
Why AI can describe an image but struggles to understand the culture inside it
Monday, March 23, 2026

One of the common ways to overestimate a modern AI system is to ask it to describe a picture and then mistake its fluency for understanding. A model can produce polished text, identify a few obvious objects, and still miss the social world the image belongs to. A new paper from MBZUAI, co-authored by Karima Kadaoui, Hanin Atwany and Hamdan Al-Ali and accepted at EACL 2026, takes aim at exactly that problem by asking how well vision-language models handle images grounded in four Arabic-speaking societies, and whether they can talk about them in the dialects people actually use.
The benchmark is called JEEM. It spans Jordan, the United Arab Emirates, Egypt, and Morocco, and covers two familiar multimodal tasks: image captioning and visual question answering. What makes it unusual is not just the language, but the level at which the language is defined. In addition to Modern Standard Arabic, which dominates many formal NLP resources, the dataset works with Jordanian, Emirati, Egyptian, and Moroccan dialects. That matters because Arabic is a language with deep regional variation, shaped by different histories, vocabularies, and visual cultures.
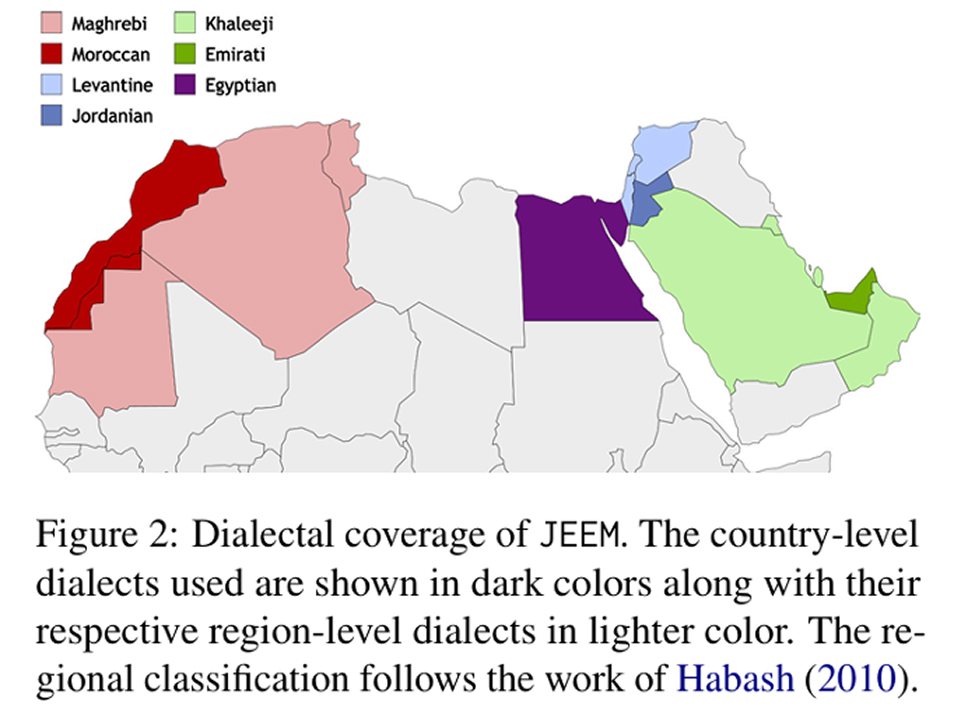
To date, much of the existing work on Arabic vision-language evaluation either translates English-language datasets, uses culturally thin source material, or treats Arabic as a single standardized form. JEEM tries to do something more grounded. Its images come from regionally relevant sources including Wikimedia, Flickr, and personal archives, and native speakers were recruited to write captions and question-answer pairs tied to their own dialects. The result is a dataset of 2,178 images and 10,890 question-answer pairs that is designed to reflect everyday life, local artifacts, and culturally specific scenes rather than a translated version of someone else’s visual world.
Convincing, but not accurate
The paper evaluates five Arabic-capable open models, Maya, PALO, Peacock, AIN, and AyaV, alongside GPT-4o. Across both captioning and question answering, the pattern is clear: fluent language generation is easier than genuine understanding, and the metrics currently available don’t match human judgement for Arabic dialects in a similar way to the ones used to measure model capability. Models often score relatively well on fluency, yet lag on the harder semantic criteria such as consistency and relevance. In other words, they can sound convincing without actually answering the question well or describing the image accurately.
The gap becomes more revealing when culture enters the frame. In one example discussed in the paper, annotators from different Arab regions interpreted an image of Omani halwa in strikingly different ways, with only the Emirati annotator correctly identifying it. Some others described it as a different dessert or even as chocolate pudding. It is a known fact that recognition depends on cultural familiarity, and AI systems face these problems at scale. A model trained on huge volumes of text and images may still fail when an object, setting, or custom sits outside the regions that dominate its training data.

Results-wise, GPT-4o performed best overall, which is consistent with what many researchers would expect from a frontier multimodal model. But even GPT-4o shows notable weakness on semantic grounding and struggles with dialectal authenticity. Its performance also dips on the Emirati portion of JEEM, which the authors frame as evidence that lower-resource dialects remain harder for current systems. The open Arabic models fare worse still. Some can produce reasonably fluent output, but they often miss the meaning of the scene or fail to express it naturally in the target dialect.
Beyond benchmark performance
Multimodal AI is increasingly sold as a universal interface, something that can describe, retrieve, answer, assist, and reason across languages and contexts. But universality is easy to claim when the benchmarks are culturally narrow, translation-heavy, or centered on standard language varieties. JEEM should be a reminder that generalization is not just a matter of adding more languages to a leaderboard but also about whether a model can map visual cues to the right social meanings, and do so in forms of language that people actually speak.
In the paper, the authors also do not rely on a single evaluation scheme. They combine standard automatic metrics with GPT-4-based evaluation and human judgments. That is a sensible choice because captioning and visual question answering in dialectal Arabic are exactly the kinds of tasks where simple overlap metrics can miss the point. In morphologically rich, regionally varied language settings, surface similarity is a poor stand-in for understanding. The paper’s broader evaluation setup reflects a growing recognition in AI research that culturally grounded tasks need more than the usual scoring shortcuts.
The implication for anyone building multilingual AI products is that it is no longer enough to say that a model supports Arabic, or even that it supports image understanding in Arabic. Support for a language in the abstract can conceal sharp differences between standardized forms and local ones, between high-resource and low-resource dialects, and between generic object recognition and culturally situated interpretation. A system that performs well on mainstream benchmarks may still stumble in the settings that matter most to users.
JEEM does not solve that problem but it is a step in the right direction, making the problem harder to ignore. By shifting evaluation toward dialects, local imagery, and culturally loaded scenes, the paper asks a more honest question of the field: when we say a model understands the world, whose world are we talking about?
For now, the answer is still that a machine that can describe a picture is not necessarily a machine that understands what it is looking at.
- natural language processing ,
- research ,
- nlp ,
- conference ,
- EACL ,
- language ,
- culture ,
- multimodal ,
- Arabic ,
- image ,
Related

Commencement 2026: Opening the black box of AI
As AI systems grow more human-like, their internal logic remains largely hidden. MBZUAI graduate Chenxi Wang is.....
Read More
Commencement 2026: Finding the fun in AI code detection
Curiosity, collaboration, and a prolific publication output helped define Daniil Orel's MBZUAI experience as a master's student.....
- commencement ,
- Sherkala ,
- llms ,
- large language models ,
- nlp ,
- collaboration ,
- natural language processing ,
- detection ,
- Commencement 2026 ,

Keeping secrets with differential privacy
MBZUAI researchers developed DP-Fusion, a method that protects sensitive data while preserving AI output quality.
- ICLR ,
- differential privacy ,
- conference ,
- nlp ,
- privacy ,
- research ,
- natural language processing ,
- machine learning ,