
How reinforcement learning can help medical AI systems reason like a doctor
Tuesday, April 07, 2026

When a physician makes a diagnosis, it’s rare that they do so by making a single decision. They synthesize many different kinds of information, such as a patient’s medical history, lab tests, and imaging, and draw on their own training and expertise. While we don’t fully understand the complex mental processes that doctors go through when they reason about a diagnosis, doing so requires the ability to adapt to context and handle ambiguity.
This is partly what makes it difficult to teach medical reasoning to machines. Most of today’s medical AI systems are at their core classification tools. They work well for certain specific tasks, like identifying cancerous tumors in radiology images. But they aren’t able to mimic the holistic ability of a doctor to interpret different data modalities and make a diagnosis when the evidence isn’t so clear-cut.
Reinforcement learning (RL) offers a potential path forward. Rather than training a model on labeled data, RL allows a model to learn as it generates responses and receives feedback on them. RL, however, has an important limitation: it requires a clear reward signal. This isn’t a problem for math or multiple-choice questions that have one correct answer. Medical questions might have several valid answers, and they could be phrased or constructed differently depending on the context. This mismatch has limited RL’s impact in medical AI.
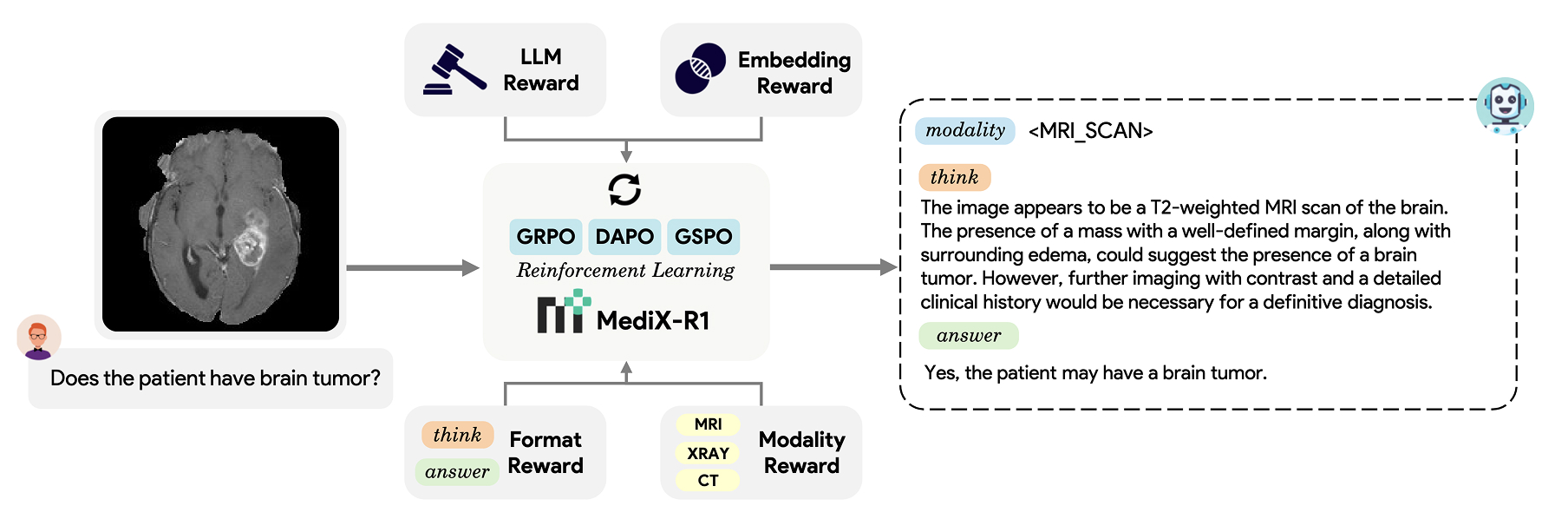
Researchers from MBZUAI and collaborating medical doctors from other institutions have recently introduced MediX-R1, a novel RL framework that can be used to fine-tune multimodal language models and improve their performance on open-ended medical question answering. MediX-R1 addresses a key limitation of standard RL frameworks by employing a reward function that is sophisticated enough to evaluate free-form clinical responses. It can be used with 16 medical imaging modalities, including X-ray, computed tomography (CT), ultrasound, and microscopy and it is compatible with commonly used RL algorithms, including GRPO, DAPO, and GSPO.
The research was recognized with a NVIDA Academic Grant 2025.
“We’ve developed a composite reward function that can work across different reinforcement-learning algorithms and shows high performance with a limited amount of training data,” explains Hisham Cholakkal, Assistant Professor of Computer Vision at MBZUAI and one of the developers of MediX-R1.
Cholakkal and his collaborators compared the performance of MediX-R1 to much larger medical models on several benchmarks and found that MediX-R1 showed strong improvements on open-ended clinical tasks and demonstrated the best average performance across 17 benchmarks. And it did so being trained on only 51 thousand instruction examples.
The researchers collaborated with physicians – Omair Mohamed and Mohammed Zidan — who helped them understand the process a physician might go through when developing a diagnosis.
Sahal Shaji Mullappilly, Mohammed Irfan Kurpath, Fahad Khan, Salman Khan, and Rao Anwer also contributed to a study about the model.
How MediX-R1 works
One of the benefits of RL is that it can help a model improve without the aid of huge amounts of human-annotated data, a significant benefit in medicine where annotated data requires the time and attention of highly trained experts.
Mullappilly, a doctoral student in computer vision at MBZUAI and a developer of MediX-R1, explains that the composite reward function allows the model to learn from a limited dataset while still producing the kind of detailed, contextually grounded answers clinical questions call for. “We’re attacking two problems at once,” he says. “We don’t need expensive annotated medical data, and we developed a model that generates informative responses for the user.”
MediX-R1 takes in a medical image and a clinical question and produces a structured response, first as a reasoning trace and then as a final answer. Training is guided by four distinct feedback signals that together make up the composite reward.
The first uses a separate language model as a judge to evaluate if the model’s answer is correct compared to the ground truth answer. The second is an embedding-based reward that measures the cosine similarity between the ground truth and the predicted response in the embedding space; responses that are similar to the ground truth answer are rewarded. Mullappilly explains that the LLM reward and the embedding reward complement each other and the synergy of the two results in improved performance.
When they only used one reward, the researchers observed reward hacking, where the model simply tried to maximize rewards instead of producing useful answers. “When we combined both of these rewards,” Mullappilly says, “our model actually started to learn.”
The third feedback signal enforces the output structure, ensuring that the model always separates its reasoning from its conclusion.
The fourth requires the model to identify the imaging modality before it begins reasoning, grounding its analysis in the right context. Kurpath, a doctoral student in computer vision and co-developer of MediX-R1, says that forcing the model to predict the modality helps to improve performance, because without it, the model could confuse CT scans with magnetic resonance imaging (MRI) or another modality. “The images may look similar, and the details may be minute, but the details are what matter most,” he says.
The modality reward also helps to break down the problem, so that if the model encounters a CT scan, it knows that it should consider medical issues that relate to those kinds of images.
Architecture of MediX-R1
Results and benefits of MediX-R1
The researchers fine-tuned vision-language models of three different sizes (2B, 8B, 30B) using MediX-R1 and compared their performance to several open-source medical models across 17 benchmarks that cover text-only clinical questions and image-based tasks.
MediX-R1 8B outperformed MedGemma 27B, Google DeepMind’s medical model, despite being roughly one-third the size and trained on a fraction of the data. MedGemma 27B was trained on more than 30 million instruction examples compared to MediX-R1’s 51 thousand.
MediX-R1 30B achieved the highest average accuracy (73.6%) of any model tested. The largest gains compared to other models were on open-ended tasks, like summarization and report generation.
Cholakkal explains that he and his collaborators were “able to get performance that matched or was better than models that were trained with many more GPUs and much more data.” The takeaway is that the right algorithms and methods can be used to train a capable medical LLM without a huge amount of compute and expertly annotated data, he says.
The two-billion parameter version of the model is even small enough that it can be run locally on a laptop or mobile phone.
The project is open-sourced, and the model weights, training code, evaluation framework, and datasets are available on the project webpage.
- healthcare ,
- reinforcement learning ,
- medical ,
- reasoning ,
- grant ,
Related

AI researchers in Abu Dhabi are rewriting the rules of medicine across every stage of life
On World Health Day, MBZUAI showcases how artificial intelligence is transforming healthcare, from predicting Alzheimer’s years in.....
- World Health Day ,
- health ,
- AI ,
- healthcare ,

Alumni Spotlight: How Abdelrahman Shaker learned to redefine impact in AI
The MBZUAI alumnus explains how his focus has changed from papers to purpose since being awarded his.....
Read More
MBZUAI and Minerva Humanoids announce strategic research partnership to advance humanoid robotics for applications in the energy sector
The partnership will facilitate the development of next-generation humanoid robotics tailored for safety-critical industrial operations.
Read More