
Building an AI model that actually speaks Hindi
Thursday, March 26, 2026
For all the talk about global AI, large language models still tend to see the world through the English language and culture. They may support dozens of languages, but support is not the same as fluency, and fluency is not the same as cultural fit. A new paper from MBZUAI, accepted at EACL 2026, introduces a pair of open weight bilingual models built specifically for Hindi and English. The main takeaway from the paper is that multilingual AI does not improve simply by adding more data; it does so when researchers make deliberate choices about language, script, culture, and safety.
The models are called Nanda-10B and Nanda-87B and they are built by MBZUAI’s Institute of Foundation Models (IFM) in collaboration with G42 and Cerebras. On the surface, they might appear to be just another fine-tuned version of Meta’s Llama family of open weight models. Look more closely though and you’ll discover some interesting details about how the team built them. The paper argues that Hindi has been underserved not only because it has had less training data than English, but because the data and tools available for it often fail to reflect how the language is actually used.
Hindi is not one neat textual stream, it appears in formal writing in Devanagari, in Romanized form online or in code-mixed Hindi-English in chat, social media, and everyday digital life. A model that only learns one of those registers will understand only part of the language environment it is supposed to serve.
The researchers respond to this challenge in three steps. First, they build a tokenizer that extends Llama’s original vocabulary with Hindi-specific tokens. In practical terms, this means the model can break Hindi text into more natural units instead of fragmenting it inefficiently. The paper reports that this roughly halves Hindi tokenization fertility while preserving English efficiency, which is one of the clearest technical signs that the model has been adapted for bilingual use rather than merely exposed to more Hindi text.
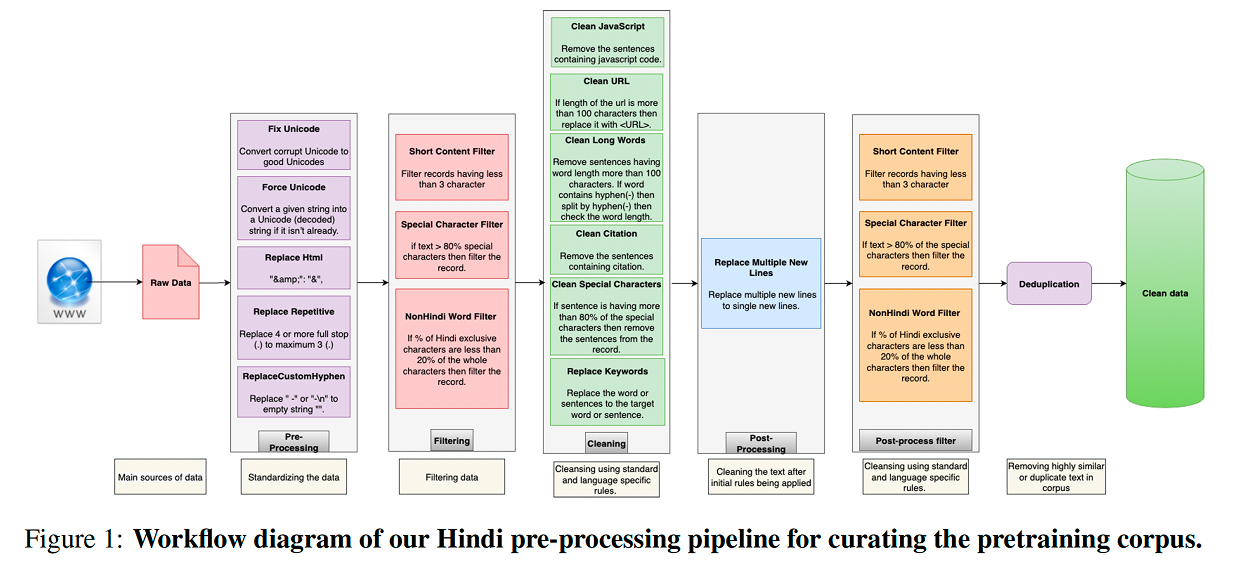
Second, they carry out Hindi-first continual pretraining on a 65 billion-token corpus designed to capture several forms of Hindi, including Devanagari, Romanized Hindi, and code-mixed text.

Third, they align the models using bilingual instruction data and a large culturally grounded safety dataset. That last piece is especially important. Many language models can be made more capable in a new language. Far fewer are trained to respond safely and appropriately in ways that reflect local linguistic and cultural context.
According to the paper, Nanda-87B outperforms comparable open-weight models on summarization, translation, transliteration, and instruction following. Nanda-10B, the smaller model, is more mixed overall, but still performs competitively and appears particularly strong relative to other sub-10B models in areas such as safety and cultural knowledge. In pairwise generative evaluation using GPT-4o as judge, both models show a clear edge in Hindi over their Llama instruction-tuned counterparts.
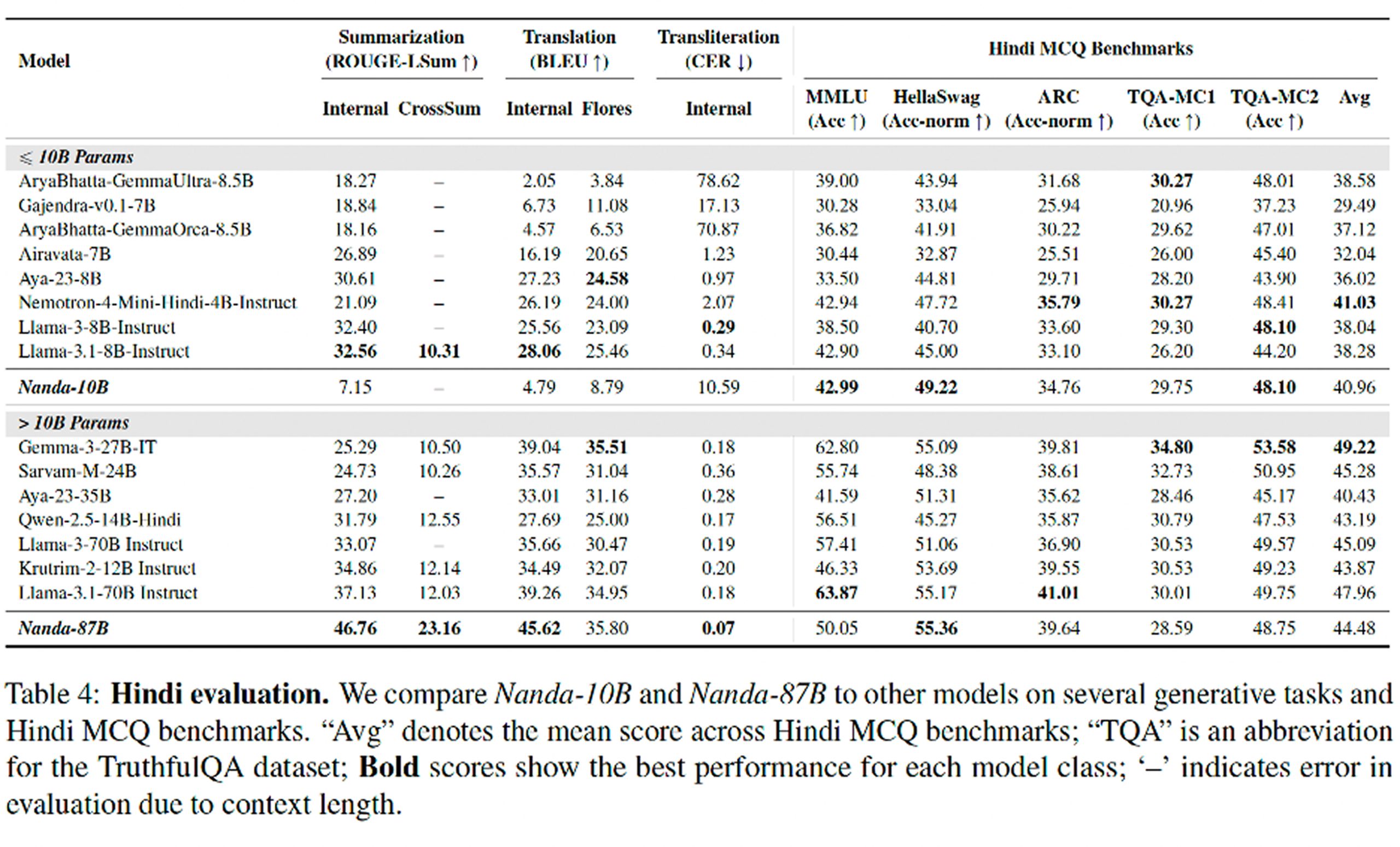
One of the paper’s more interesting subtexts is the distinction between generative performance and standard test performance. On multiple-choice benchmarks, the Nanda models are competitive, but the gap is not always dramatic. That’s because multiple-choice tests only capture part of what it means for a model to work well in a language. If the goal is to build a system that can summarize, translate, answer prompts, handle mixed language input, and do so in a way that reflects cultural context, then generative evaluation matters more than leaderboard scores.
The paper also makes an important claim about how language and culture travel together. It includes a dedicated cultural evaluation using Hindi-focused benchmarks in areas such as traditional medicine, finance, farming, and legal matters. Here too the Nanda models lead their respective size classes. That does not mean they possess culture in any deep human sense. But it does suggest that language adaptation done properly can improve a model’s handling of the background knowledge people rely on when they communicate in everyday settings.
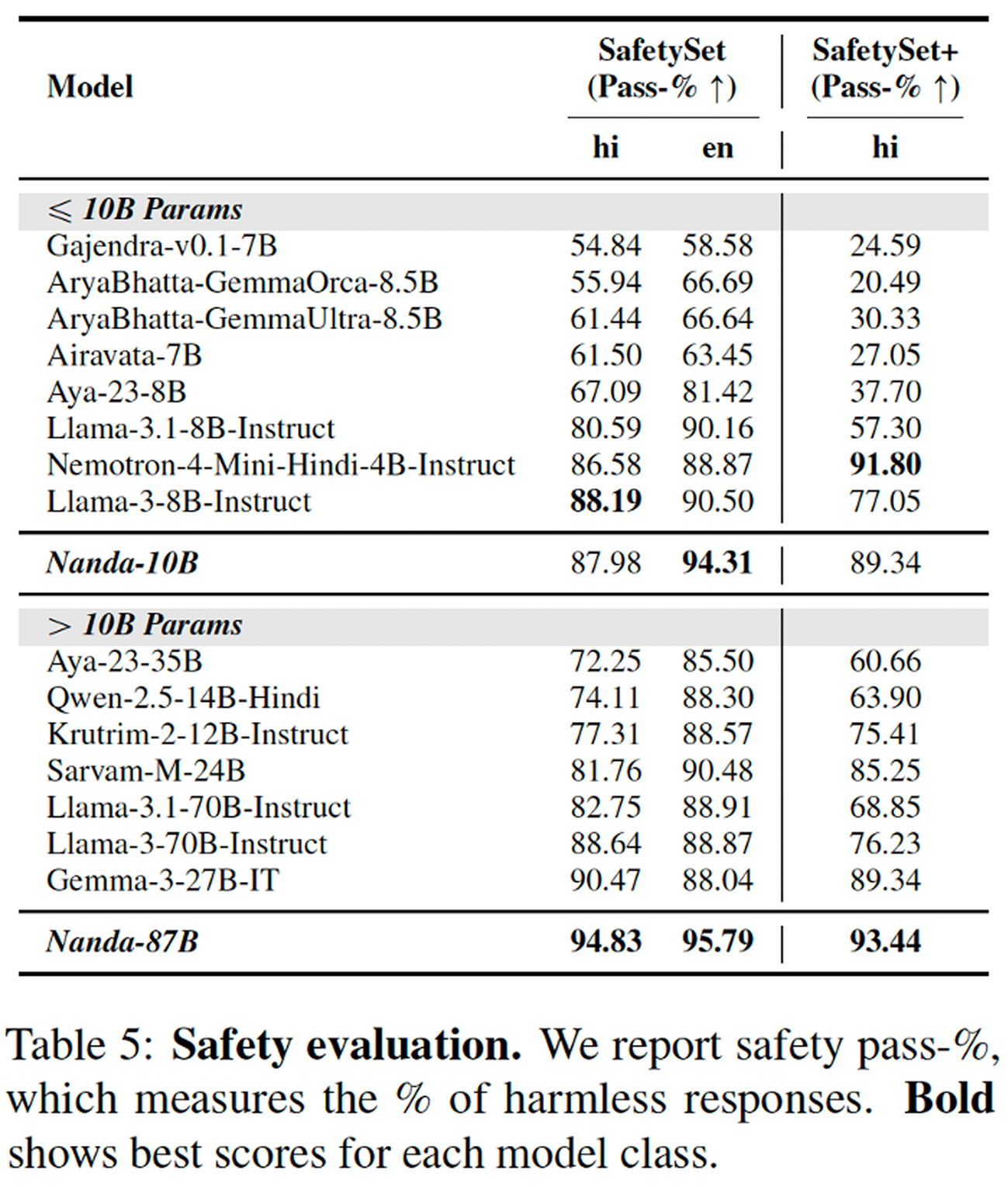
Safety is another noteworthy part of the story. The paper reports that both Nanda models achieve state-of-the-art results on the authors’ Hindi safety evaluations, including a manually crafted set of culturally sensitive prompts designed by native Hindi speakers. That is notable because lower-resource language work in AI often focuses first on competence and only later on alignment. This paper argues, implicitly and explicitly, that the two have to be built together.
The standard way to build for underrepresented languages has often been to start with an English-centric model and patch over the gap with translation, instruction tuning, or light multilingual expansion. Nanda suggests that this is not enough. If a language has different scripts, different everyday patterns, and different cultural frames, then those features have to shape the tokenizer, the training mix, the instruction data, and the safety process from the start.
The paper is careful to acknowledge remaining limits, especially around the lack of truly large-scale authentic Hindi datasets and the fact that some evaluations still rely on automatic metrics that may miss deeper questions of adequacy or cultural nuance.
Still, the message of the paper is clear. Building better models for underrepresented languages is not mainly a matter of charity, and it is not only a matter of translation. It is a technical problem, a data problem, and a cultural problem all at once. The Nanda family treats Hindi as all three. In a field that still too often mistakes multilingual coverage for multilingual understanding, that is a meaningful step forward.
- natural language processing ,
- nlp ,
- language ,
- culture ,
- IFM ,
- Institute of Foundation Models ,
- Nanda ,
- Hindi ,
Related

AI models are becoming cultural archives
MBZUAI research shows how language models encode cultural knowledge — and how unevenly they express it across.....
- culture ,
- language ,
- EACL ,
- llms ,
- conference ,
- nlp ,
- research ,
- natural language processing ,

When disagreement becomes a signal for AI models
Research from MBZUAI and Melbourne offers new metrics and training approaches that aim to better align AI.....
- labels ,
- human judgment ,
- Computational linguistics ,
- benchmark ,
- language ,
- nlp ,
- research ,

Why AI can describe an image but struggles to understand the culture inside it
A new MBZUAI paper, accepted at EACL 2026, introduces JEEM – a benchmark for evaluating how AI.....
- natural language processing ,
- image ,
- Arabic ,
- multimodal ,
- culture ,
- language ,
- EACL ,
- research ,
- conference ,
- nlp ,