
AI models are becoming cultural archives
Wednesday, March 25, 2026

Depending on who you ask, language models are often described as prediction machines, reasoning engines, or statistical mirrors of the internet. A new paper from researchers at MBZUAI and the Technical University of Darmstadt suggests another way to think about them. They may also function as cultural archives, storing fragments of how different societies move through everyday life, even if that knowledge is buried deep inside the model and hard to inspect.
The paper sets out to pull some of that knowledge into the open. Its authors propose a way to extract what they call cultural commonsense knowledge graphs from large language models. The idea is as follows: instead of asking a model for isolated facts about a culture, the researchers try to recover chains of actions and expectations that reflect how ordinary life unfolds in a particular place.
“Our starting hypothesis is inspired by human cognition: people use culturally grounded commonsense to infer far more than what is explicitly observed – what happened before, what may come next, and how others might feel,” explains Junior Tonga, a first-year Ph.D. researcher in Natural Language Processing at MBZUAI and lead author of the study.
“We hypothesize that, because LLMs are trained on culturally situated text, they may also encode similar patterns of inference. From this perspective, we explore whether LLMs can be understood not just as text generators, but as cultural archives that preserve socially shared assumptions about causes, effects, and event trajectories.”
The researchers will present their findings at the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2026), being held in Rabat, Morocco. The study was authored by Junior Cedric Tonga, Chen Cecilia Liu, Iryna Gurevych, and Fajri Koto.
Culture is rarely a list of trivia; it is often procedural and it lives in sequences. If someone is preparing breakfast in Indonesia, planning a wedding in Egypt, or observing a religious holiday in Japan, the meaning lies not just in the objects or terms involved, but in the order of actions, the assumed next steps, and the social consequences attached to them.
Creating cultural commonsense
To capture these nuances, the team used a model from OpenAI to generate structured if-then assertions and expand them into multi-step paths. These paths link actions through relations such as what someone is likely to do next, what they need to do beforehand, or what effect an action has on others. The result is a graph of cultural commonsense that is meant to be richer than a flat store of facts and more useful for tasks that depend on sequence and context.
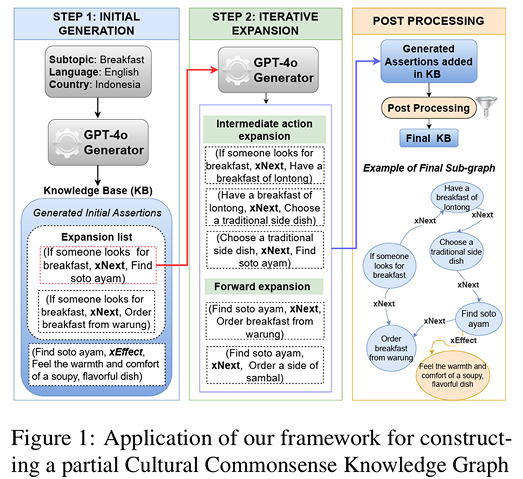
The researchers tested this idea across five countries: China, Indonesia, Japan, England, and Egypt. They built graphs both in English and in each country’s native language, then asked native-speaking annotators to judge them for correctness, cultural relevance, and logical coherence.
This is where the research becomes especially interesting. One might assume that a model would represent a culture most faithfully in that culture’s own language. The study finds something different: native-language graphs sometimes preserve richer local detail, but English often produces cleaner and more coherent cultural reasoning paths. In other words, the model may know something about a culture, but it may express that knowledge more reliably in English than in Chinese, Arabic, Japanese, or Bahasa Indonesia.
That is a useful technical insight, but it is also a revealing cultural one. It suggests that even multilingual language models still organize parts of the world through an English-centered representational layer. In other words, these systems may absorb many cultures, yet they do not necessarily absorb them evenly.
The team then asked a more practical question. If you can extract this structured cultural knowledge, does it actually help smaller models perform better? On two cultural commonsense benchmarks, one focused on the Arab world and one on Indonesia, the answer was often yes. Adding relevant assertions or paths from the graph improved performance, especially for smaller or base models that had less cultural knowledge already baked in. The gains were strongest when the added context was in the native language for question answering tasks, and path-based augmentation also helped story generation become more culturally relevant and more coherent.
That does not mean the method transforms weak models into culturally fluent ones. The improvements are meaningful, but they are not miraculous. In some cases larger instruction-tuned models gained less, which makes sense. If a model already contains more general knowledge, extra scaffolding may matter less. The paper also reports that chain-of-thought prompting usually hurts performance on these tasks, a finding consistent with prior observations and which suggests that cultural commonsense reasoning relies more on intuitive and context-dependent knowledge than on step-by-step logical reasoning.
Unreliable but important
Tonga and his co-authors describe this as a research prototype, not a production-ready cultural database. They explicitly warn that material extracted from language models can reproduce stereotypes or other distortions. That caution is central to the whole enterprise: if models are cultural archives, they are unreliable ones, shaped by uneven training data, dominant languages, and the biases of the internet itself.
Still, there is something important here. The paper offers a concrete way to study what language models know about culture beyond canned questionnaires and static fact collections. It also points toward a more grounded vision of multilingual AI, one in which systems are not judged only by whether they speak many languages, but by whether they can move through the social logic of different worlds without flattening them into generic English-language abstractions.
That is still a long way off. But this paper makes a persuasive case that the path forward will require structure, scrutiny, and a clearer understanding of how culture is actually encoded inside the models we keep calling general.
Tonga and his doctoral advisor, Professor Koto, said the study shows that LLMs appear to contain internal cultural knowledge that can be extracted in structured form. An important open question now is how this knowledge is encoded in the model’s representation space, and how future methods can better harness it to produce more culturally situated and context-aware responses.
- natural language processing ,
- research ,
- nlp ,
- conference ,
- llms ,
- EACL ,
- language ,
- culture ,
Related

Commencement 2026: Opening the black box of AI
As AI systems grow more human-like, their internal logic remains largely hidden. MBZUAI graduate Chenxi Wang is.....
Read More
Commencement 2026: Finding the fun in AI code detection
Curiosity, collaboration, and a prolific publication output helped define Daniil Orel's MBZUAI experience as a master's student.....
- commencement ,
- Sherkala ,
- llms ,
- large language models ,
- nlp ,
- collaboration ,
- natural language processing ,
- detection ,
- Commencement 2026 ,

Keeping secrets with differential privacy
MBZUAI researchers developed DP-Fusion, a method that protects sensitive data while preserving AI output quality.
- ICLR ,
- differential privacy ,
- conference ,
- nlp ,
- privacy ,
- research ,
- natural language processing ,
- machine learning ,