
K2-V2: Full Openness Finally Meets Real Performance
Thursday, December 18, 2025

The large language model (LLM) landscape — long split between proprietary Big Tech systems (Google, OpenAI), open-weight developer models (Llama), and a small set of fully open-source research models — shifted decisively in 2025.
Open-weight models are now rapidly closing the gap with frontier proprietary systems, driven in part by the rise of Chinese models such as DeepSeek, Qwen, and Kimi. These models can be freely post-trained and fine-tuned into powerful, low-cost systems, from IMO-level reasoning models to production deployments across finance, retail, healthcare, and startups. They’ve become the grassroots engine of modern AI, and almost all of them now come from China.
But there’s a catch. Developers don’t know what data, methods, or optimizations went into these models. They can’t reproduce them, audit them, or fully trust them; only consume the released weights.
Released on December 6th, K2-V2 is the newest 70B-class model in IFM’s K2 LLM series, and it’s built to change that. It matches leading open-weight performance while taking a “360-open” approach: weights, data, training details, checkpoints, and fine-tuning recipes are all public. Performance without opacity. In practice, this makes K2 the only high-performance open model in the West, and the only fully open-source alternative to the Chinese systems dominating the space.
As independent groups like ArtificialAnalysis.ai have begun evaluating K2, a clearer picture of the broader ecosystem is emerging. The AI world is now shaped by three dominant forces: enormous proprietary frontier models, fast-growing Chinese open-weight systems, and a very small handful of genuinely open-source foundations.
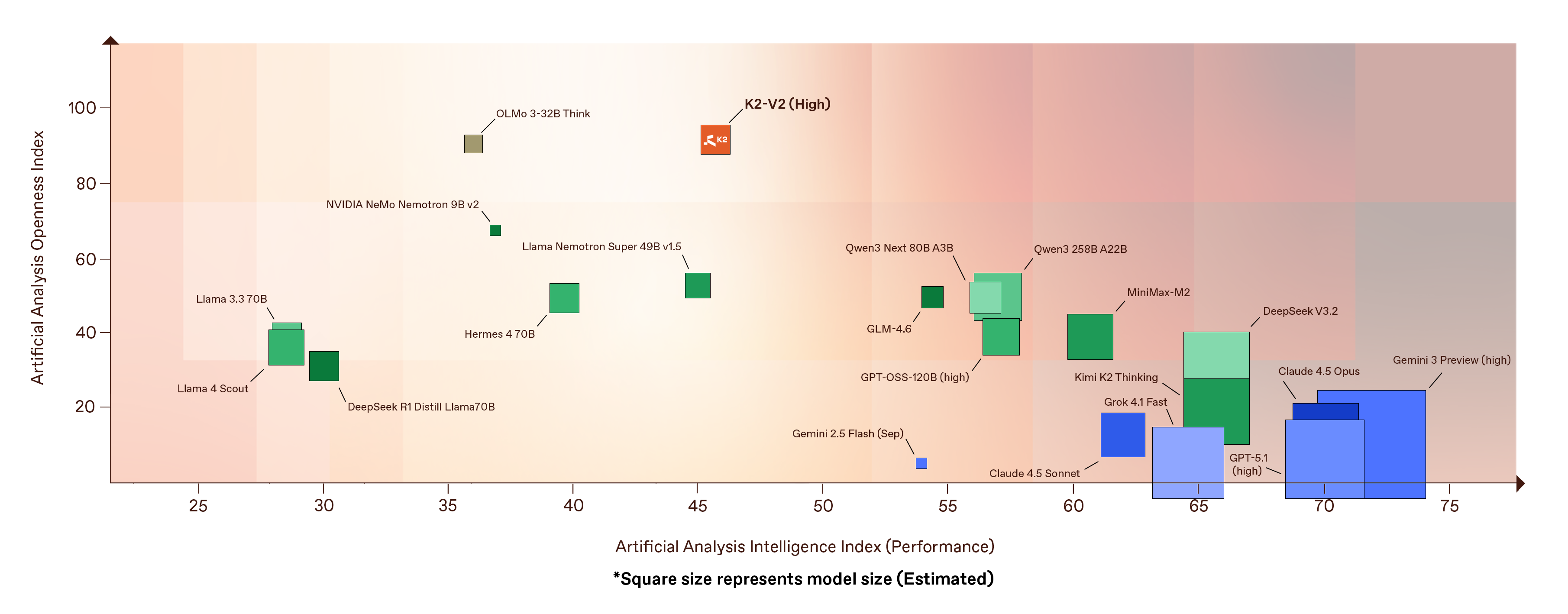
Using data from the latest leaderboard published by artificialanalysis.ai, when you place all these models onto a single map: performance on the horizontal axis, openness on the vertical, and bubble size reflecting model scale, the landscape becomes unmistakably clear. The far right of the chart is dominated by trillion-parameter proprietary systems: powerful but closed. A broad mid-band is filled with Chinese open-weight models that unlock fine-tuning and post-training flexibility, but reveal almost nothing about how they were built.
And then there’s K2. With full openness and strong performance, it’s one of the only models that actually rises toward the top of the chart. It doesn’t live with the closed frontier systems, nor in the semi-open middle; it stands apart as an open-source model that keeps its capability. It is the only fully open-source model that is both performant and reproducible.
In practical terms, that gives developers a new kind of choice. You can reach for raw performance inside a black box, or adopt a semi-open model whose origins you can’t verify. Or you can choose K2: a foundation model that is transparent end to end, lean enough for real-world deployment, and performant enough to stand beside the systems that have defined the frontier.
K2’s full training story is available on Hugging Face, and the Openness Index makes clear how uncommon that level of transparency is.
Taken together, the performance and openness results tell a clear story: K2 is not just another open model. It establishes a new benchmark for transparent development while delivering adaptable, high-quality reasoning, laying a strong foundation for the next generation of open-source AI. And this is only the beginning.
- AI ,
- artificial intelligence ,
- MBZUAI ,
- largelanguagemodel ,
- k2-v2 ,