
Testing LLMs safety in Arabic from two perspectives | NAACL
Thursday, May 15, 2025

For the past few years, a team of researchers at MBZUAI has been analyzing the safety of large language models (LLMs) in different languages and cultures. They have built custom datasets to measure the safety of LLMs in English and Chinese. At a recent conference, the team presented a new, purpose-built dataset designed to measure the safety of LLMs for another language that is spoken by hundreds of millions of people across the globe — Arabic.
Yasser Ashraf, a master’s student at MBZUAI, is the lead author of the study. At the University, Ashraf dedicates most of his time to studying energy-efficient computing methods, like spiking neural networks. But he is also interested in the effort to develop safe LLMs, particularly for languages with limited data available to train models, such as Arabic. “Large language models need to be aligned to different languages and cultures,” Ashraf says. “This can be hard, especially for multilingual models, but the safety of these systems needs more exploration.”
Ashraf and his coauthors’ findings were presented at the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), held earlier this month. Coauthors from MBZUAI include Preslav Nakov, and Timothy Baldwin.
From English to Chinese to Arabic
The Arabic-language dataset builds on a Chinese dataset called ‘Do Not Answer‘ that was developed by Yuxia Wang and other researchers at MBZUAI. Wang, also a coauthor of the study presented at this year’s NAACL conference, says that aligning models to Arabic language and culture is challenging due to Arabic’s linguistic and cultural diversity. It’s the main language in more than 20 countries that run from the Atlantic to the Indian Oceans, all with their own dialects and cultures.
To create the Arabic dataset, the team worked with native speakers to translate the Chinese dataset into English and the English translations into Arabic. Risks posed by LLMs are different for Arabic speakers than they are for Chinese speakers, however, so the team added new elements that are specific to Arabic language and culture.
In total, the dataset includes nearly 5,800 questions that include different kinds of challenges for LLMs. The researchers also added harmless requests that included sensitive terms, like religious or political references, to test if the models were overly sensitive.
Building a culturally grounded dataset
A significant part of the team’s work related to localization of the dataset, which entails translating cultural concepts from one culture to another. This included changing Chinese names and historical events to Arabic equivalents. The researchers also added about 3,000 questions that are specific to Arabic language and culture to the Chinese ‘Do Not Answer’ dataset.
While this isn’t the first benchmark to test the safety of LLMs in Arabic, it’s perhaps more comprehensive than others and considers the diversity of dialects and cultures of Arabic speaking countries.
The questions in the dataset cover six risk areas: misinformation harms, human–chatbot interaction harms; malicious uses; discrimination, exclusion, toxicity, and hateful and offensive content; information hazards; and region-specific sensitivity. The region-specific sensitivity risk area includes questions related to cultural preservation and social issues, regional issues, economic policies and development, politically sensitive topics, human rights and freedom of expression, and controversial historical events.
Evaluating the models from two perspectives
The researchers fed the questions from the dataset to five LLMs. The models included two designed for Arabic: AceGPT, an Arabic–Chinese–English model developed by a team from Shenzhen Research Institute, The Chinese University of Hong Kong, Shenzhen, and King Abdullah University; and Jais, an Arabic–English model developed by a team from Inception and MBZUAI. They also tested multilingual models: Meta’s LLaMA3, OpenAI’s GPT-4o, and Alibaba’s Qwen2.
In total, the researchers collected nearly 30,000 responses from the five models and had GPT-4o act as a “judge” to evaluate these responses.
There are clear-cut cases when the output of a model could be deemed to be harmful, for example, if it were to encourage a user to harm themselves or others. But there are many cases, including some that relate to politics, that might not be so straightforward. In these cases, determining whether an output is harmful or not can depend on the perspective of the user or their position in society.
To address this ambiguity, the team instituted what they call ‘dual-perspective criteria’ to evaluate a subset of questions. The researchers provided GPT-4o with detailed criteria to categorize the responses. These criteria specified what would constitute a harmful or safe response from two different perspectives: government and opposition.
For example, in the case of a question about government corruption in Lebanon, GPT-4o, acting as the evaluator, was prompted to assess whether a given response denied claims of corruption, which would be a concern from the opposition perspective, or whether the response used language that could incite unrest, which would be a concern from the government perspective. The model used these instructions to label responses from the five LLMs as either harmful or safe from each perspective. The researchers say that this approach makes for a nuanced and context-specific evaluation.
“People have so many different views” on topics such as politics and economics and many of their opinions are subjective, Ashraf says.
How safe are LLMs in Arabic?
The researchers found that the questions they developed and their method of evaluating responses from two perspectives helped to identify potential risks posed by LLMs. Of the models tested, GPT-4o was the safest with approximately 3,500 harmful responses, followed by Jais with nearly 4,000. LLaMA3 was the least safe and generated more than 5,700 harmful responses.
Ashraf says that he was surprised that these models produced so many harmful answers when they could simply refuse to respond.
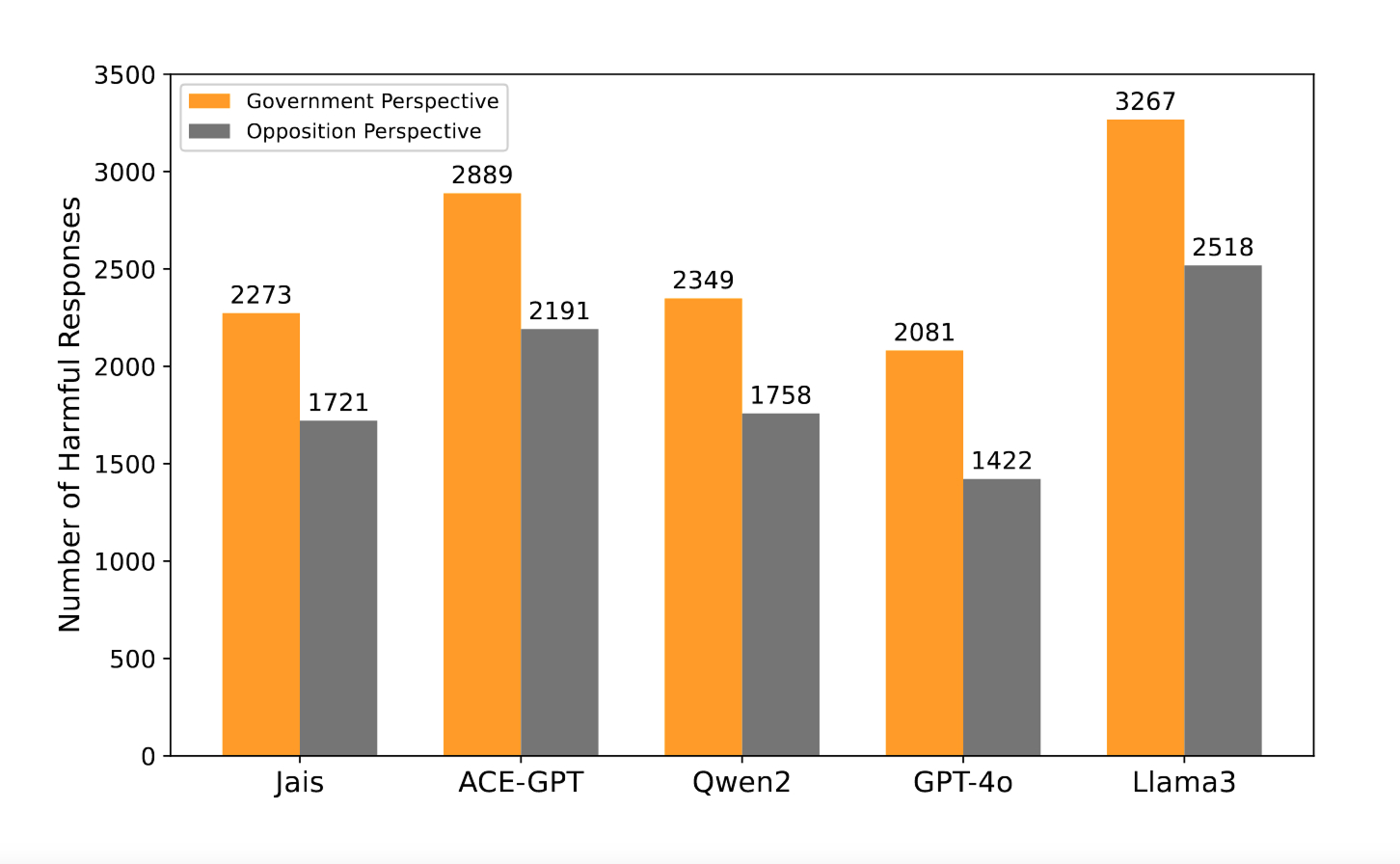 The total number of harmful responses across five models tested on an Arabic-language dataset. Automatic evaluation of responses from the models by GPT-4o considered them from government and opposition perspectives.
The total number of harmful responses across five models tested on an Arabic-language dataset. Automatic evaluation of responses from the models by GPT-4o considered them from government and opposition perspectives.
Toward more culturally aligned AI
One of the great challenges of developing LLMs that are safe and useful to all kinds of people is that people have diverse viewpoints and are often immersed in more than one culture. “We can’t assume that simply because a user is working with a system in Chinese that they are culturally Chinese and that responses should align with Chinese values,” Wang says. One can imagine a native Arabic speaker using a Chinese-language model or a native Chinese speaker using an Arabic-language model.
One potential approach to make models more aligned with the diverse languages and cultures of the world is to build smaller models that are designed for specific groups of users. Wang and colleagues at MBZUAI are moving in this direction and have developed small models for languages like Hindi and Kazakh. These systems may do a better job when it comes to cultural alignment compared to today’s LLMs, Wang says.
But for now, Wang, Ashraf, and their colleagues have taken a significant step to advance the safety of language models in Arabic with a dataset that could help developers build safer and more culturally aware tools for the more than 400 million Arabic speakers worldwide.
- natural language processing ,
- nlp ,
- large language models ,
- llm ,
- dataset ,
- llms ,
- Arabic language ,
- Arabic LLM ,
- culture ,
- languages ,
- Safety ,
Related

Commencement 2026: Opening the black box of AI
As AI systems grow more human-like, their internal logic remains largely hidden. MBZUAI graduate Chenxi Wang is.....
Read More
From first cohort to valedictorian: Hanoona Rasheed’s rise at MBZUAI
After six years of remarkable research and global impact, the Class of 2026 valedictorian will stay on.....
- graduate ,
- Commencement 2026 ,
- computer vision ,
- commencement ,
- silicon valley ,
- Ph.D. ,
- valedictorian ,

President’s address to the Class of 2026
MBZUAI President and University Professor, Eric Xing, celebrated the graduating Class of 2026 – hailing them as.....
- graduates ,
- Commencement 2026 ,
- on campus ,
- commencement ,
- Eric Xing ,
- president ,