
A new playbook for patient privacy in the age of foundation models
Tuesday, September 30, 2025

In the past, when a patient withdrew consent, deleting a database row from a software application used to be enough. Now that AI models are starting to be used in more healthcare applications, removing a person’s information from a data set is more complicated, as the model has already “learned” from that information. Darya Taratynova and Shahad Hardan, two researchers from MBZUAI, have built a practical way to make clinical AI un-learn, without throwing everything away.
Hospitals increasingly train AI on multimodal patient records such as chest X-ray plus radiologist reports to flag disease earlier and personalize care. But what happens when a patient (or an entire site) asks to be removed after the model is trained? Regulations such as the GDPR’s right to be forgotten and HIPAA-driven retention policies make that a live issue, and simple deletion doesn’t help: the “fingerprints” of those records persist in the model’s weights. In multimodal systems the problem is tougher still, because models learn links between image and text as much as they learn either modality alone.
That’s the backdrop for Forget-MI (short for “Forgetting Multimodal Information”), a method described in a paper by Hardan and Taratynova and which will be presented at MICCAI 2025, a conference taking place in South Korea.
“If a patient says ‘forget me,’ the model should lose its memory of that patient, yet keep working for everyone else,” the duo say when discussing Forget-MI, which starts from a trained multimodal model and produces an unlearned version that behaves as if specified patients were never in its training set, without full retraining.
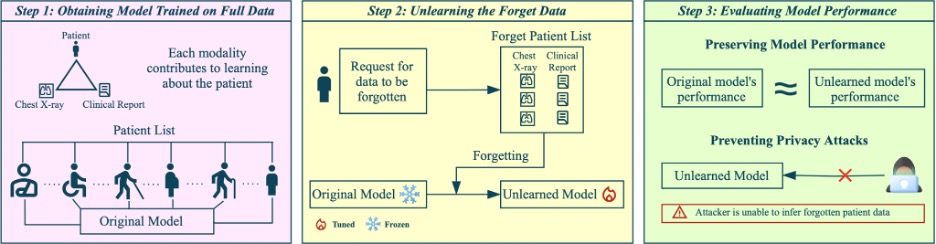
Conceptually, it pulls in two directions at once: unlearning the target patients’ unimodal (image or text) signals and their joint (image-text) association while also retaining everyone else’s unimodal and joint knowledge so overall accuracy stays useful.
For the curious, the model backbone is based on a late-fusion multimodal classifier (ResNet for images, SciBERT for text), with a multimodal adaptation gate to form joint embeddings.
The trick to achieving good performance is to optimize four coordinated loss terms together:
- UU (Unimodal Unlearning) loss: push the image and text embeddings for the “forget” patients away from where the original model placed them;
- MU (Multimodal Unlearning) loss: break the cross-modal link the model learned between that patient’s image and report;
- UR (Unimodal Retention) loss: keep embeddings for retained patients stable;
- MR (Multimodal Retention) loss: keep their image-text links intact.
To prevent lingering “ghosts” of a patient, Forget-MI adds small noise (Gaussian on images; light character/word edits on text) so the model forgets a neighborhood around each case, not just an exact pixel sequence or phrase. Too much noise hurts generalization; too little leaves traces, so the team has tuned it carefully.
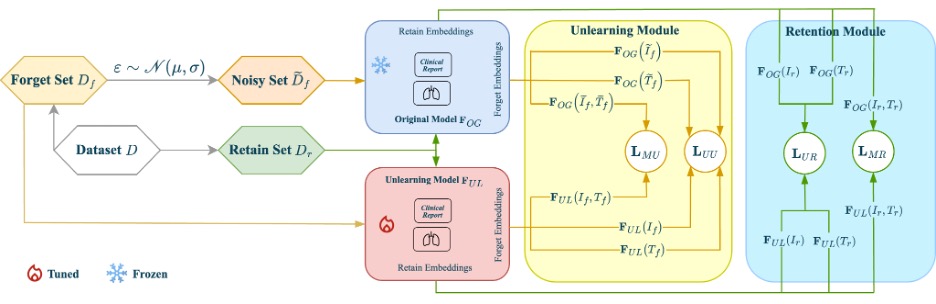
Why not just cut the image-to-text link and call it a day? Because multimodal models entangle features: an image can shape how text is represented (and vice-versa). Forget-MI targets both the unimodal “fingerprints” and the joint association that ties them together.
How Forget-MI was tested (and why the metrics matter)
The researchers used a curated MIMIC-CXR subset (6,742 chest X-rays + reports from 1,663 subjects) labeled across four edema stages (43% none, 25% vascular congestion, 22% interstitial, 10% alveolar). They created patient-level forget sets (the set of points we want to unlearn) of 3%, 6%, and 10% to mimic real hospital withdrawal scenarios, including the common case where one patient has multiple studies.
Three evaluation lenses matter jointly:
- Membership Inference Attack (MIA ↓): can an attacker tell whether a case was in training? Lower is better, ideally indistinguishable from new, unseen data.
- Performance on the forget set ↓: Area Under the Curve (AUC)/F1 (the weighted harmonic mean of the mode’s precision and recall scores) should drop; the model should no longer perform well on the deleted patients.
- Performance on an independent test set ↑: should stay close to the original/retrained model, otherwise the cure is worse than the disease.
Across experiments, Forget-MI lowered MIA by ~0.20 on average and reduced AUC and F1 on the forget set by ~0.22 and ~0.31, while matching the retrained model on the held-out test set, the gold-standard behavior if you had time, computational resources, and permission to retrain from scratch.
Head-to-head with popular baselines, Forget-MI typically produced the lowest MIA (strongest privacy) with test-set performance closest to retraining. Modality-agnostic methods failed to push the unlearned model far enough from the original; the modality-aware preserved accuracy better but forgot less, reflecting a privacy–utility tradeoff the authors quantify openly.
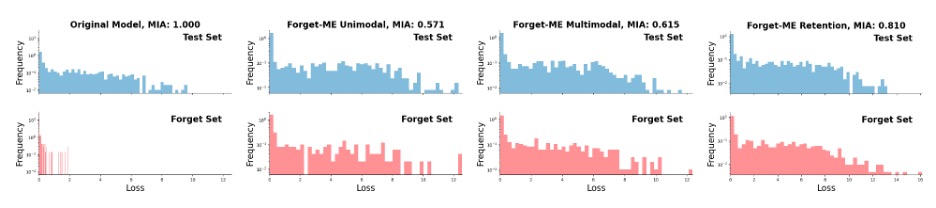
The telling diagnostic plot compares the loss distributions of forget-set vs. test-set samples. In the original model, the two distributions are separable; after unlearning, they overlap, meaning the model no longer recongizes the forgotten cases as part of the training dataset.
Cost and cadence: from one-off fixes to routine maintenance
Full retraining on this setup took approximately 14 hours; Forget-MI ran in roughly five hours, with other unlearning baselines around four hours. That delta matters for operations: hospitals can batch requests (for example, on a monthly basis) and run unlearning jobs without freezing clinical AI for days.
An unexpected finding: the best loss weighting depends on how much you forget. At 3%, emphasizing unimodal unlearning worked best; at 6%, multimodal terms took the lead; by 10%, retention needed more weight to protect overall performance – an empirical guide future users can borrow.
Why multimodal makes privacy harder (and why this is progress)
In single-modality unlearning, you can attack one encoder. In clinical reality, models learn that “this kind of opacity” in an X-ray plus “this phrasing” in a report together signal disease; the joint representation is often where the strongest memory lives. Forget-MI explicitly erases both unimodal and joint representations for the forget set, while stabilizing those for everyone else.
The team also confronted multi-study patients head-on, defining forget sets at the patient level so the model can’t “remember by proxy” through remaining studies.
The paper also presents some limits and honest caveats to the approach. First, bigger forget sets bite back: around 10%, protecting test-set utility gets harder, evidence that current practical unlearning still faces limits when large slices of data must go. Secondly, noise is a scalpel, not a hammer. No noise leaves traces and too much noise erodes generalization; therefore, careful tuning is part of the recipe. Finally, class imbalance shows up: where data is scarce (minority classes), stronger forgetting can dent F1, another privacy–utility trade the authors quantify.
What Forget-MI means for hospitals and for foundation models
Forget-MI provides a clear advantage for privacy officers today wishing to move from policy to practice. A sensible workflow could imply monthly batching of deletion requests, running Forget-MI to produce an auditable “unlearned” model, and tracking MIA, forget-set AUC/F1, and test-set AUC/F1 as a minimum KPI bundle. Vendors can expose a “forget this patient” API within PACS/EHR pipelines, with patient-level selection to catch multi-study cases.
In the near future, Forget-MI can address a known challenge with foundation models and unlearning: their vast pretraining means many near-duplicates exist, making it harder to prove a specific patient’s signature is gone. Taratynova argues that the field will need stricter evaluations, tighter hyperparameter discipline, and likely new criteria beyond MIA to build confidence at foundation-model scale. The Forget-MI recipe (targeted embedding pushes/pulls across uni- and cross-modal representations plus neighborhood forgetting) extends naturally to video+text (think ultrasound with voice notes) and other modality mixes.
So how will we know a model has truly forgotten? Today’s best proxy is agreement with a retrained model (the ideal you’d get, minus the deleted data), combined with low MIA and weak performance on the forget set while preserving performance elsewhere.
That’s the bar Forget-MI aims to meet (and on MIMIC-CXR, it largely does), while saving most of the hours and compute retraining would demand. The authors have released the code to help others audit and extend the method.
“The day clinicians trust unlearning,” Hardan says, “is the day they can see that the model no longer recognizes the removed patients and still works for everyone else.”
Forget-MI doesn’t solve every edge case of unlearning, but it turns an abstract right into a concrete workflow for multimodal clinical AI: privacy that runs on Tuesday night and finishes before morning rounds. That alone is a meaningful step forward.
- research ,
- privacy ,
- conference ,
- dataset ,
- MICCAI ,
- researchers ,
- data ,
- multimodal ,
- medical imaging ,
- information ,
Related

Building AI that understands the Gulf’s climate challenges
An MBZUAI team has developed Gulf Climate Agent (GCA), an AI framework designed specifically for climate decision.....
- ACL ,
- conference ,
- computer vision ,
- climate change ,
- research ,

Training multimodal AI with limited labels for a world it has never seen
A new framework from MBZUAI researchers helps AI systems remain effective when data is scarce and inputs.....
Read More
Two heads are faster than one
MBZUAI researchers have developed a new approach to video understanding that reduces computational costs while maintaining accuracy.
- research ,
- large multimodal model ,
- CVPR ,
- video ,
- conference ,