
K2 Think V2: a fully sovereign reasoning model
Tuesday, January 27, 2026

By MBZUAI Institute of Foundation Models, K2 Think Team
Quick Links: Dataset – Model – Code – K2 Think – K2-V2 Technical Report
The founding ethos of the Institute of Foundation Models (IFM) at MBZUAI is exemplified through a commitment to open-source foundation model development. Today, the IFM is pleased to release its first fully sovereign reasoning model with a new version of K2 Think.
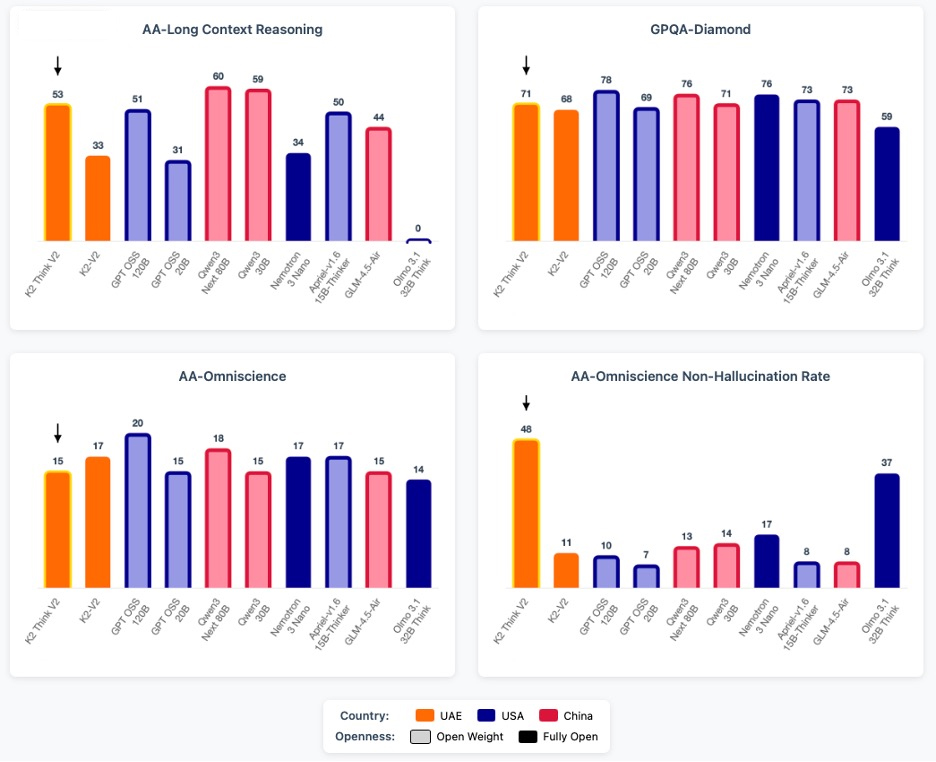
Selected benchmark comparison of Small to Medium sized Open Models, colored by country of origin. Lightly shaded bars correspond to models that are only open weight while the fully shaded bars correspond to models are fully open source. From this collection, we see that K2 Think is highly competitive with similarly sized models while also excelling in its non-hallucination rate and long context reasoning capabilities.
K2 Think is now a 70 billion parameter open-source general reasoning model, built on top of K2 V2 Instruct, the most capable fully open source instruct model. K2 Think now delivers even better performance among many complex reasoning benchmarks, including AIME2025, HMMT, GPQA-Diamond and IFBench. With this release, our flagship reasoning model is now 100% sovereign and open from pre-training through post-training, using only IFM-curated data. These open-source efforts as well as improved performance, are closing the gap between reproducible AI owned by the community and proprietary models.
K2-V2 was especially primed for RLVR post-training through its innovative SFT phase, combining both instruction following and reasoning capabilities via specific levels of thinking. For K2 Think, we leverage the highest thinking level to take advantage of the long-context capabilities of K2-V2 for long chain-of-thought reasoning while executing a two-stage RLVR training phase.
Diving into the development of K2 Think V2.
Following the introductory release of K2 Think in September 2025, and the release of K2-V2 in December 2025, we made several improvements on our existing Guru dataset, including expanding to more domains, difficulty-based filtering based on K2-V2, and decontamination against key evaluation benchmarks.
We have expanded the STEM portion of Guru by incorporating Science questions from the Nemotron post-training dataset not used in the Instruct tuning phase of K2-V2. We inherit the strategy of the original K2 Think model, which is to approach the frontier of the key domains of Math, Code, and STEM. Data were selected mainly from these domains, carefully deduplicated from the data used for K2 V2 Instruct and fully decontaminated from downstream evaluations. We have uploaded this newly filtered and slightly expanded Guru dataset as an intermediate version (v1.5) to Huggingface.
We have trained the 70B K2 Think using the same base recipe as our initial 32B version with GRPO over two stages. All code used for training is fully available at https://github.com/LLM360/Reasoning360. This training recipe makes minor modifications to the standard algorithm by removing the KL and entropy losses as well as using asymmetric clipping of the policy ratio, setting “clip_high” to 0.28. We made two further adjustments to the training recipe of K2 Think, following our analysis of K2-V2 included in its technical report (Section 7.2).
First, we trained with a temperature of 1.2 which was assessed to be at the boundary of generation stability while providing increased diversity of rollouts. Second, we trained fully on-policy with a batch-size of 256 without any micro-batching as a means to avoid the need for off-policy corrections, which have been shown in the literature to be a cause of instabilities while training with GRPO.
For the first stage of RLVR training, we limited the maximum response length of our model to 32k tokens and training for approximately 200 steps with a batch size of 256. During the second stage of training, we expanded the context length of generated responses to 64k and continued for an additional 50 steps maintaining the same hyperparameter settings.
K2 Think, towards performant and sovereign LLM
Powered by the K2 V2 Instruct checkpoint, K2 Think is now significantly improved over its preliminary 32B version. With dedicated curation of an informative training dataset, as detailed above, and building on top of a strong foundation, we are able to substantially improve on our prior Fall 2025 release. K2 Think is extensively improved on key reasoning benchmarks across Math, Science, and Code with even further improvements from K2 V2’s already strong capability for instruction following.
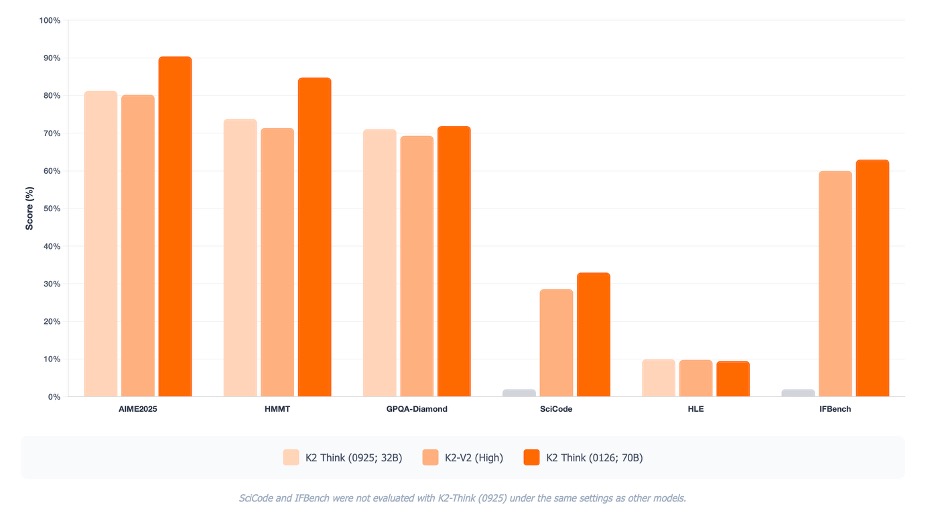
Select benchmark evaluations between K2 Think versions and K2-V2. We see that the successful training of K2-V2 brought its performance nearly to the same level of the original K2 Think. Further post-training on top of K2-V2 further improved its reasoning performance. Note: SciCode and IFBench were evaluated under the same settings or conditions for the previous version of K2 Think, to avoid inconsistent comparisons we have omitted those scores in this figure denoting their absence in gray.
Based on our internal evaluation of K2 Think, backed by the third-party Artificial Analysis evaluation, we are pleased to report that it is the strongest fully open-source reasoning model just with our initial rounds of post-training (and there are more updates to come!).
Perhaps most importantly, this new 70B parameter version of K2 Think is fully sovereign in its construction in addition to its fully open-source nature. Future advances of K2 Think will be constructed in concert with improvements made to our base models; with anticipated novel capabilities arising from the exploration of architecture, agentic tool-use and new RL recipes.
K2 Think V2, intelligent and reliable
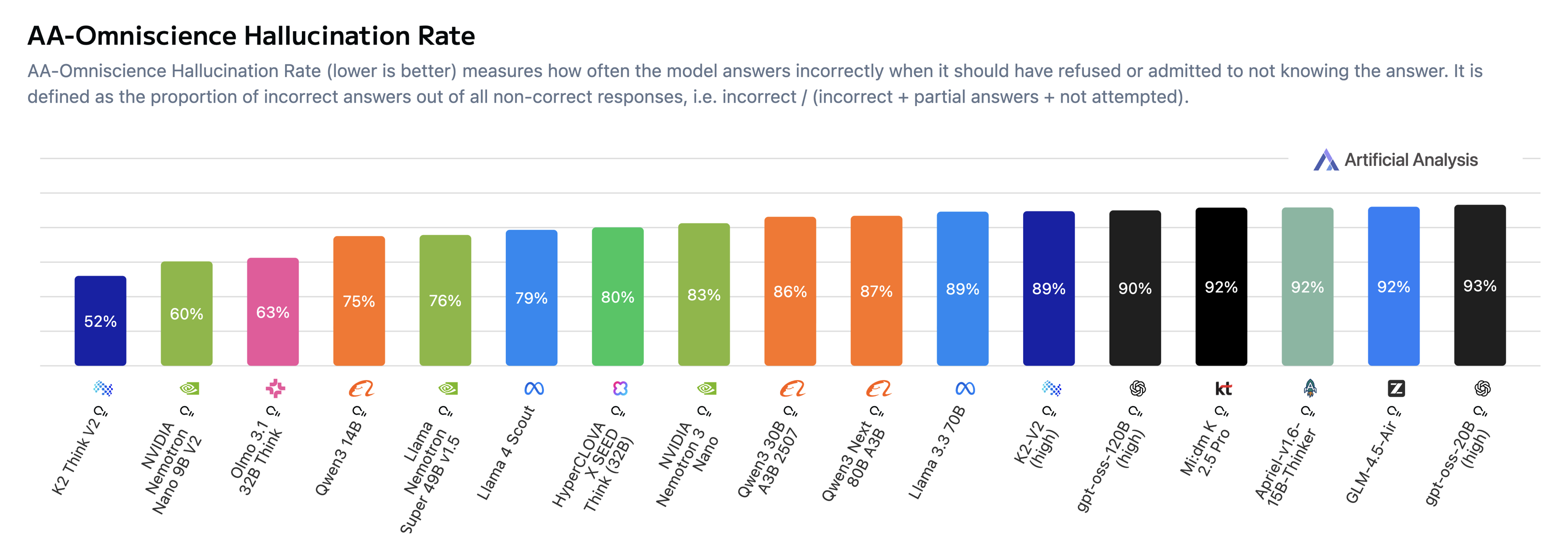
We received a third-party evaluation by Artificial Analysis to provide an independent assessment of K2 Think V2. Based on their multi-benchmark analysis, we see that RLVR post-training of K2-V2 has provided a notable improvement by 4 points. This improvement is driven largely by a significant reduction in hallucination rate (from 89% to 52%, on AA-Omniscience (shown below)) as well as a large improvement in long-context reasoning (from 33% to 53%!), building directly from the strong long context capabilities of K2-V2 (see composite figure of AA benchmark scores at the end of this section). These specific advantages of K2 Think carry significant practical implications as the model retains salient details embedded in large contexts.
Imagine you would need to make an investment decision, through multi-turn discussions or through a collection of documents, one would hope the model to effectively reason about that information without making up financial figures. K2 Think delivers the consistent reasoning and reliability required in such scenarios.
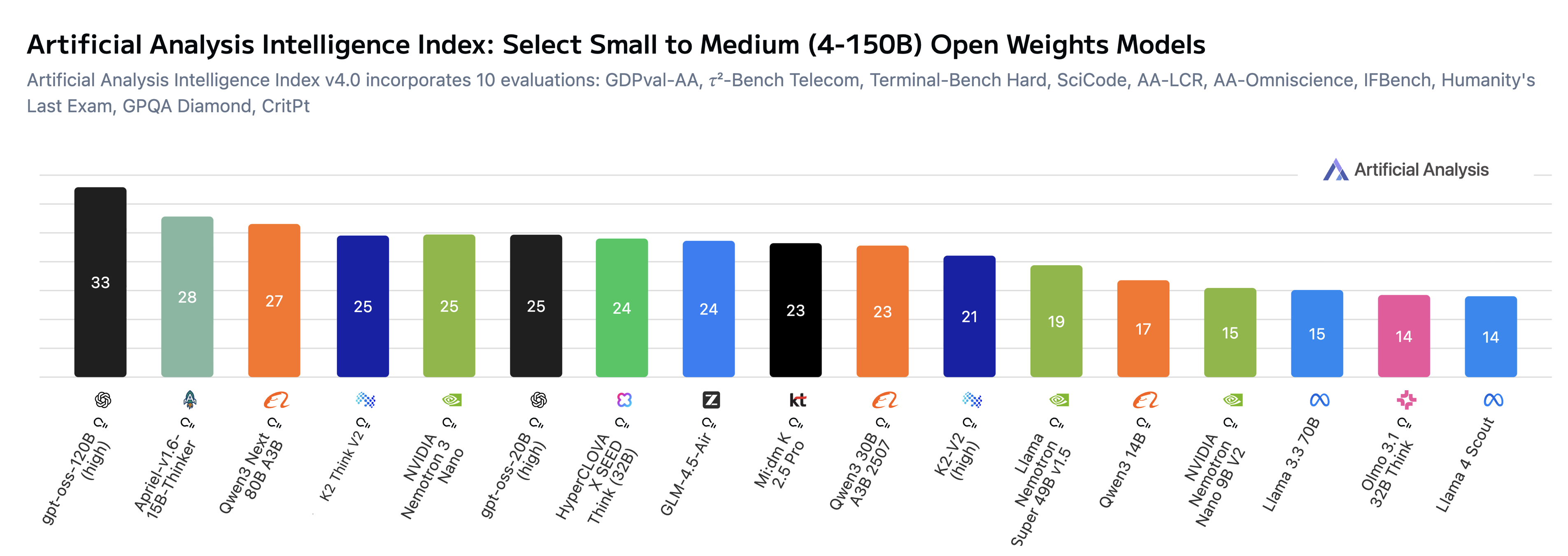
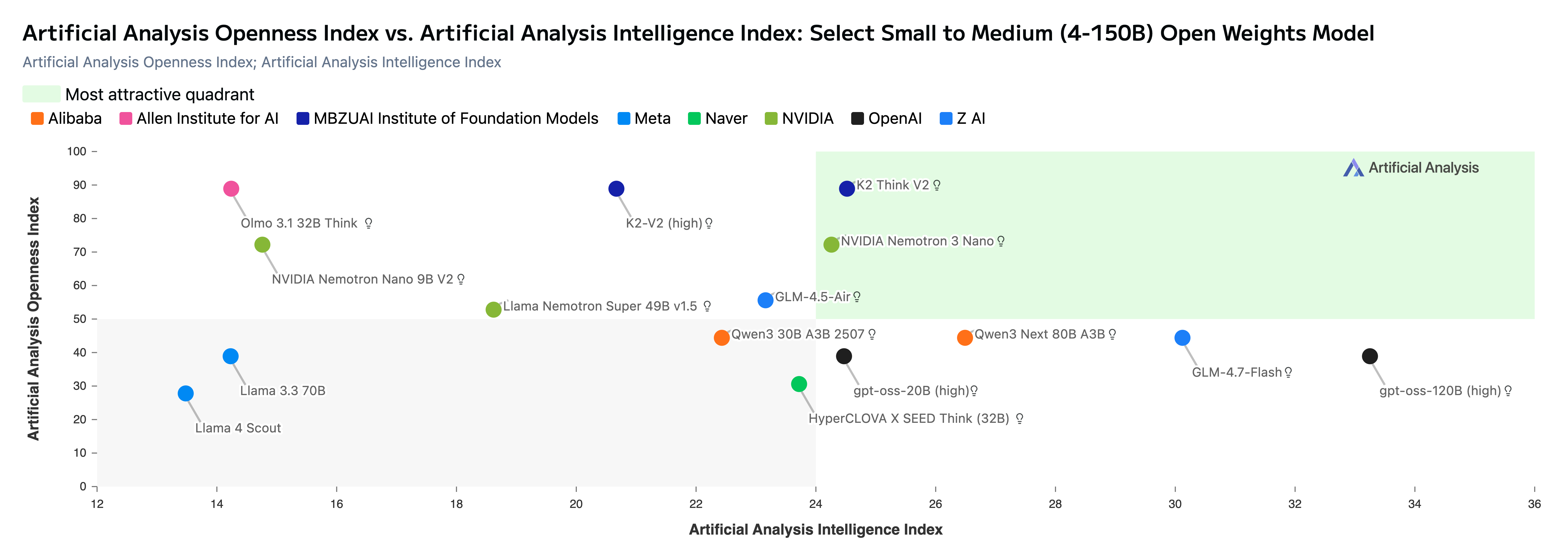
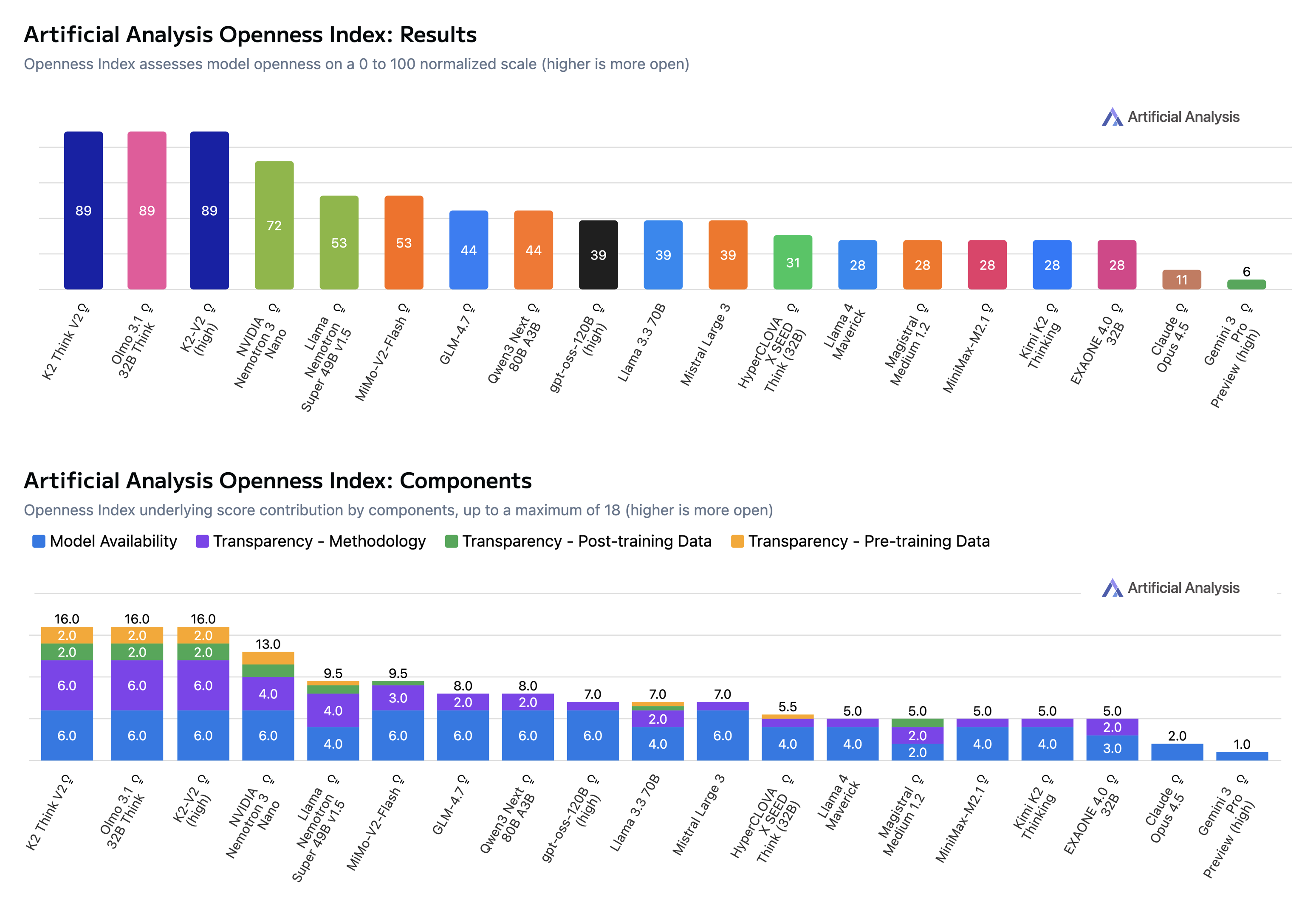
Our commitment to open source is recognized via Artificial Analysis’ “Openness Index” where K2 Think is now tied for the lead with K2-V2 and Olmo 3. With K2 Think’s improved Intelligence Index and continued fully open accessibility, our model is at the pareto frontier of open-weights reasoning models (see figure below featuring small to medium open models). The evaluations demonstrate a promising opportunity for further development of K2 Think. Currently, our model is not yet tuned to leverage tools for agentic tasks but demonstrate high potential. This is a clear point of emphasis as we seek to improve the models. We are committed to driving K2 Think toward the most generally capable reasoning system available.
Quick Links: Dataset – Model – Code – K2 Think – K2-V2 Technical Report
Safety evaluation
As a final evaluation prior to release, we rigorously assessed K2 Think’s robustness, refusal mechanisms, and vulnerability to adversarial manipulation across diverse safety domains. This safety evaluation was conducted using the `libra-eval` framework, which natively supports a wide range of safety benchmarks. In addition to general safety benchmarks, we conduct red-teaming evaluations to assess model behavior on region and culture specific aspects.
A full report of these analyses can be viewed here. These categories reflect the core safety surfaces most relevant for real-world deployment of K2 Think, covering both foundational content harms and domain-specific deployment risks. We highlight and summarize core results that are indicative of the exceptional performance of our model’s robustness and safety characteristics.
K2 Think achieves near perfect scores on standard harmful datasets, confirming strong baseline alignment provided through the innovative K2-V2 SFT phase combining both Instruction Tuning and Reasoning. Crucially, this update of K2 Think has resolved issues our previous model had with “over-refusal”. This indicates a strong semantic understanding that allows the model to safely answer extreme but harmless queries or confidently decline to answer when prudent. Compared to the high scores on the other datasets, K2 Think performs satisfactorily but there is room for improvement in physical safety and PII leakage.
Further, thanks to K2 Think’s long context abilities, K2 Think retains safety system instructions over long context windows. However, K2 Think demonstrates a major leap in technical safety capabilities with an improvement of over 66% from previous releases, successfully refusing 89.5% of exploit generation requests.
| Safety Surface | Key Constituent Domains | Safety Rate | Risk Level |
|---|---|---|---|
| Content & Public Safety | Violence, Hate, Criminal, Medical | 98.20% | Low |
| Truthfulness & Reliability | Misinformation, Deception | 97.98% | Low |
| Societal Alignment | Discrimination, Bias, Toxicity | 97.25% | Low |
| Data & Infrastructure | Privacy, PII, Physical Safety | 83.00% | Critical |
Altogether K2 Think establishes a robust safety baseline while effectively resolving the “alignment tax” of previous iterations without compromising helpfulness.
Future Efforts
There is mounting evidence that prolonged RL post-training provides continued benefits (see Olmo 3.1 and Intellect-3Tech Reports). We are working towards further improving K2 Think with the aim of developing the most capable general-purpose models tuned for reasoning, tool-use and agentic capabilities. We are actively curating new sources of data to facilitate these capabilities. We have a lot of exciting developments underway for 2026 and are looking forward to sharing them publicly as we continue building fully open models across all scales. Stay tuned!
Related

Beyond language: Eric Xing on the next frontier of artificial intelligence
MBZUAI President and University Professor, Eric Xing, spoke with The Washington Post about world models and how.....
- embodied intelligence ,
- world model ,
- genbio ,
- IFM ,
- PAN ,
- Eric Xing ,
- foundation models ,
- president office ,

MBZUAI launches K2 Think V2: UAE’s fully sovereign, next-generation reasoning system
The 70-billion parameter advanced reasoning system is now built on the K2-V2 base model – the Institute of.....
Read More
Eric Xing explores the ‘next phase of intelligence’ at Davos
Speaking at the World Economic Forum in Davos, MBZUAI President and University Professor Eric Xing looked ahead.....
- WEF ,
- foundation models ,
- Eric Xing ,
- intelligence ,
- panel ,
- Davos ,