrial scale.
Most of the attacks the team tests are passive distortions of the kind a video would encounter naturally, and the system handles those well. A more interesting case is included in the supplementary material though. When an attacker fine-tunes the decoder itself while leaving the learned adapter dictionary frozen, watermark extraction collapses to about 65% accuracy, which is barely better than guessing.

This is the right thing to disclose, and it sits inside a broader picture for the watermarking community. The same research environment that produced SPDMark has also produced recent attacks suggesting that invisible watermarks in images may be vulnerable to entire classes of transformations that the defenses were not designed to handle. Video adds temporal coherence as a new axis to defend, and SPDMark’s per-frame keying is a genuine advance on that axis. But the field is moving fast, and a defense that holds against today’s standard attack suite is not the same as a defense that holds against tomorrow’s adaptive adversary.
By recasting watermarking as a key-indexed selection from a shared vocabulary, the authors open a path toward watermarks that can be revoked, rotated, and customized at deployment time, the way cryptographic keys can be.
For now, the watermark, in this design, is finally something more than a digital tattoo; it becomes a credential.
- research ,
- computer vision ,
- security ,
- conference ,
- CVPR ,
- watermarks ,
Related
From the world we see to the scans doctors read
MBZUAI researchers have developed a new approach that helps AI interpret complex medical scans without sacrificing the.....
- medical images ,
- medical ,
- CVPR ,
- conference ,
- computer vision ,

The watermark that wasn't there
A new technique from MBZUAI researchers removes AI image watermarks in seconds – exposing potential weaknesses in.....
- computer vision ,
- watermark ,
- watermarking ,
- CVPR ,

Commencement 2026: Why Ahmed Alshamsi sees field experts and youth as the real builders of the future
MBZUAI computer vision graduate and Y71 founder believes AI's greatest value emerges when domain experts, students, and.....
- Commencement 2026 ,
- cybersecurity ,
- computer vision ,
- entrepreneur ,
- startup ,
- youth ,
- M.Sc. ,
- master's ,
- commencement ,