
The watermark that wasn’t there
Monday, June 01, 2026

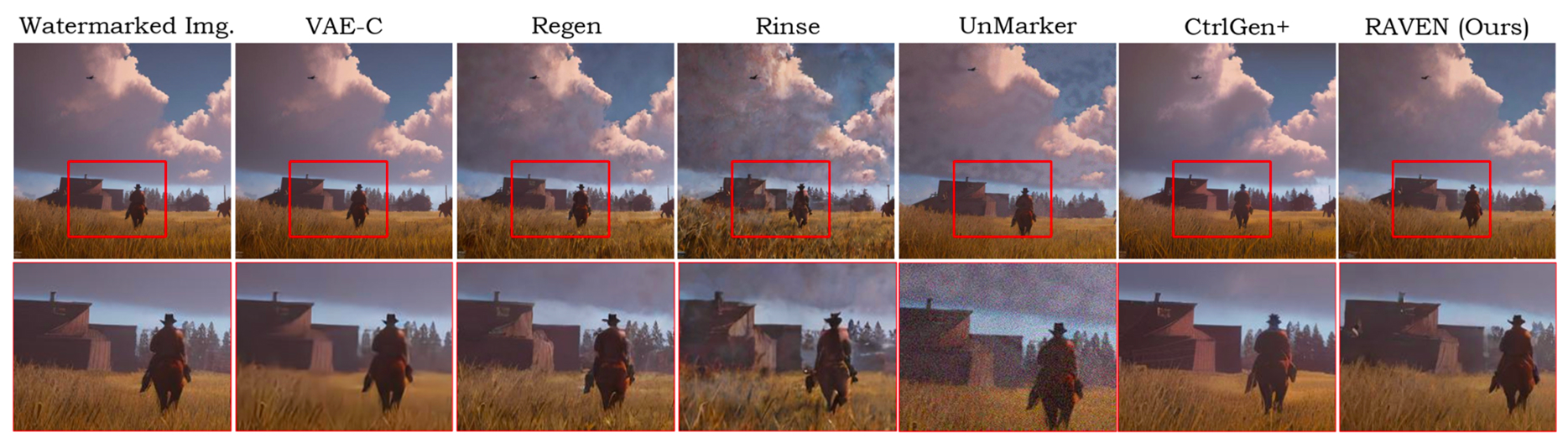
A picture of a cowboy exploring the great outdoors of the American Midwest sits next to six near-identical copies of itself. Each copy has been processed by a different algorithm meant to scrub away an invisible signal embedded in the original. Five of the copies look bad in obvious ways. One is washed out. Another is faintly noisy, as though printed on a cheap monitor. And one has the over-stylized outputs that have the hallmarks of an aggressively compressed JPEG.
But one copy – the one produced by a new method called RAVEN – is sharp, photographic, indistinguishable to the eye from the source. It also no longer carries the watermark that was supposed to prove it had been generated by a machine.
The team behind RAVEN, working out of MBZUAI and Michigan State, argues that this is not an incremental improvement on existing attacks. It is a different kind of attack altogether, and the reason it works exposes an assumption sitting underneath nearly every major watermarking scheme deployed today.
That assumption is alignment. To understand it, consider what an invisible watermark actually is. When Google’s SynthID system, now embedded in hundreds of millions of AI-generated images, marks a picture, it is not stamping the corner with a logo. It is making small, statistically structured changes to the pixels or to the underlying latent representation that a detector can later recognize by looking in exactly the right places. The signal is hidden in the precise spatial correlation between values. Move the image around, blur it, add noise, recompress it, and the detector is built to still find the pattern. That robustness is the whole point, and regulators in Brussels have created the guidelines for Article 50 of the AI Act based on the idea that watermarking can be a foundational tool for distinguishing real images from synthetic ones, encouraging major model providers to build invisible watermarking systems at scale.
The RAVEN authors noticed something the defenders did not emphasize. Watermark robustness is tested against the kinds of distortion that happen when an image moves through the internet, which is to say things like compression, cropping, noise, and color shifts. These are all transformations that operate on the same picture. What if you do not modify the picture at all, but instead render a new picture of the same scene?
In the paper, presented orally at CVPR 2026 in Denver, the researchers ask what happens if you treat the watermarked image as a starting point and then, in effect, take a small step sideways and re-photograph the scene. Not a different scene but the same one with the same composition, the same subject, the same lighting, just observed from a vantage shifted by a few centimeters. To a human, the result is indistinguishable. To a watermark detector, the spatial pattern it was trained to look for has been scrambled by the displacement, because the pattern was anchored to specific pixel locations that no longer hold the same content.
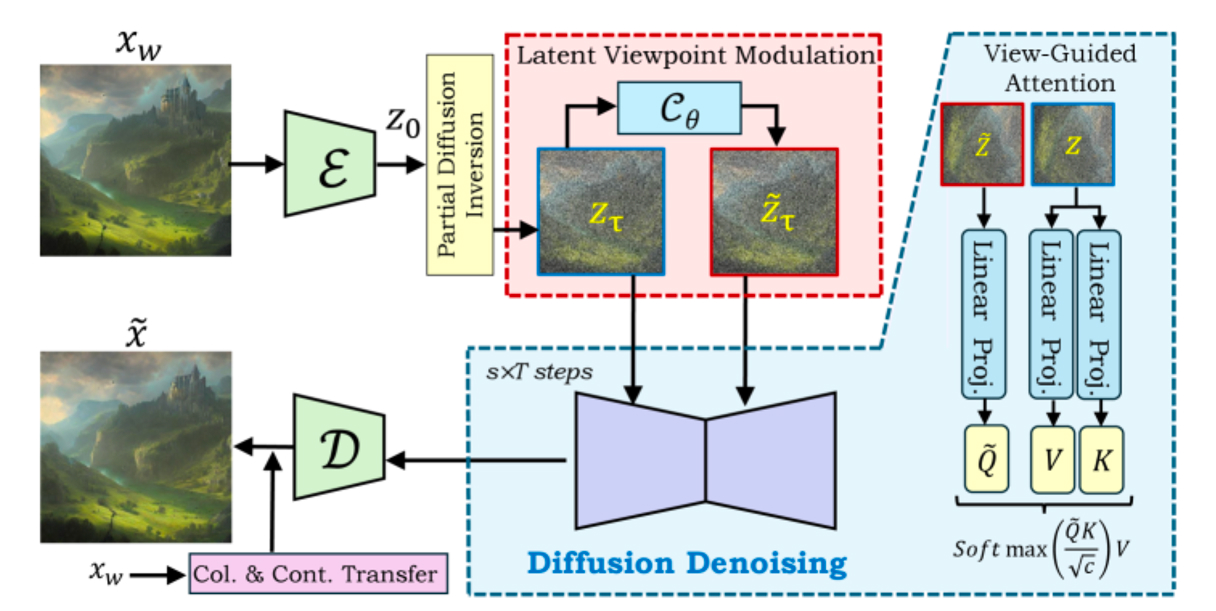
The mechanism for doing this rerendering uses a frozen, pretrained image-to-image diffusion model, the kind that has become standard infrastructure for generative work. The researchers feed the watermarked image through the model partway, just far enough to convert it into a noisy latent representation that still encodes the scene’s structure. Then they apply a small geometric translation in that latent space, the equivalent of nudging a virtual camera a few dozen pixels along a diagonal. Then they let the diffusion model finish denoising.
If you do only this, the result is recognizably the same scene but with subtle drift in color and detail, because the model is treating the shifted latent as a new image and reconstructing it from scratch. So the authors add one more piece, a modification to the model’s attention mechanism that forces the new reconstruction to keep checking back against the original. They call it view-guided correspondence attention, and the effect is to anchor texture, color, and identity to the source while allowing the geometry to drift just enough to disrupt the watermark. A final pass transfers color and contrast from the original in a perceptual color space, repairing any residual shift without restoring the watermark signal.
Across 15 watermarking schemes, including widely cited ones like Tree-Ring, Stable Signature, Gaussian Shading, and StegaStamp, RAVEN drops detection rates close to the floor of statistical guessing. On in-generation semantic watermarks, the kind built into the generative process itself, average detection falls from near-perfect to roughly 2%. On bitstream-based post-hoc watermarks, the decoded bits land near 50-50, which is what you get from random noise. The closest competitor, an attack called UnMarker that requires roughly five minutes of optimization per image, comes within reach on suppression but introduces visible artifacts that show up in image quality metrics. RAVEN takes about six seconds per image and produces outputs that score better on perceptual fidelity than nearly every baseline tested.
The implications fan out in two directions. The first one is that several specific watermarking schemes, including some used in commercial deployments and some considered state of the art in academic benchmarks, can be defeated by a publicly available diffusion model and a few seconds of compute on a single GPU. The attacker needs no access to the watermark detector, no knowledge of which watermark is being used, no paired training data, and no model parameters. The threat model is, as the authors put it, no-box. That is a sharper attacker capability than most defenders assume.
The broader implication is about what robustness even means in this context. The watermarking literature has, for years, evaluated schemes against a standard menu of distortions. JPEG, blur, crop, noise, contrast. The RAVEN paper suggests that the menu may be wrong. The relevant question is not whether a watermark survives transformations that operate on pixels, but whether it survives transformations that preserve semantic content while resampling everything underneath. Novel view synthesis happens to be one way to do that but there are likely others.
The authors do not claim that watermarking is hopeless. But if the regulatory infrastructure being built around AI-generated content presumes that watermarks function as a reliable provenance signal, and if a graduate student with a single GPU can erase those watermarks in seconds without degrading the image, then the gap between what policy assumes and what the technology delivers is wider than the policy documents suggest. Whether that gap closes depends on whether the next generation of watermarks can be designed to resist semantic resampling, and on whether anyone can prove they have done so before another paper like this one arrives.
- computer vision ,
- CVPR ,
- watermarking ,
- watermark ,
Related

How AI collaboration during training can improve reasoning
Research from MBZUAI demonstrates how collaborative training enables AI models to build stronger, more diverse reasoning abilities.
- collaborative reasoning ,
- llms ,
- icml ,
- training ,
- machine learning ,

Building AI that understands the Gulf’s climate challenges
An MBZUAI team has developed Gulf Climate Agent (GCA), an AI framework designed specifically for climate decision.....
- computer vision ,
- ACL ,
- conference ,
- climate change ,
- research ,

Foundational research in the age of AI
The inaugural Dean of MBZUAI's Computing and Mathematical Science Division, Éric Moulines, explains why fundamental research remains.....
- research ,
- computing ,
- mathematics ,
- education ,
- Dean ,