
When models see what isn’t there: Reducing hallucinations with FarSight
Friday, June 13, 2025

Multimodal large language models (MLLMs) are becoming better at interpreting images and videos, but they still make mistakes. Sometimes they even make up objects that don’t appear in images. These hallucinations have limited the usefulness of MLLMs, particularly in settings where accuracy is critical.
Researchers at MBZUAI, Monash University, and other institutions have developed a new plugin called FarSight that can be used with MLLMs to reduce hallucinations.
Feilong Tang, a lead author of the study and a visiting student at MBZUAI, explains that when an MLLM generates long sections of text about an image, it can stop paying attention to relevant details in the image, leading to hallucinations. “With FarSight, we want to make models more reliable and overcome the weaknesses of these systems,” he said.
Tang and his colleagues’ study about FarSight was shared in an oral presentation at the Computer Vision and Pattern Recognition Conference (CVPR) held in Nashville, Tennessee. Of the more than 13,000 papers that were submitted to the conference, only 96 were selected to be given as oral presentations.
Chengzhi Liu, Zhongxing Xu, Ming Hu, Zelin Peng, Zhiwei Yang, Jionglong Su, Minquan Lin, Yifan Peng, Xuelian Cheng, Imran Razzak, and Zongyuan Ge are authors of the study.
One hallucination leads to another
Hallucinations in MLLMs come from a misalignment between what appears in an image and the text a model generates about the image. When an MLLM hallucinates, it has the tendency to build on this fiction with what researchers call snowball hallucinations. One mistake grows much larger as a model elaborates on its initial error.
In their study, Tang and his coauthors present an example of a snowball hallucination produced by LLaVA-1.5, an open source MLLM. They prompted the system to describe a photograph of a winter scene with a stream running through a forest. Initially the model generated accurate text, but it soon hallucinated, saying that the photo depicted a “small wooden bridge” crossing the stream. It expanded on this initial hallucination with intricate details, writing that the “bridge’s handrails have carvings of pinecones and leaves, adding rustic charm to the winter scene.”

An example of initial and snowball hallucinations produced by LLaVA-1.5, an open-source MLLM.
The researchers discovered that most hallucinations are in fact snowball hallucinations. They tested three MLLMs — LLaVA-1.5-7B, Video-LLaVA-7B, and EDVT — on benchmark datasets and found that snowball hallucinations occurred more than four times as often as initial hallucinations. By reducing initial mistakes, researchers can significantly reduce the total number of hallucinations.
How FarSight works
Other methods have been developed to reduce hallucinations by MLLMs. These include factchecking outputs from models with information from the web and different approaches to fine-tuning. But they don’t address the root causes of these mistakes.
In their study, the researchers identify two key causes of hallucination. One is attention collapse, where a model pays more attention than it should to what are known as outlier tokens. These tokens could represent punctuation or other non-essential information.
Another cause is what’s known as positional information decay, where a multimodal model pays less attention to visual tokens from an image as it generates longer pieces of text. This results in the model forgetting details of the image.
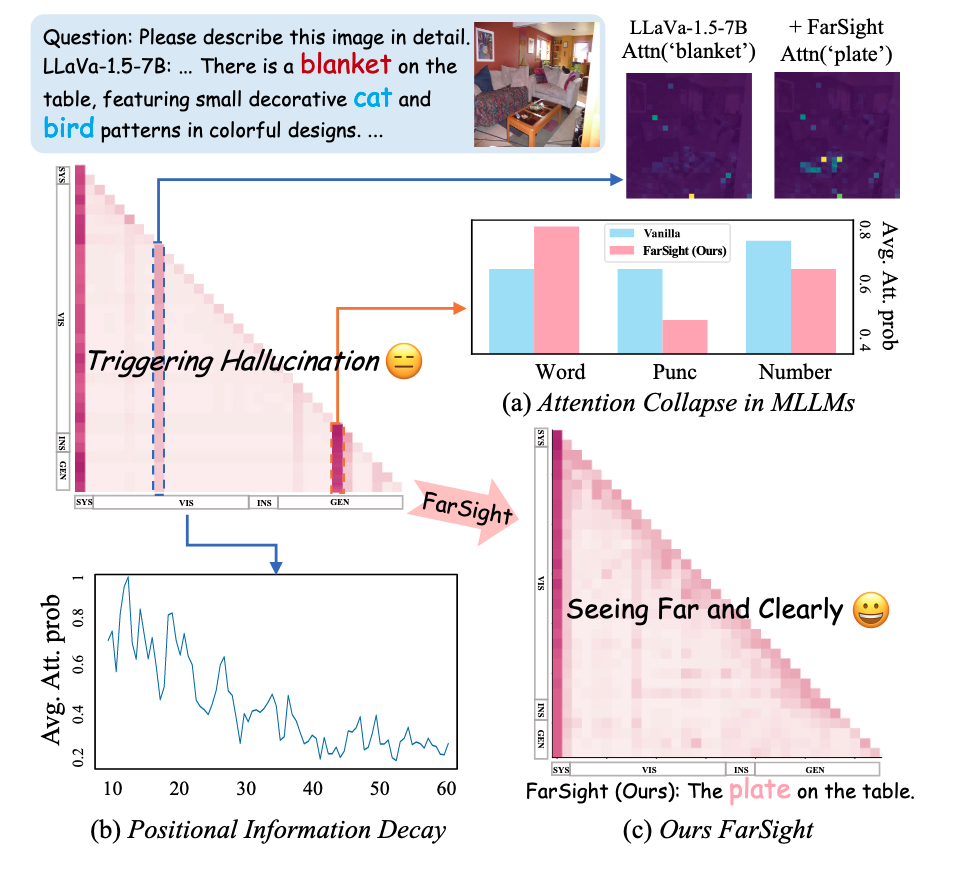
(a) During attention collapse, a model assigns high attention scores to outlier tokens that represent punctuation and numbers. Adding FarSight to the model improved its focus on relevant tokens that represent words. (b) Shows positional information decay. As more text tokens are generated, the model pays less attention to visual information. (c) FarSight mitigates both issues by effectively reducing attention interference from outlier tokens, improving response accuracy.
Imran Razzak, coauthor of the study and associate professor of computational biology at MBZUAI, says that FarSight addresses positional information decay by “reducing a model’s attention on irrelevant tokens, helping it sustain focus on visual details as it generates long passages of text.”
FarSight does this by modifying what is known as a causal mask, which determines how models use tokens when generating text. A causal mask is arranged as a matrix and represents how models generate text in an autoregression fashion, generating new tokens based on tokens that have appeared previously.
Typically, the upper right of a causal mask corresponds to future tokens in a sequence. This section of the causal mask doesn’t receive any attention, as models are designed to ignore future tokens while generating text.
FarSight uses the upper right part of the causal mask differently. Instead of blocking attention to this section, it uses a concept called attention register, which allocates more attention to meaningful tokens and away from outlier tokens, helping the model recover long range dependencies in text and improving the accuracy of visual grounding.
Improvements to MLLMs with the help of FarSight
The researchers evaluated the performance of several MLLMs with and without FarSight on image and video benchmarks.
On CHAIRs, a benchmark designed to measure hallucinations produced by MLLMs, adding FarSight to LLaVA-1.5 reduced hallucinations by 6.4 percentage points. On comprehensive and general visual question-answering tasks, FarSight improved LLaVA-1.5 by more than two percentage points.
Improvements by FarSight weren’t limited to LLaVA-1.5. Other models tested with FarSight, including InstructBLIP and Video-LLaVA, showed improvements on hallucination benchmarks.
The researchers also tested MLLMs with and without FarSight on video question-answering tasks and found that FarSight improved the performance of the models on three benchmarks, improving the accuracy of MLLMs on the MSVD-QA benchmark by more than two percentage points.
Overall, the researchers note that the results from their evaluations show that FarSight “is effective at reducing hallucinations in both structured and unstructured environments.”
- computer vision ,
- llms ,
- CVPR ,
- hallucination ,
- multimodal ,
- MLLMs ,
Related

A compact multimodal model for real-time video understanding on edge devices
Mobile-VideoGPT uses efficient token projection to enhance a model’s efficiency while maintaining high performance.
- GPT ,
- edge devices ,
- multimodal ,
- computer vision ,

A two-stage approach for making AI image generators safer | CVPR
MBZUAI's Karthik Nandakumar presented STEREO at CVPR – a new framework that uses adversarial training and concept.....
- CVPR ,
- research ,
- Safety ,
- image generator ,
- computer vision ,
- diffusion models ,
- text to image ,

A new vision-language model for analyzing remote sensing data | CVPR
Researchers at MBZUAI have developed EarthDial, a new VLM that can handle a range of complex geospatial.....
- geospatial ,
- remote sensing ,
- Vision language model ,
- data ,
- VLM ,
- CVPR ,
- llms ,
- dataset ,
- computer vision ,