
Detecting deepfakes in the presence of code-switching
Tuesday, August 12, 2025

Deepfakes are AI-generated videos that appear authentic but depict events that never actually happened. With the rise of generative AI models that can quickly and cheaply generate high-quality video from simple text prompts, deepfakes are becoming more common and have the potential to erode trust in individuals and institutions.
While researchers have developed detectors that can identify deepfakes, today’s systems have largely been trained on English, limiting their usefulness in other languages.
An added challenge is that in many settings, people often communicate using words from more than one language. This practice, known as code-switching, is common in the Arab world, where people often mix Arabic and English in the same sentence. While this linguistic fluidity is easy for people to follow, it poses a vulnerability for deepfake detectors that are trained on a ‘monolingual foundation,’ explains Muhammad Haris Khan, Assistant Professor of Computer Vision at MBZUAI.
Khan, along with colleagues from MBZUAI and Monash University, are working to address this problem and have built a first-of-its-kind deepfake dataset that includes many hours of audio and video focused specifically on Arabic-English code-switched content.
The researchers tested several deepfake detectors on the dataset, called ArEnAV, and found that code-switching significantly reduced the performance of detectors to identify deepfakes. Their findings, which they recently reported in a study titled “Tell Me Habibi, Is It Real or Fake?,” illustrate the need for resources that reflect the fluidity of real-world communication.
Kartik Kuckreja, a research associate at MBZUAI and lead author of the study says that the team’s work is at the forefront of efforts to ensure that AI technologies are both culturally aware and socially responsible.
Parul Gupta, Injy Hamed, Thamar Solorio, and Abhinav Dhall are co-authors of the study.
Challenges of code-switching
Code-switching between Arabic and English isn’t a rare occurrence but is in fact quite common, particularly in the UAE and other countries in the Gulf.
While researchers have built multilingual datasets to support deepfake detection, individual utterances in these datasets tend to be in one language or another. This motivated Khan, Kuckreja, and their colleagues to build ArEnAV, which is the largest and most comprehensive dataset designed specifically for code-switched Arabic-English deepfake detection.
The dataset is made up of 765 hours of videos in Arabic sourced from YouTube that were altered to include instances of Arabic-English code-switching and changes in dialect.
“The scale of this dataset is truly unprecedented, and it directly tackles the multilingual challenge where previous datasets have often fallen short,” Khan says. “Its strength lies in its explicit inclusion of intra-utterance code-switching and diverse dialects, making it a highly representative benchmark.”
Building ArEnAV
The researchers began creating ArEnAV by gathering YouTube links from an existing dataset called VisPer. They split the videos into short clips and processed them to obtain facial gestures of speakers in each frame. They generated transcripts of these clips and aligned the transcripts with the audio, which provides “word-level timestamps for code-switched Arabic and English data,” they explain.
The researchers then used a language model, OpenAI’s GPT-4.1-mini, to introduce modifications to the transcripts, emulating changes that are similar to what is done with deepfakes. There were three types of edits: changes to meaning, to meaning and dialect, and to meaning and language — that is, translations from Arabic to English to emulate code-switching. “We provided the language model with precise instructions to control the edits and ensure they were realistic,” Kuckreja says.
From these altered transcripts, the researchers synthesized new audio that preserved the characteristics of the speakers’ voices using a set of techniques called cloning strategies. Finally, they generated new video that matched the altered audio.
Building ArEnAV was a complex initiative that involved several systems, Khan explains. “We needed multiple systems because a single toolchain would have fallen short due to the nuances of Arabic phonetics and cross-lingual synthesis.”
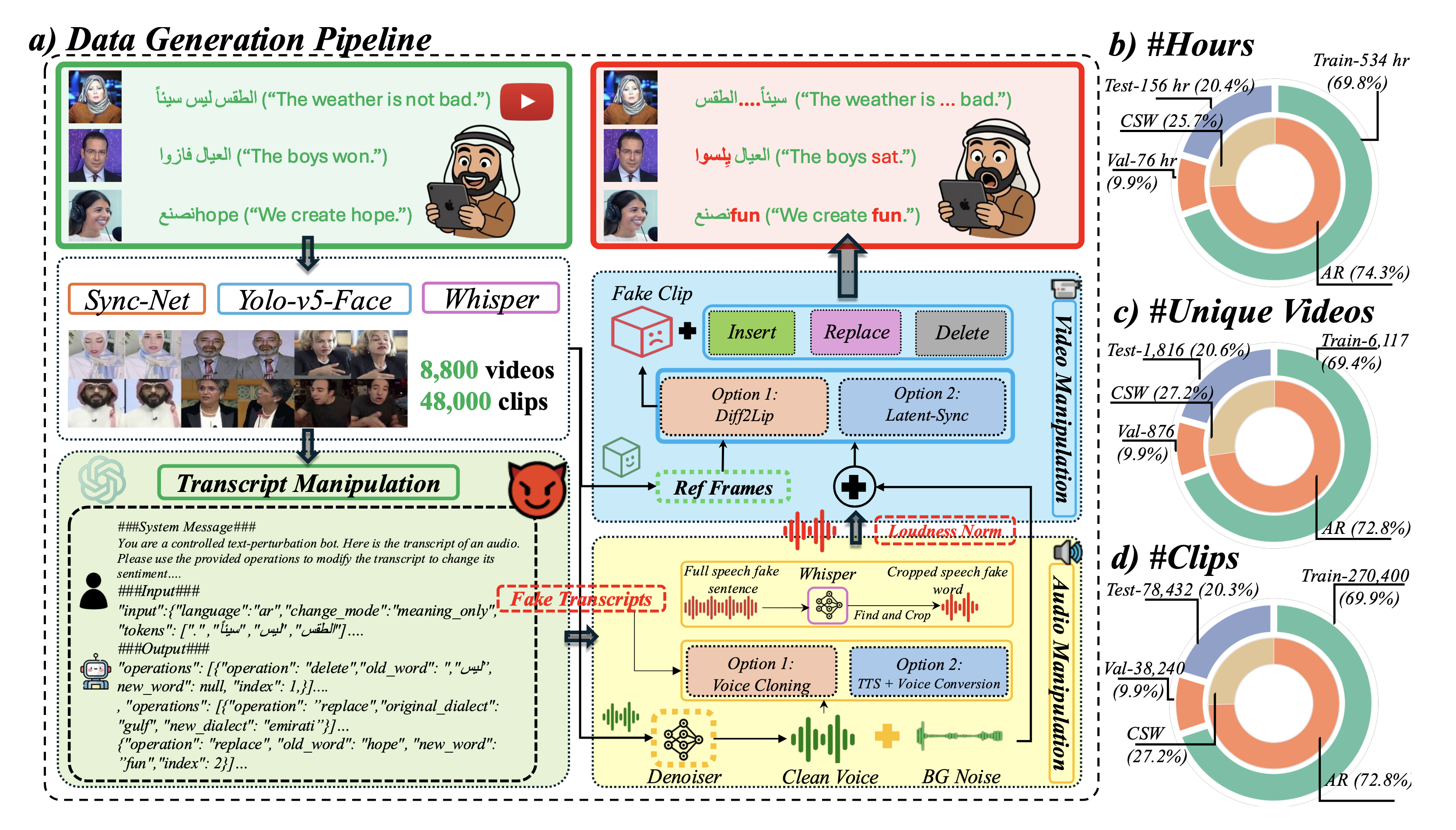
The data generation pipeline for ArEnAV (left) and the data distribution across training, validation, and testing sets (right).
Deepfakes fake out people
Perhaps what makes deepfakes so dangerous is not only that they elude detection by machines but that they trick people, too. The researchers had people review a set of videos from ArEnAV to see if they could pick out deepfakes. The testers, many of whom were native speakers of Arabic, were only 60% accurate and had a hard time identifying where exactly in the videos the modified speech occurred.
The researchers also found that 85% of the testers failed to identify deepfakes when the alterations were made to English words. They explain that this high error rate could be attributed to the fact that voice cloning tools are better in English than they are in Arabic. Alternatively, it could simply be because there are natural fluctuations in tone when speakers switch from one language to another.
Room for improvement and the road ahead
The researchers divided ArEnAV into standard splits for training, validation, and testing and evaluated several deepfake detectors on it in zero-shot settings and after fine-tuning.
Overall, they found that models that were trained on standard datasets, like AV-1M or LAV-DF, saw accuracy and localization drops of 35% or more when evaluated on ArEnAV. They also saw that while some detectors had previously performed well on monolingual benchmarks, they struggled on code-switched deepfakes.
Khan says that the findings illustrate critical and practical implications for the complex relationship between technology and policy today. “Deepfake screening pipelines that are used in the MENA region must be capable of handling code-switched content,” he says. “Relying on monolingual models results in significant blind spots that make platforms vulnerable to misinformation and impersonation.”
Resources like ArEnAV, however, can be a vital tool for media outlets and fact-checking groups that are building verification systems, he says. And it could prove to be particularly valuable around major societal events like elections.
The researchers have made their dataset available through a ‘gated release’ that requires an end user license agreement. The goal is to balance open access with the risk of misuse, Khan explains. “Our gated access aims to mitigate risk by ensuring responsible use of the data.”
- natural language processing ,
- computer vision ,
- nlp ,
- dataset ,
- Arabic language ,
- prompting ,
- Arabic ,
- Deepfakes ,
- deep fake ,
- code switching ,
Related

Building AI that understands the Gulf’s climate challenges
An MBZUAI team has developed Gulf Climate Agent (GCA), an AI framework designed specifically for climate decision.....
- ACL ,
- conference ,
- computer vision ,
- climate change ,
- research ,

Training multimodal AI with limited labels for a world it has never seen
A new framework from MBZUAI researchers helps AI systems remain effective when data is scarce and inputs.....
Read More
Two heads are faster than one
MBZUAI researchers have developed a new approach to video understanding that reduces computational costs while maintaining accuracy.
- research ,
- large multimodal model ,
- CVPR ,
- video ,
- conference ,