
When AI stops playing “spot the difference” and starts understanding changes in MRIs
Wednesday, October 22, 2025

Radiology has a deceptively simple question it asks over and over: what changed between last year’s MRI and today’s? For people living with multiple sclerosis (MS), the answer can shape treatment decisions, because a brand-new bright spot on a follow-up FLAIR scan signals fresh disease activity. But finding those subtle specks can be very difficult with classical means.
A radiologist has to mentally align two 3D scans, account for different scanners and settings, and decide whether a faint smudge is biology or just noise. It’s slow, exhausting, and, even among experts, surprisingly variable.
A new system called DEFUSE-MS tries to take the drudgery and some of the doubt out of that process by reframing the task as reasoning about how the brain has changed, not just what it looks like.
In a paper presented at MICCAI 2025, researchers from MBZUAI and clinical partners describe DEFUSE-MS as a “deformation field-guided spatiotemporal graph-based framework.” Instead of treating each scan as a stack of pixels, the model builds a graph of small regions (nodes) within both the baseline and follow-up MRIs, then explicitly links those regions across time with edges that carry a compact description of how anatomy moved between visits.
That description comes from a non-rigid registration step (the classic “Demons” algorithm) that produces a deformation field, a 3D map of little vectors showing how each point in the baseline must warp to match the follow-up. In MS, genuine new lesions nudge their neighborhoods in distinctive ways; the deformation field captures that signature and turns “spot the difference” into structured evidence the model can reason over.
The architecture pairs a familiar U-shaped encoder–decoder – the basis of many medical segmentation systems – with a Heterogeneous Spatiotemporal Graph Module (HSTGM) that sits inside both the encoder and decoder. From the early convolutional “stem” layers, DEFUSE-MS constructs two node sets: baseline and follow-up. It connects each node to its nearest spatial neighbors within a scan, and also connects baseline nodes to their corresponding follow-up nodes with temporal edges.
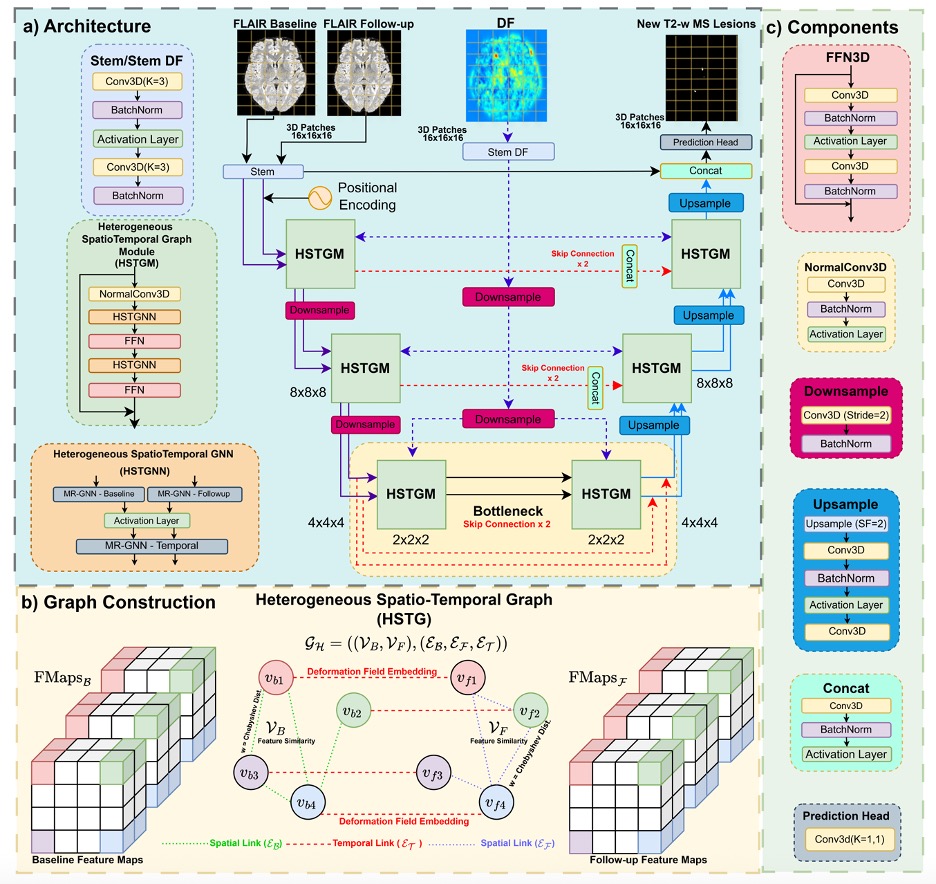
Here’s the trick: those temporal edges are enriched with learned embeddings of the deformation field, so the HSTGM can weight messages by “how much and in what way did this region deform?” The choice to treat deformation as an edge attribute instead of just another image channel turns out to be crucial, especially for attention-heavy models that otherwise get confused when geometric signals are shoved into appearance space.
Inside the HSTGM, the team uses Max-Relative Graph Neural Networks: each node looks at relative differences with its neighbors and keeps the strongest signal, a simple but effective way to highlight the most informative local change. After separate updates on the baseline and follow-up graphs, a temporal GNN aggregates across time using those deformation-aware edges; feed-forward layers bolster expressiveness and prevent over-smoothing. The whole thing remains end-to-end differentiable, so the deformation embeddings that sit on edges are learned jointly with the segmentation objective, not hand-crafted. It’s a neat hybrid of CNNs that contribute local texture and efficiency, the graph layers that bring long-range and temporal structure, and the deformation that field anchors “change” in geometry, not just intensity.
Mostafa Salem, one of the paper’s authors, says that the motivation was straightforward: new-lesion detection is fundamentally longitudinal. “Single-scan models ask ‘does this voxel look like a lesion?’ Our task asks ‘what actually changed between baseline and follow-up?’ You need a representation that separates true biological change from scanner quirks,” he said. The deformation field delivers exactly that. If an area bulges or its neighbors shift, the field records it; if a bright spot is just an intensity hiccup, the geometry stays put. The model treats the deformation as information flowing between timepoints on edges, where it naturally belongs.
Benchmarking and clinical promise
All of this only matters if the system holds up on a realistic benchmark, and here DEFUSE-MS leans on MSSEG-II, a longitudinal MS dataset spanning 100 patients and 15 scanners. The organizers recently updated the test set, correcting labels and adding lesions which was an unglamorous but important step that makes the task harder and the evaluation fairer. DEFUSE-MS was trained patch-wise on 3D FLAIR scans, with careful preprocessing. Inference uses a sliding window and recombination; the whole pipeline trains on a single A100 GPU and runs at speeds compatible with clinical workflows.
On the MSSEG-II test set, DEFUSE-MS outpaces modern CNN and Transformer baselines. For cases with no new lesions, the mean false-positive lesion volume is about 1.5 mm³ when using both deformation embeddings and spatial edge attributes; it might appear to be a tiny difference, but it is still relevant when you’re trying to keep alarm fatigue low. The team also reports lower false-positive burden than many deformation-free baselines, a practical win in the clinic where “clean” follow-ups are common.
A design choice that might surprise deep-learning purists is the decision not to stack the deformation field as an extra input channel. On attention-based models in particular, that strategy backfires: DF isn’t appearance, and forcing it into the image tensor injects misaligned noise that distracts attention maps. As an edge attribute, the same signal becomes helpful rather than harmful. DEFUSE-MS still beats a strong U-Net that does stack deformation with images, even if that U-Net sometimes produces fewer tiny false positives; overall detection metrics remain better with the graph-based approach. That result hints at a broader lesson: geometric correspondences belong in the relational parts of your model, not the pixel stack.
Looking ahead
Of course, no single system ends the conversation. Salem was candid about limits and next steps. A major one is scaling beyond two timepoints; real MS care unfolds over years. The natural extension is a chain of spatiotemporal graphs, linking every visit with deformation-aware edges and propagating evidence along the timeline. Another is multimodal MRI. DEFUSE-MS currently reasons over FLAIR; adding T1 or gadolinium-enhanced sequences could help disambiguate false positives and characterize activity. The authors are also eyeing federated or domain-adaptation setups so hospitals can fine-tune locally which is important when scanners, protocols, and populations differ. And while the method is tuned for MS, the template should generalize to any condition where anatomy evolves: tumor growth, white-matter hyperintensities, even postoperative changes.
It’s worth pausing on what “good” looks like in this space. The best human readers don’t agree perfectly on new-lesion labels; the updated MSSEG-II test set itself reflects how tricky annotation is across scanners and sites. DEFUSE-MS’s scores sit under the highest single-expert F1, but comfortably above prior automated systems evaluated on the (easier) older test labels, and it posts those gains while operating on the revised ground truth. The paper also includes qualitative examples where the deformation-aware model catches subtle lesions that variants miss; in at least one case, multiple human raters agreed with the model’s call. That kind of triangulation (automation surfacing a candidate and experts vetting it) feels like the right near-term division of labor.
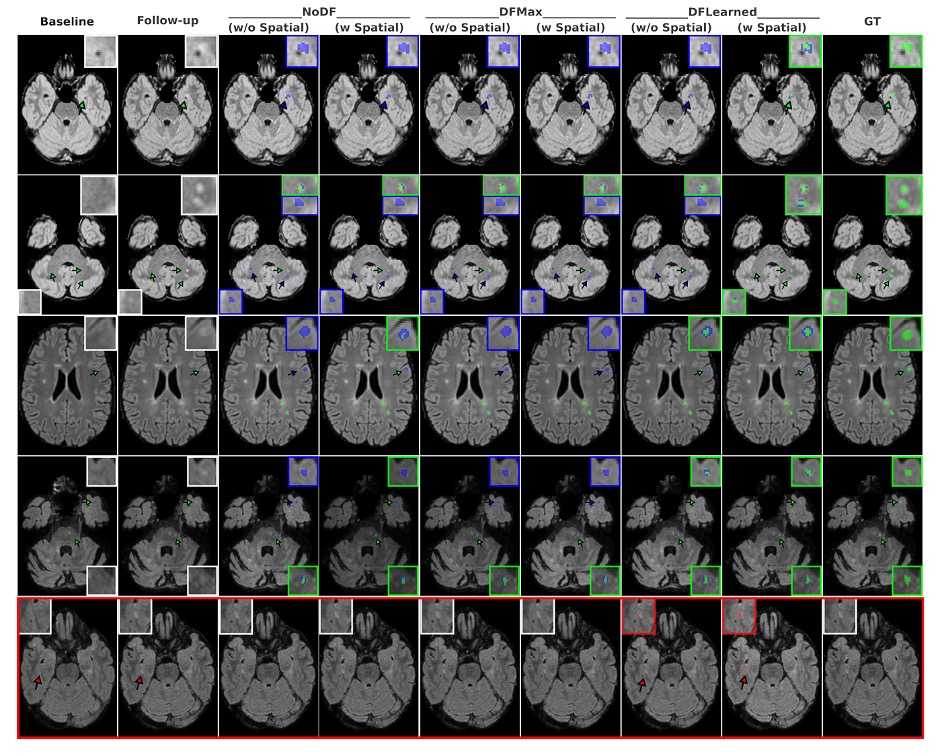
The bigger takeaway is conceptual. For years, medical imaging AI has tried to make better pixel classifiers: deeper U-Nets, bigger transformers. DEFUSE-MS points to a different axis of improvement: build models that encode the structure of the task. Longitudinal questions are about relationships across time; give the model a vocabulary for those relationships, and feed it geometric evidence that distinguishes real change from artifacts. Once you see the deformation field as an edge, not a channel, a lot of design choices snap into focus.
If systems like this make it into clinical workflows, they won’t replace the radiologist’s judgment. But they could make that judgment faster, more consistent, and less error-prone, especially on those hard days when the new lesion is a millimeter wide and the follow-up was scanned on a different machine.
- research ,
- healthcare ,
- MICCAI ,
- medical ,
- medical imaging ,
- imaging ,
Related

Building AI that understands the Gulf’s climate challenges
An MBZUAI team has developed Gulf Climate Agent (GCA), an AI framework designed specifically for climate decision.....
- ACL ,
- conference ,
- computer vision ,
- climate change ,
- research ,

Training multimodal AI with limited labels for a world it has never seen
A new framework from MBZUAI researchers helps AI systems remain effective when data is scarce and inputs.....
Read More
Two heads are faster than one
MBZUAI researchers have developed a new approach to video understanding that reduces computational costs while maintaining accuracy.
- research ,
- large multimodal model ,
- CVPR ,
- video ,
- conference ,