
From the world we see to the scans doctors read
Tuesday, June 02, 2026
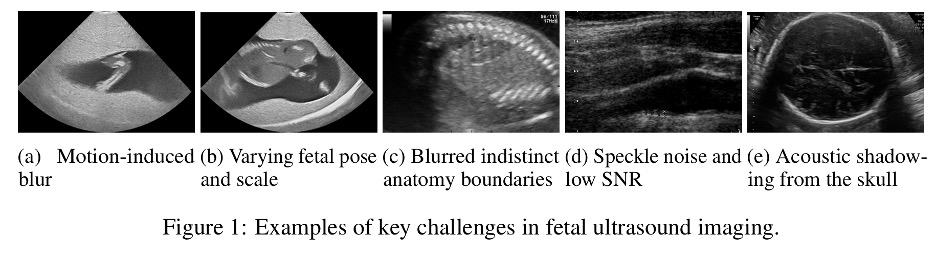
The first thing a fetal ultrasound technician sees on the screen is rarely the clean line drawing that appears in textbooks. It is a smear of grayscale noise crossed with acoustic shadows from the developing skull, the contours of a small body half-emerging from speckle, a pose that shifts when the mother moves.
Reading these images well is a skill that takes years. And building an AI model that reads them well – without making that model worse at every other kind of ‘seeing’ – has been a quiet headache in computer vision for nearly a decade.
A new highlight paper presented at CVPR 2026 by a team of MBZUAI researchers introduces an architecture called DCRM-ViT which proposes a way to address some of these issues. The work targets a familiar challenge: fine-tune a powerful vision model on medical scans and it tends to forget how to read images of dogs and cars. But train it broadly, and it stumbles on the artifacts that define real clinical data. The trade-off has shaped the field, encouraging two parallel ecosystems of models that rarely meet in the same deployment.
Lead author, Ufaq Khan supervised by Muhammad Haris Khan, Assistant Professor of Computer Vision at MBZUAI, and another Ph.D. student Umair Nawaz, argue that there is a way to avoid this binary choice. The variation between a brain MRI, an ultrasound of a fetal abdomen, and a snapshot of a plate of food is continuous, they note, rather than categorical. If that is true, then the way to handle the difference should also be continuous: small, per-image corrections rather than wholesale retraining.
Khan and the team take a pretrained Vision Transformer and leaves it frozen. The original weights, which carry the broad visual competence the model picked up from millions of natural images, are never updated. Instead, the team attaches a thin layer of new machinery that looks at each incoming image and decides how to nudge the network’s calculations. They call this layer the Domain Router. It assigns soft probabilities to whether an image is medical or natural in character, and feeds those probabilities into a small Parameter Synthesizer Network that generates low-rank adjustments on the fly. These adjustments slot into specific points inside each transformer block, modulating the way the model weighs features without rewriting the underlying weights.
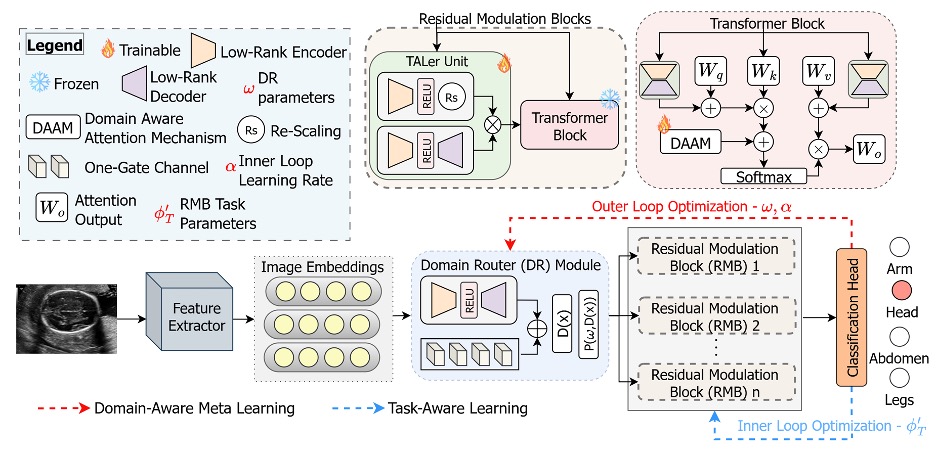
The effect is something like adding a dimmer switch where there used to be only a hard toggle. An image that sits halfway between a clean photograph and a noisy ultrasound, a heavily processed mammogram for instance, can receive a halfway treatment. The authors call the adjustments residual modulation, and the blocks that apply them sit inside each transformer layer, lightweight enough to keep training cost modest.
To train this routing system, the researchers borrow a technique called bi-level optimization, familiar from meta-learning research, in which two nested loops do different jobs. The inner loop quickly adapts the residual blocks to a specific task, such as classifying a fetal head versus a fetal abdomen. The outer loop pulls back and updates the router itself, along with the initial state of the residual blocks, using examples chosen to teach the network what each domain feels like. As the authors put it, the two objectives can drown each other out if optimized together. The router needs to learn the shape of the world. The residual blocks need to learn the shape of the task. Training them in lockstep through a single gradient tends to produce a model that does neither well.
The results, reported across a mix of medical and consumer datasets, are competitive. On fetal ultrasound classification, DCRM-ViT reaches 63.4% accuracy on the FPUS23 dataset and 89.3% on the Fetal Planes benchmark, edging past strong baselines including CLIP, DINOv2, and LoRA. On natural image benchmarks like Food101 and Stanford Cars, it matches or slightly improves on specialist methods. On segmentation, where the clinical payoff is often largest, it shows a roughly three-point Dice score gain over SAMUS, a recent ultrasound-focused model, across breast ultrasound datasets. The cardiac CT and MRI results sit a couple of points above the strongest comparison points.
Interestingly, the authors report only 3.3 million trainable parameters on top of a roughly 87-million parameter backbone, with training time of about 0.3 minutes per epoch on a single A100 GPU. That is materially lower than full fine-tuning of foundation models, and it points to the broader appeal of the design. Hospitals and research labs that cannot afford to maintain separate models for separate modalities can, in principle, deploy one frozen backbone and a small bank of routing parameters, swapping or extending the routing without disturbing the rest.
The authors acknowledge that the router currently distinguishes only broad domains. It does not, for instance, separate cardiac CT from abdominal CT, a distinction that would matter clinically. They also note that their evaluation is confined to static two-dimensional scans. Video sequences, where temporal consistency becomes a problem of its own, remain future work. And while the residual modulation idea generalizes naturally to dense prediction tasks like landmark detection, that generalization has not been tested.
The dominant trajectory in vision research over the past four years has pushed toward ever-larger backbones trained on ever-larger collections of data, with the expectation that scale alone will smooth out the rough edges between domains. DCRM-ViT bets in a different direction. It assumes the backbone is already powerful enough and that the remaining work is one of intelligent steering, finding the smallest gesture that turns a generalist into a specialist for the duration of a single inference, then turns it back. If that bet pays off in further work, it will not eliminate the demand for foundation models. It may reframe how those models reach the clinic.
The deeper question the paper raises is whether a router that thinks in terms of medical versus natural is granular enough to be useful in real clinical settings. Ultrasound from a Philips machine in a Spanish hospital and ultrasound from a portable device in a rural clinic look different in ways that a binary domain label cannot capture. Future versions of this work will likely need a router that thinks in shades rather than poles. The architecture, encouragingly, seems built to absorb that complication. The dimmer switch is already there. It just needs more positions.
- computer vision ,
- conference ,
- CVPR ,
- medical ,
- medical images ,
Related

Building AI that understands the Gulf’s climate challenges
An MBZUAI team has developed Gulf Climate Agent (GCA), an AI framework designed specifically for climate decision.....
- ACL ,
- conference ,
- computer vision ,
- climate change ,
- research ,

Training multimodal AI with limited labels for a world it has never seen
A new framework from MBZUAI researchers helps AI systems remain effective when data is scarce and inputs.....
Read More
Two heads are faster than one
MBZUAI researchers have developed a new approach to video understanding that reduces computational costs while maintaining accuracy.
- research ,
- large multimodal model ,
- CVPR ,
- video ,
- conference ,